第 4 章 bpf()系统调用
正如您在第 1 章中所看到的,当用户空间应用程序希望内核代表它们执行某项操作时,它们会使用系统调用 API 发出请求。因此,如果用户空间应用程序想将 eBPF 程序加载到内核中,必然会涉及到一些系统调用。实际上,这个系统调用是 bpf()。在本章中,我将向您展示如何使用它来加载 eBPF 程序和映射并与之交互。
值得注意的是,运行在内核中的 eBPF 代码并不使用系统调用来访问映射。系统调用接口仅供用户空间应用程序使用。相反,eBPF 程序使用辅助函数来读写映射;在前两章中,您已经看到了这方面的例子。
如果您自己去编写 eBPF 程序,很可能不会直接调用这些 bpf() 系统调用。我将在书中稍后讨论一些提供更高级抽象的库,使其更容易使用。尽管如此,这些抽象通常与您在本章中看到的底层系统调用命令直接对应。无论您使用什么库,都需要掌握底层操作——加载程序、创建和访问映射等,这些操作将在本章中介绍。
在向您展示 bpf() 系统调用的示例之前,让我们先看看 bpf() 的手册页上的说明,即 bpf() 用于“对扩展的 BPF 映射或程序执行命令”。它还告诉我们,bpf() 的函数签名如下:
int bpf(int cmd, union bpf_attr *attr, unsigned int size);
bpf() 的第一个参数 cmd 指定要执行的命令。bpf() 系统调用不仅执行一个操作——可以使用许多不同的命令来操作 eBPF 程序和映射。图 4-1 展示了一些用户空间代码可能用来加载 eBPF 程序、创建映射、将程序附加到事件以及访问映射中键值对的常见命令。
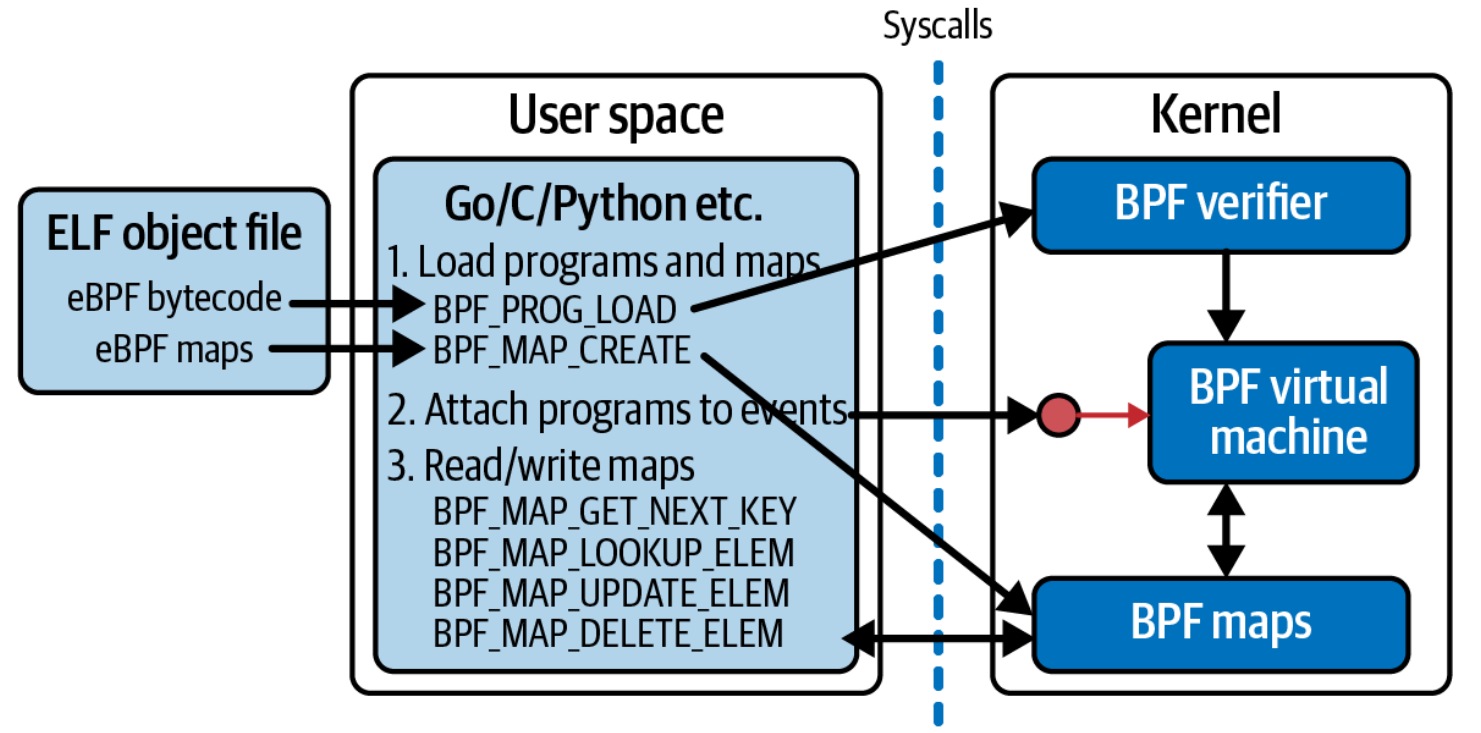
图 4-1. 用户空间程序使用系统调用与内核中的 eBPF 程序和映射进行交互
bpf() 系统调用的 attr 参数保存用于指定命令参数的必要数据,而 size 表示 attr 中数据的字节数。
您已经在第 1 章中遇到过 strace,当时我用它来展示用户空间代码如何通过系统调用 API 发出许多请求。在本章中,我将用它来演示 bpf() 系统调用的使用。strace 的输出包括每个系统调用的参数,但为了避免本章示例输出过于繁杂,除非 attr 参数中特别有趣的细节,否则我会省略大量细节。
note
您可以在 github.com/lizrice/learning-ebpf 找到代码以及运行环境的设置说明。本章的代码位于 chapter4 目录中。
在这个例子中,我将使用一个名为 hello-buffer-config.py 的 BCC 程序,该程序基于您在第 2 章中看到的示例构建。与 hello-buffer.py 示例类似,该程序每次运行时都会向 perf 缓冲区发送消息,将关于 execve() 系统调用事件的信息从内核传递到用户空间。此版本的新功能是,它允许为每个用户 ID 配置不同的消息。
以下是 eBPF 源代码:
struct user_msg_t { // 1
char message[12];
};
BPF_HASH(config, u32, struct user_msg_t); // 2
BPF_PERF_OUTPUT(output); // 3
struct data_t { // 4
int pid;
int uid;
char command[16];
char message[12];
};
int hello(void *ctx) { // 5
struct data_t data = {};
struct user_msg_t *p;
char message[12] = "Hello World";
data.pid = bpf_get_current_pid_tgid() >> 32;
data.uid = bpf_get_current_uid_gid() & 0xFFFFFFFF;
