前言
在云原生社区及更广泛的技术领域中,eBPF 已成为近年来最热门的技术话题之一。在网络、安全、可观察性等领域,新一代强大的工具和项目正基于 eBPF 平台构建(并不断涌现)。相比从前,它们提供了更好的性能和精度。诸如 eBPF 峰会和云原生 eBPF 日等 eBPF 相关会议吸引了成千上万的与会者和观众,截至撰写本文时,eBPF Slack 社区已有超过 14,000 名成员。
为何 eBPF 被选为众多基础设施工具的底层技术?它如何实现所承诺的性能提升?eBPF 如何在从性能追踪到网络流量加密等各不相同的技术领域中发挥作用?
本书旨在解答这些问题,通过让读者了解 eBPF 的工作原理,并提供编写 eBPF 代码的入门介绍。
这本书适合谁
本书适用于对 eBPF 感兴趣并希望深入了解其工作原理的开发者、系统管理员、运维人员和学生。它为那些希望自己编写 eBPF 程序的人提供了基础。由于 eBPF 为新一代的基础设施和工具提供了卓越的平台,因此未来几年内,eBPF 开发者将可能有很好的就业机会。
即使您并不打算亲自编写 eBPF 代码,本书对您仍然有用。如果您在运维、安全或任何涉及软件基础设施的角色中工作,现在或未来几年内,您很可能会接触到基于 eBPF 的工具。了解这些工具的内部工作原理将使您能够更有效地使用它们。例如,如果您知道事件是如何触发 eBPF 程序的,您将能够更好地理解基于 eBPF 的工具在显示性能指标时究竟在测量什么。如果您是一名应用开发者,您也可能会接触到一些基于 eBPF 的工具——例如,当您进行应用性能调优时,可能会使用像 Parca 这样的工具生成火焰图,显示哪些函数耗时最多。如果您在评估安全工具,本书将帮助您理解 eBPF 的优势所在,以及如何避免以一种天真的方式使用它,导致其对攻击的防御效果降低。
即使您现在并没有使用 eBPF 工具,我也希望本书能为您提供一些有趣的见解,让您了解 Linux 的一些您可能从未考虑过的领域。大多数开发者将内核视为理所当然,因为他们使用编程语言提供的便利高级抽象,使他们能够专注于应用开发工作——这已经足够艰难了!他们使用调试器和性能分析器等工具来有效地完成工作。了解调试器或性能工具的内部工作原理可能很有趣,但并非必不可少。然而,对许多人来说,深入挖掘以了解更多是有趣且充实的1。同样,大多数人会使用 eBPF 工具,而无需关心它们是如何构建的。正如 Arthur C. Clarke 所说,“任何足够先进的技术都与魔法无异”。但就我个人而言,我喜欢深入研究,找出魔法背后的原理。您可能和我一样,觉得有必要探索 eBPF 编程,以更好地了解这项技术的潜力。如果是这样,我相信您会喜欢这本书。
本书涵盖的内容
eBPF 正以相当快的速度不断发展,这使得撰写一部不需频繁更新的全面参考书变得相当困难。然而,有些基本原理和基础原则不太可能发生显著变化,这正是本书所讨论的内容。
第 1 章为本书奠定基础,介绍了 eBPF 这项技术为何如此强大,并解释了在操作系统内核中运行自定义程序如何实现诸多令人兴奋的功能。
在第 2 章中,内容变得更具体,您将看到一些 “Hello World” 的示例,向您介绍 eBPF 程序和映射(maps)的概念。
第 3 章深入探讨 eBPF 程序及其在内核中的运行方式,而第 4 章则探讨用户空间应用程序与 eBPF 程序之间的接口。
近年来,eBPF 的一大挑战是跨内核版本的兼容性问题。第 5 章介绍了解决这一问题的“一次编译,到处运行”(compile once, run everywhere,CO-RE)方法。
验证过程也许是区分 eBPF 和内核模块的最重要特征。我将在第 6 章中向您介绍 eBPF 验证器。
在第 7 章中,您将了解许多不同类型的 eBPF 程序及其附加点(attachment points)。其中许多附加点位于网络协议栈中,第 8 章将更详细地探讨了 eBPF 在网络功能中的应用。第 9 章则探讨了 eBPF 在构建安全工具方面的应用。
如果您想编写与 eBPF 程序交互的用户空间应用程序,有许多可用的库和框架来提供帮助。第 10 章概述了各种编程语言的选项。
最后,在第 11 章,我将展望 eBPF 领域可能出现的一些未来发展。
前置知识
本书假设您对 Linux 的基本 shell 命令和使用编译器将源代码转换为可执行程序的概念感到熟悉。书中包含一些简单的 Makefile 示例,假设您至少对 make 如何使用这些文件有最基本的了解。
书中有大量的 Python、C 和 Go 