bpf_get_current_comm(&data.command, sizeof(data.command));
p = config.lookup(&data.uid); // 6
if (p != 0) {
bpf_probe_read_kernel(&data.message, sizeof(data.message), p->message);
} else {
bpf_probe_read_kernel(&data.message, sizeof(data.message), message);
}
output.perf_submit(ctx, &data, sizeof(data));
return 0;
}
- 这行代码定义了一个用于保存 12 字符长度消息的结构体
user_msg_t。 - BCC 宏
BPF_HASH用于定义一个名为config的哈希表映射。它将存储类型为user_msg_t的值,键为类型u32,该类型适用于用户 ID。(如果未指定键和值的类型,BCC 会默认将两者设置为u64。) perf缓冲区输出的定义与第 2 章完全相同。您可以将任意数据提交到缓冲区,因此无需在此处指定任何数据类型...- ...尽管实际上在此示例中程序始终提交一个
data_t结构。这与第 2 章的示例没有变化。 - 其余的大部分 eBPF 程序与您之前看到的
hello()版本相比没有变化。 - 唯一的区别是,代码使用辅助函数获取用户 ID 后,在
config哈希映射中查找以该用户 ID 为键的条目。如果找到匹配的条目,值中包含的消息将替代默认的“Hello World”。
Python 代码增加了两行:
b["config"][ct.c_int(0)] = ct.create_string_buffer(b"Hey root!")
b["config"][ct.c_int(501)] = ct.create_string_buffer(b"Hi user 501!")
它们在 config 哈希表中定义了用户 ID 0 和 501 的消息,它们对应于该虚拟机上的 root 用户 ID 和我的用户 ID。此代码使用 Python 的 ctypes 包来确保键和值的类型与 C 语言中 user_msg_t 的定义相同。
以下是这个示例的一些输出说明,以及我在第二个终端中运行的命令:
Terminal 1 Terminal 2
$ ./hello-buffer-config.py
37926 501 bash Hi user 501! ls
37927 501 bash Hi user 501! sudo ls
37929 0 sudo Hey root!
37931 501 bash Hi user 501! sudo -u daemon ls
37933 1 sudo Hello World
现在您已经了解了该程序的功能,接下来,我想向您展示它运行时使用的 bpf() 系统调用。我将使用 strace 重新运行该程序,并指定 -e bpf 来表示我只对查看 bpf() 系统调用感兴趣:
$ strace -e bpf ./hello-buffer-config.py
如果您亲自尝试,将看到几个调用此系统调用的实例。对于每个实例,您将看到指示 bpf() 系统调用应执行什么操作的命令。大致内容如下:
bpf(BPF_BTF_LOAD, ...) = 3
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_PERF_EVENT_ARRAY...) = 4
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH...) = 5
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE,...prog_name="hello",...) = 6
bpf(BPF_MAP_UPDATE_ELEM, ...}
...
让我们逐一分析这些调用。您和我都没有无限的耐心,因此我不会讨论每次调用的每个参数!我将重点关注我认为有助于讲述用户空间程序与 eBPF 程序交互时所发生事情的部分。
加载 BTF 数据
我看到的第一个 bpf() 调用如下:
bpf(BPF_BTF_LOAD, {btf="\237\353\1\0...}, 128) = 3
在此输出中,您看到的命令是 BPF_BTF_LOAD。这是(至少在撰写本文时)在内核源代码中最全面记录的一组有效命令之一1。
如果您使用的是相对较旧的 Linux 内核,可能不会看到带有此命令的调用,因为它与 BTF2(BPF Type Fromat,BPF 类型格式)有关。BTF 允许 eBPF 程序在不同的内核版本之间移植,这样您就可以在一台机器上编译程序,并在另一台可能使用不同内核版本并因此具有不同内核数据结构的机器上使用它。我将在第 5 章中对此进行更详细的讨论。
这次对 bpf() 的调用将一块 BTF 数据加载到内核中,并且 bpf() 系统调用的返回值(在我的示例中为 3)是引用该数据的文件描述符。
note
文件描述符是打开文件(或类文件对象)的标识符。如果您打开一个文件(使用 open() 或 openat() 系统调用),返回值是一个文件描述符,然后将其作为参数传递给其他系统调用,如 read() 或 write(),以执行对该文件的操作。这里的数据块并不完全是文件,但被赋予一个文件描述符作为标识符,可以用于以后的相关操作。
创建映射
接下来的 bpf() 调用创建了 perf 缓冲区映射 output:
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_PERF_EVENT_ARRAY, , key_size=4,
value_size=4, max_entries=4, ... map_name="output", ...}, 128) = 4
您可以从命令名称 BPF_MAP_CREATE 推测出此调用用于创建 eBPF 映射。可以看到,这个映射的类型是 PERF_EVENT_ARRAY,名为 output。在这个 perf 事件映射中,键和值都是 4 字节长。映射中最多可以存放 4 对键值对,这由 max_entries 字段定义;我将在本章稍后解释为什么这个映射有四个条目。返回值 4 是用于用户空间代码访问 output 映射的文件描述符。
输出中的下一个 bpf() 系统调用创建了 config 映射:
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH, key_size=4, value_size=12,
max_entries=10240... map_name="config", ...btf_fd=3,...}, 128) = 5
这个映射被定义为哈希表映射,键为 4 字节长(对应于可以用来保存用户 ID 的 32 位整数),值为 12 字节长(与 msg_t 结构的长度相匹配)。我没有指定表的大小,因此它使用了 BCC 的默认大小,拥有 10,240 个条目。
这个 bpf() 系统调用也返回了一个文件描述符 5,该描述符将用于在将来的系统调用中引用这个 config 映射。
您还可以看到字段 btf_fd=3,它告诉内核使用之前获得的 BTF 文件描述符 3。正如您将在第 5 章中看到的,BTF 信息描述了数据结构的布局,将其包含在映射定义中意味着拥有关于映射中使用的键和值类型布局的信息。这被 bpftool 等工具用于对映射转储进行美化打印,使其更易于人们理解——您在第 3 章中看到了这方面的例子。
加载程序
到目前为止,您已经看到示例程序使用系统调用将 BTF 数据加载到内核中并创建了一些 eBPF 映射。接下来,它通过以下 bpf() 系统调用将 eBPF 程序加载到内核中:
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=44,
insns=0xffffa836abe8, license="GPL", ... prog_name="hello", ...
expected_attach_type=BPF_CGROUP_INET_INGRESS, prog_btf_fd=3,...}, 128) = 6
这里有一些有趣的字段:
prog_type字段描述了程序类型,这里表示它将被附加到 kprobe。您将在第 7 章中了解更多关于程序类型的信息。insn_cnt字段表示“指令计数”。这是程序中的字节码指令的数量。- 构成这个 eBPF 程序的字节码指令在
insns字段指定的地址处的内存中保存。 - 这个程序被指定为 GPL 许可,以便它可以使用 GPL 许可的 BPF 辅助函数。
- 程序名称是
hello。 expected_attach_type为BPF_CGROUP_INET_INGRESS可能让人感到惊讶,因为它听起来像是与入站网络流量有关的东西,但您知道这个 eBPF 程序将要附加到 kprobe。实际上,expected_attach_type字段仅用于某些程序类型,而BPF_PROG_TYPE_KPROBE并不是其中之一。BPF_CGROUP_INET_INGRESS恰好是 BPF 附加类型列表中的第一个3,因此它的值为 0。prog_btf_fd字段告诉内核先前加载的 BTF 数据中的哪个块与此程序一起使用。这里的值3对应于您从BPF_BTF_LOAD系统调用返回的文件描述符(与用于config映射的 BTF 数据块相同)。
如果程序验证失败(我将在第 6 章中讨论),此系统调用将返回负值,但在这里您可以看到它返回文件描述符 6。 回顾一下,此时文件描述符的含义如表 4-1 所示。
如果程序验证失败(我将在第 6 章讨论),这个系统调用将返回一个负值,但在这里您可以看到它返回了文件描述符 6。概括来说,此时文件描述符的含义如表 4-1 所示。
表 4-1. 在运行 hello-buffer-config.py 时加载程序后的文件描述符
| 文件描述符 | 代表含义 |
|---|---|
| 3 | BTF 数据 |
| 4 | perf 缓冲区映射 output |
| 5 | 哈希表映射 config |
| 6 | eBPF 程序 hello |
从用户空间修改映射
您已经在 Python 用户空间源代码中看到了为用户 ID 为 0 的 root 用户和 ID 为 501 的用户配置特殊消息的代码行:
b["config"][ct.c_int(0)] = ct.create_string_buffer(b"Hey root!")
b["config"][ct.c_int(501)] = ct.create_string_buffer(b"Hi user 501!")
您可以看到这些条目被通过如下系统调用,在映射中定义:
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=5, key=0xffffa7842490, value=0xffffa7a2b410, flags=BPF_ANY}, 128) = 0
BPF_MAP_UPDATE_ELEM 命令用于更新映射中的键值对。BPF_ANY 标志表示如果该键在映射中不存在,则应创建它。这里有两次这样的调用,分别对应于为两个不同用户 ID 配置的两个条目。
map_fd 字段用于标识正在操作的映射。您可以在这看到它是 5,这是先前创建 config 映射时返回的文件描述符。
文件描述符是由内核为特定进程分配的,所以这个值 5 只对该特定用户空间进程有效,在该进程中运行着这个 Python 程序。然而,多个用户空间程序(以及内核中的多个 eBPF 程序)都可以访问相同的映射。两个访问内核中相同映射的用户空间程序可能被分配不同的文件描述符值;同样,两个用户空间程序可能对于完全不同的映射具有相同的文件描述符值。
键和值都是指针,所以无法从 strace 输出中判断键或值的数值。不过,您可以使用 bpftool 查看映射的内容,并看到类似这样的信息:
$ bpftool map dump name config
[{
"key": 0,
"value": {
"message": "Hey root!"
}
},{
"key": 501,
"value": {
"message": "Hi user 501!"
}
}
]
bpftool 是怎么知道如何格式化输出的呢?例如,它如何知道该值是一个结构体,其中包含一个名为 message 的字段,其中包含一个字符串?答案是它使用定义此 map 的 BPF_MAP_CREATE 系统调用中包含的 BTF 信息中的定义。您将在下一章中看到有关 BTF 如何传达此信息的更多详细信息。
bpftool 是怎么知道如何格式化这个输出的?例如,它是如何知道值是一个包含名为 message 字段的字符串的结构体?答案在于它使用了在定义这个映射时通过BPF_MAP_CREATE系统调用包含的 BTF(BPF Type Format)信息。在下一章中,您将了解更多关于 BTF 如何传达这些信息的细节。
您现在已经看到了用户空间如何与内核交互以加载程序和映射,并更新映射中的信息。在您到目前为止看到的系统调用序列中,程序尚未附加到任何事件。这个步骤必须执行,否则程序将永远不会被触发。
需要注意的是,不同类型的 eBPF 程序会以多种不同的方式附加到不同的事件上!在本章稍后,我将向您展示在本例中如何使用系统调用附加到 kprobe 事件上,而这个过程不涉及bpf()调用。相比之下,在本章末尾的练习中,我会展示另一个例子,说明如何通过bpf()系统调用将程序附加到原始跟踪点(raw tracepoint)事件上。
在我们深入了解这些细节之前,我想讨论当您停止运行程序时会发生什么。您会发现程序和映射会自动卸载,这是因为内核使用*引用计数(reference counts)*来跟踪它们。
BPF 程序和映射引用
您知道,使用 bpf() 系统调用将 BPF 程序加载到内核会返回一个文件描述符。在内核中,这个文件描述符是对程序的引用。发起系统调用的用户空间进程拥有这个文件描述符;当该进程退出时,文件描述符会被释放,程序的引用计数会减少。当 BPF 程序不再有任何引用时,内核会移除该程序。
当您将程序*固定(pin)*到文件系统时,会创建一个额外的引用。
固定(pinning)
您已经在第 3 章中看到了固定操作,使用了以下命令:
bpftool prog load hello.bpf.o /sys/fs/bpf/hello
note
这些固定的对象并不是持久化到磁盘上的真实文件。它们是在伪文件系统上创建的,这个文件系统的行为类似于具有目录和文件的常规基于磁盘的文件系统。但它们保存在内存中,这意味着在系统重启后它们将不会保留在原位置。
如果 bpftool 允许您加载程序而不固定它,那将毫无意义,因为当 bpftool 退出时文件描述符会被释放,并且如果引用为零,程序就会被删除,所以不会实现任何有用的功能。但是将程序固定到文件系统意味着程序有了一个额外的引用,所以程序在命令完成后仍然保持加载状态。
当 BPF 程序附加到触发它的钩子时,引用计数也会增加。这些引用计数的行为取决于 BPF 程序的类型。您将在第 7 章中了解更多关于这些程序类型的信息,但有一些与追踪相关(如 kprobes 和 tracepoints)并且总是与用户空间进程相关联;对于这些类型的 eBPF 程序,当该进程退出时,内核的引用计数会减少。在网络协议栈或 cgroups(“control group,控制组”的缩写)中附加的程序不与任何用户空间进程关联,因此即使加载它们的用户空间程序退出了,它们也会保持原位。当使用 ip link 命令加载 XDP 程序时,您已经看到了这样一个例子:
ip link set dev eth0 xdp obj hello.bpf.o sec xdp
ip 命令已经完成,没有定义固定的位置,但尽管如此,bpftool 会现实 XDP 程序已经加载到内核中:
$ bpftool prog list
…
1255: xdp name hello tag 9d0e949f89f1a82c gpl
loaded_at 2022-11-01T19:21:14+0000 uid 0
xlated 48B jited 108B memlock 4096B map_ids 612
这个程序的引用计数不为零,因为在 ip link 命令完成后 XDP 钩子的附加仍然存在。
eBPF 映射也有引用计数,当它们的引用计数降到零时,也会被清理。每个使用映射的 eBPF 程序都会增加计数,用户空间程序对映射持有的文件描述符也会增加计数。
可能的情况是,eBPF 程序的源代码可能会定义一个程序实际上并不引用的映射。假设您想要存储关于程序的一些元数据;您可以将其定义为一个全局变量,正如您在上一章中看到的,这些信息被存储在映射中。如果 eBPF 程序不对该映射执行任何操作,那么程序到映射之间不会自动产生一个引用计数。有一个 BPF(BPF_PROG_BIND_MAP)系统调用,用于将映射与程序关联起来,以便在用户空间加载程序退出并且不再持有映射的文件描述符引用时,映射不会被立即清理。
映射也可以被固定到文件系统中,用户空间程序可以通过映射的路径来获取对映射的访问。
note
Alexei Starovoitov 在他的博客文章“BPF 对象的生命周期”中很好地描述了 BPF 引用计数器和文件描述符。
创建 BPF 程序引用的另一种方式是使用 BPF 链接(link)。
BPF 链接(BPF Links)
BPF 链接为 eBPF 程序与其附加的事件之间提供了一个抽象层。BPF 链接本身可以被固定到文件系统中,这为程序创建了另一个引用。这意味着将程序加载到内核的用户空间进程可以终止,而程序仍然被加载。用户空间加载程序的文件描述符被释放,减少了程序的引用计数,但由于 BPF 链接的存在,引用计数将不为零。
如果您按照本章结尾的练习操作,您将有机会看到 BPF 链接的实际应用。现在,让我们回到 hello-buffer-config.py 使用的 bpf() 系统调用序列。
eBPF 中涉及的其他系统调用
回顾一下,到目前为止,您已经看到了 bpf() 系统调用,它将 BTF 数据、程序和映射,以及映射中的数据添加到内核。 strace 输出中接下来显示的内容与设置 perf 缓冲区有关。
note
本章其余部分将深入探讨在使用 perf 缓冲区、环形缓冲区、kprobes 和映射迭代时涉及的系统调用序列。并非所有的 eBPF 程序都需要做这些事情,所以如果您赶时间或者觉得内容过于详细,可以跳到本章总结。我不会介意的!
初始化 perf 缓冲区
您已经看到了 bpf(BPF_MAP_UPDATE_ELEM) 调用,它们向config 映射中添加条目。接下来,输出显示了一些类似以下格式的调用:
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0xffffa7842490, value=0xffffa7a2b410, flags=BPF_ANY}, 128) = 0
这些调用看起来与定义 config 映射条目的调用非常相似,只是在这种情况下,映射的文件描述符是 4,它代表 output perf 缓冲区映射。
与之前一样,键和值是指针,因此无法从 strace 输出中判断键或值的数值。我看到这个系统调用重复了四次,所有参数的值都相同,但无法知道在每次调用之间指针的值是否发生了变化。通过观察这些 BPF_MAP_UPDATE_ELEM bpf() 调用,我们对缓冲区是如何设置和使用有了一些疑问:
- 为什么有四次对
BPF_MAP_UPDATE_ELEM的调用?这与output映射创建时具有最大四个条目的事实有关吗? - 在这四个
BPF_MAP_UPDATE_ELEM实例之后,strace输出中没有出现更多的bpf()系统调用。这可能看起来有点奇怪,因为映射的存在是为了让 eBPF 程序每次被触发时都能写入数据,而您已经看到用户空间代码显示的数据。这些数据显然不是通过bpf()系统调用从映射中检索的,那么它是如何获取的呢?
您还没有看到任何证据表明 eBPF 程序是如何附加到触发它的 kprobe 事件的。为了解释所有这些问题,我需要 strace 在运行此示例时显示更多系统调用,如下所示:
$ strace -e bpf,perf_event_open,ioctl,ppoll ./hello-buffer-config.py
为了简洁起见,我将忽略与这个示例的 eBPF 功能无关的 ioctl() 调用。
附加到 Kprobe 事件
您已经看到,在 eBPF 程序 hello 加载到内核后,文件描述符 6 被分配来表示它。要将 eBPF 程序附加到一个事件上,您还需要一个代表该特定事件的文件描述符。以下是strace输出中的一行,显示了为execve() kprobe 创建文件描述符的过程:
perf_event_open({type=0x6 /* PERF_TYPE_??? */, ...},...) = 7
根据perf_event_open()系统调用的手册,它“创建了一个文件描述符,允许测量性能信息”。从输出可以看到,strace无法解释值为 6 的类型参数,但如果进一步查看手册,您会发现 Linux 如何支持性能测量单元(Performance Measurement Unit)的动态类型:
...在 /sys/bus/event_source/devices 下,每个 PMU 实例都有一个子目录。在每个子目录中都有一个类型文件,其内容是一个整数,可用于类型字段。
果然,如果您查看该目录,您会发现一个 kprobe/type 文件:
$ cat /sys/bus/event_source/devices/kprobe/type
6
从这里可以看到,对 perf_event_open() 的调用将类型设置为 6,表示这是一个 kprobe 类型的 perf 事件。
不幸的是,strace 没有输出能够明确显示 kprobe 附加到 execve() 系统调用的详细信息,但我希望这里的证据足以使您相信返回的文件描述符所代表的就是这个。
perf_event_open() 的返回码是 7,这代表了 kprobe 的 perf 事件的文件描述符,并且您知道文件描述符 6 代表的是 eBPF 程序 hello。perf_event_open() 的手册还解释了如何使用 ioctl() 在这两者之间创建关联:
PERF_EVENT_IOC_SET_BPF[...] 允许将 Berkeley Packet Filter (BPF)程序附加到现有的 kprobe 跟踪点事件。参数是之前由bpf (2)系统调用创建的 BPF 程序文件描述符。
这解释了您将在 strace 输出中看到的以下 ioctl() 系统调用,其中的参数指的是两个文件描述符:
ioctl(7, PERF_EVENT_IOC_SET_BPF, 6) = 0
还有一个 ioctl() 调用用来启动 kprobe 事件:
ioctl(7, PERF_EVENT_IOC_ENABLE, 0) = 0
有了这些,每当在这个机器上运行 execue() 时,就会触发 eBPF 程序。
设置和读取 Perf 事件
我已经提到,我看到了四个与 output perf 缓冲区相关的 bpf(BPF_MAP_UPDATE_ELEM) 调用。随着额外系统调用的跟踪,strace 输出显示了四个序列,如下所示:
perf_event_open({type=PERF_TYPE_SOFTWARE, size=0 /* PERF_ATTR_SIZE_??? */,
config=PERF_COUNT_SW_BPF_OUTPUT, ...}, -1, X, -1, PERF_FLAG_FD_CLOEXEC) = Y
ioctl(Y, PERF_EVENT_IOC_ENABLE, 0) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0xffffa7842490, value=0xffffa7a2b410, flags=BPF_ANY}, 128) = 0
在上面的输出中,我使用 X 的位置表示值 0、1、2 和 3 。查阅 perf_event_open() 系统调用的手册,您会看到这是 cpu,它前面的字段是 pid 或进程 ID。手册页中写道:
当 pid == -1 并且 cpu >= 0 时,会测量指定 CPU 上的所有进程/线程。
这一序列发生四次对应于我的笔记本电脑有四个 CPU 核心。这终于解释了为什么 "output" perf 缓冲区映射中有四个条目:每个 CPU 核心一个。这也解释了映射类型名称 BPF_MAP_TYPE_PERF_EVENT_ARRAY 中的 “array” 部分,因为该映射不仅仅代表一个 perf 环形缓冲区,而是一个缓冲区数组,每个核心都有一个。
如果您编写 eBPF 程序,无需担心诸如处理核心数量之类的细节,因为这会由第 10 章讨论的 eBPF 库为您处理,但我认为这是当您在此程序上使用 strace 时看到的系统调用中的一个有趣方面。
每个 perf_event_open() 调用都会返回一个文件描述符,我用 Y 表示这些值;这些值分别是 8、9、10 和 11。ioctl() 系统调用为每个文件描述符启用 perf 输出。BPF_MAP_UPDATE_ELEM bpf() 系统调用将映射条目设置为指向每个 CPU 核心的 perf 环形缓冲区,以指示它提交数据的位置。
然后,用户空间代码可以在所有这四个输出流文件描述符上使用 ppoll(),以便无论哪个核心恰好运行给定 execue() kprobe 事件的 eBPF 程序 hello,它都可以获得数据输出。以下是 ppoll() 的系统调用:
ppoll([{fd=8, events=POLLIN}, {fd=9, events=POLLIN}, {fd=10, events=POLLIN},
{fd=11, events=POLLIN}], 4, NULL, NULL, 0) = 1 ([{fd=8, revents=POLLIN}])
如您亲自尝试运行示例程序,您将会看到,这些 ppoll() 调用会阻塞,直到有一个文件描述符中有东西可读。在触发 execve() 之前,您不会在屏幕上看到返回值,而触发 execve() 后,eBPF 程序会写入数据,用户空间通过这个 ppoll() 调用检索这些数据。
在第 2 章中我提到,如果您有一个版本为 5.8 或以上的内核,BPF 环形缓冲区现在比 perf 缓冲区更受欢迎4。让我们看一下同一个示例代码的修改版,它使用了环形缓冲区。
环形缓冲区
正如内核文档中所讨论的,环形缓冲区之所以优于 perf 缓冲区,部分原因是性能优化,同时还能确保数据顺序得以保留,即便数据是由不同的 CPU 核心提交的。所有核心共享同一个缓冲区。
将 hello-buffer-config.py 转换为使用环形缓冲区不需要太多更改。在附带的 GitHub 仓库中,您会在 chapter4/hello-ring-buffer-config.py 中找到这个示例。表 4-2 展示了差异。
表 4-2. 使用 perf 缓冲区和环形缓冲区的示例 BCC 代码之间的差异
| hello-buffer-config.py | hello-ring-buffer-config.py |
|---|---|
BPF_PERF_OUTPUT(output); | BPF_RINGBUF_OUTPUT(output, 1); |
output.perf_submit(ctx, &data, sizeof(data)); | output.ringbuf_output(&data, sizeof(data), 0); |
b["output"].open_perf_buffer(print_event) | b["output"].open_ring_buffer(print_event) |
b.perf_buffer_poll() | b.ring_buffer_poll() |
如您所预期的,由于这些更改仅与输出缓冲区有关,因此与加载程序、config 映射以及将程序附加到 kprobe 事件相关的系统调用都保持不变。
创建 output 环形缓冲区映射的 bpf() 系统调用如下所示:
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_RINGBUF, key_size=0, value_size=0,
max_entries=4096, ... map_name="output", ...}, 128) = 4
strace 输出的主要区别在于,没有观察到在设置 perf 缓冲区时出现的四个不同的 perf_event_open()、ioctl() 和 bpf(BPF_MAP_UPDATE_ELEM) 系统调用序列。对于环形缓冲区,只有一个文件描述符在所有 CPU 核心之间共享。
在撰写本文时,BCC 正在使用我在前面展示的 ppoll 机制来处理 perf 缓冲区,但它使用较新的 epoll 机制来等待环形缓冲区的数据。让我们利用这个机会来了解 ppoll 和 epoll 之间的区别。
在 perf 缓冲区示例中,我展示了 hello-buffer-config.py 生成的一个 ppoll() 系统调用,如下所示:
ppoll([{fd=8, events=POLLIN}, {fd=9, events=POLLIN}, {fd=10, events=POLLIN},
{fd=11, events=POLLIN}], 4, NULL, NULL, 0) = 1 ([{fd=8, revents=POLLIN}])
注意,这传递了文件描述符集 8、9、10 和 11,用户空间进程希望从中检索数据。每次这个轮询事件返回数据时,都必须再次调用 ppoll() 来设置相同的文件描述符集。使用 epoll 时,文件描述符集由内核对象管理。
您可以在以下序列中看到这一点,当 hello-ring-buffer-config.py 在设置对 output 环形缓冲区的访问时,会进行一系列与 epoll 相关的系统调用。
首先,用户空间程序请求在内核中创建一个新的 epoll 实例:
epoll_create1(EPOLL_CLOEXEC) = 8
这返回文件描述符 8。然后有一个对 epoll_ctl() 的调用,告诉内核将文件描述符 4(output 缓冲区)添加到 epoll 实例中的文件描述符集中:
epoll_ctl(8, EPOLL_CTL_ADD, 4, {events=EPOLLIN, data={u32=0, u64=0}}) = 0
用户空间程序使用 epoll_pwait() 等待,直到环形缓冲区中有数据可用。此调用仅在数据可用时返回:
epoll_pwait(8, [{events=EPOLLIN, data={u32=0, u64=0}}], 1, -1, NULL, 8) = 1
当然,如果您正在使用 BCC(或 libbpf,或本书后面将要介绍的任何其他库)之类的框架编写代码,您实际上不需要了解这些底层细节,比如您的用户空间应用程序是如何通过 perf 缓冲区或环形缓冲区从内核获取信息的。我希望您对了解这些工作原理的幕后一瞥感到有趣。
然而,您很可能会发现自己编写了从用户空间访问映射的代码,看看如何实现这一点的示例可能会对您有所帮助。在本章前面,我使用 bpftool 检查了 config 映射的内容。由于这是一个在用户空间运行的工具,让我们使用 strace 来查看它为了检索这些信息而进行的系统调用。
从映射中读取信息
下面的命令显示了 bpftool 在读取 config 映射内容时进行的 bpf() 系统调用的摘录:
$ strace -e bpf bpftool map dump name config
如您将看到的,该序列主要由两个步骤组成:
- 遍历所有映射,寻找名为
config的映射。 - 如果找到匹配的映射,遍历该映射中的所有元素。
查找映射
输出以一系列重复的类似调用开始,因为 bpftool 会遍历所有映射,寻找 config:
bpf(BPF_MAP_GET_NEXT_ID, {start_id=0,...}, 12) = 0 # 1
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=48...}, 12) = 3 # 2
bpf(BPF_OBJ_GET_INFO_BY_FD, {info={bpf_fd=3, ...}}, 16) = 0 # 3
bpf(BPF_MAP_GET_NEXT_ID, {start_id=48, ...}, 12) = 0 # 4
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=116, ...}, 12) = 3
bpf(BPF_OBJ_GET_INFO_BY_FD, {info={bpf_fd=3...}}, 16) = 0
BPF_MAP_GET_NEXT_ID获取指定start_id后的下一个映射的 ID。BPF_MAP_GET_FD_BY_ID返回指定映射 ID 的文件描述符。BPF_OBJ_GET_INFO_BY_FD检索文件描述符所引用对象(在本例中为映射)的信息。此信息包括名称,以便bpftool可以检查这是否是它正在查找的映射。- 重复该序列,获取步骤 1 中映射之后的下一张映射 ID。
对于每个加载到内核中的映射,都有一组这三个系统调用,并且您还会看到 start_id 和 map_id 使用的值与这些映射的 ID 匹配。当没有更多映射可供查看时,重复模式结束,此时 BPF_MAP_GET_NEXT_ID 返回一个 ENOENT 值,如下所示:
bpf(BPF_MAP_GET_NEXT_ID, {start_id=133,...}, 12) = -1 ENOENT (No such file or directory)
如果找到匹配的映射,bpftool 会保存其文件描述符,以便可以从该映射中读取元素。
读取映射中的元素
此时,bpftool 对要读取的映射有一个文件描述符引用。让我们看看读取这些信息的系统调用序列:
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=NULL, # 1
next_key=0xaaaaf7a63960}, 24) = 0
bpf(BPF_MAP_LOOKUP_ELEM, {map_fd=3, key=0xaaaaf7a63960, # 2
value=0xaaaaf7a63980, flags=BPF_ANY}, 32) = 0
[{ # 3
"key": 0,
"value": {
"message": "Hey root!"
}
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=0xaaaaf7a63960, # 4
next_key=0xaaaaf7a63960}, 24) = 0
bpf(BPF_MAP_LOOKUP_ELEM, {map_fd=3, key=0xaaaaf7a63960,
value=0xaaaaf7a63980, flags=BPF_ANY}, 32) = 0
},{
"key": 501,
"value": {
"message": "Hi user 501!"
}
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=0xaaaaf7a63960, # 5
next_key=0xaaaaf7a63960}, 24) = -1 ENOENT (No such file or directory)
} # 6
]
+++ exited with 0 +++
- 首先,应用程序需要在映射中找到一个有效的键。它通过
bpf()系统调用的BPF_MAP_GET_NEXT_KEY来实现这一点。key参数是指向键的指针,系统调用将返回这个键之后的下一个有效键。通过传入一个 NULL 指针,应用程序请求映射中的第一个有效键。内核将键写入由next_key指针指向的位置。 - 给定一个键,应用程序请求关联的值,该值将被写入由
value指向的内存位置。 - 此时,
bpftool获得了第一个键值对的内容,并将该信息写入屏幕。 - 这里,
bpftool移动到映射中的下一个键,获取它的值,并将这个键值对写到屏幕上。 - 下一次调用
BPF_MAP_GET_NEXT_KEY返回ENOENT,表示映射中没有更多的条目。 - 此处,
bpftool最终确定屏幕上的输出并退出。
请注意,此处 bpftool 被分配了文件描述符 3 ,这对应于 config 映射。这与 hello-buffer-config.py 使用文件描述符 4 引用的是同一个映射。正如我之前提到的,文件描述符是特定于进程的。
对 bpftool 行为的分析展示了用户空间程序如何遍历可用的映射以及存储在映射中的键值对。
总结
在这一章中,您看到了用户空间代码如何使用 bpf() 系统调用加载 eBPF 程序和映射。您看到了使用 BPF_PROG_LOAD 和 BPF_MAP_CREATE 命令创建程序和映射。
您了解到,内核会跟踪对 eBPF 程序和映射的引用次数,并在引用计数降到零时释放它们。您还了解了,将 BPF 对象固定到文件系统以及使用 BPF 链接创建额外引用的概念。
您看到了一个示例,演示了如何使用 BPF_MAP_UPDATE_ELEM 从用户空间在映射中创建条目。还有类似的命令——BPF_MAP_LOOKUP_ELEM 和 BPF_MAP_DELETE_ELEM 用于从映射中检索和删除值。还有一个命令 BPF_MAP_GET_NEXT_KEY,用于查找映射中存在的下一个键。您可以使用它遍历所有有效条目。
您看到了用户空间程序使用 perf_event_open() 和 ioctl() 将 eBPF 程序附加到 kprobe 事件的示例。对于其他类型的 eBPF 程序,附加方法可能非常不同,其中一些甚至使用 bpf() 系统调用。例如,有一个 bpf(BPF_PROG_ATTACH) 系统调用可以用来附加 cgroup 程序,而 bpf(BPF_RAW_TRACEPOINT_OPEN) 用于原始跟踪点(参见本章末尾的练习 5)。
我还演示了如何使用 BPF_MAP_GET_NEXT_ID、BPF_MAP_GET_FD_BY_ID 和 BPF_OBJ_GET_INFO_BY_FD 来定位内核持有的映射(和其他)对象。
本章中还有一些 bpf() 命令没有涉及,但是您在这里看到的内容足以获得一个很好的全局视图了。
您还看到了一些 BTF 数据被加载到内核中,我提到 bpftool 使用这些信息来理解数据结构的格式,以便能够漂亮地打印它们。我还没有解释 BTF 数据的样子,或者它是如何用来使 eBPF 程序跨内核版本移植的。这些内容将在下一章中介绍。
练习
如果您想进一步探索 bpf() 系统调用,可以尝试以下几件事情:
-
确认从
BPF_PROG_LOAD系统调用中获取的insn_cnt字段与使用bpftool转储该程序翻译后的 eBPF 字节码时输出的指令数量相匹配。(这在bpf()系统调用的手册上有记录) -
运行示例程序的两个实例,以便有两个名为
config的映射。如果您运行bpftool map dump name config,输出将包括关于两个不同映射及其内容的信息。在strace下运行此命令,并跟踪系统调用输出中的不同文件描述符的使用。您能否看到它在哪里检索关于映射的信息,以及它在哪里检索存储在其中的键值对? -
在运行示例程序时,使用
bpftool map update修改config映射。使用sudo -u username来检查这些配置更改是否被 eBPF 程序采取。 -
当 hello-buffer-config.py 运行时,使用
bpftool将程序固定到 BPF 文件系统,如下所示:bpftool prog pin name hello /sys/fs/bpf/hi退出正在运行的程序,并使用
bpftool prog list检查hello程序是否仍然加载在内核中。您可以使用rm /sys/fs/bpf/hi删除固定来清理链接。 -
与附加到 kprobe 相比,在系统调用级别,附加到原始跟踪点要简单得多,因为它仅涉及一个
bpf()系统调用。尝试使用 BCC 的RAW_TRACEPOINT_PROBE宏,将 hello-buffer-config.py 转换为附加到sys_enter的原始跟踪点(如果您完成了第 2 章的练习,您已经有一个合适的程序可以使用)。在 Python 代码中,您不需要显式地附加程序,因为 BCC 会为您处理。在strace下运行此程序,您应该看到一个类似于以下的系统调用:bpf(BPF_RAW_TRACEPOINT_OPEN, {raw_tracepoint={name="sys_enter", prog_fd=6}}, 128) = 7内核中的跟踪点名为
sys_enter,文件描述符为6的 eBPF 程序正附加到它。从现在开始,每当内核中的执行到达该跟踪点时,都将触发该 eBPF 程序。 -
运行 BCC 的 libbpf 工具集中的 opensnoop 应用程序。此工具设置了一些 BPF 链接,您可以使用 bpftool 查看他们,如下所示:
$ bpftool link list 116: perf_event prog 1849 bpf_cookie 0 pids opensnoop(17711) 117: perf_event prog 1851 bpf_cookie 0 pids opensnoop(17711)确认程序 ID(在我的示例输出中为 1849 和 1851)与列出已加载 eBPF 程序的输出相匹配:
$ bpftool prog list ... 1849: tracepoint name tracepoint__syscalls__sys_enter_openat tag 8ee3432dcd98ffc3 gpl run_time_ns 95875 run_cnt 121 loaded_at 2023-01-08T15:49:54+0000 uid 0 xlated 240B jited 264B memlock 4096B map_ids 571,568 btf_id 710 pids opensnoop(17711) 1851: tracepoint name tracepoint__syscalls__sys_exit_openat tag 387291c2fb839ac6 gpl run_time_ns 8515669 run_cnt 120 loaded_at 2023-01-08T15:49:54+0000 uid 0 xlated 696B jited 744B memlock 4096B map_ids 568,571,569 btf_id 710 pids opensnoop(17711) -
在 opensnoop 运行时,尝试使用
bpftool link pin id 116 /sys/fs/bpf/mylink(使用您在bpftool link list输出中看到的链接 ID 之一)来固定其中一个链接。您应该看到,即使您终止了 opensnoop,链接和相应的程序仍然在内核中保持加载状态。 -
如果您跳转到第 5 章的示例代码,您会找到一个使用 libbpf 库编写的 hello-buffer-config.py 版本。这个库会自动为加载到内核中的程序设置一个 BPF 链接。使用
strace检查它进行的bpf()系统调用,并查看bpf(BPF_LINK_CREATE)系统调用。
如果您想查看完整的 BPF 命令集,可以参考 linux/bpf.h 头文件中的文档。
BTF 是在 5.1 内核中引入的,但在一些 Linux 发行版中已被回溯移植,正如这个讨论中所展示的那样。
这些定义在 linux/bpf.h 中的 bpf_attach_type 枚举类型中。
提醒您,要了解更多信息,请阅读 Andrii Nakryiko 的“BPF 环形缓冲区”博客文章。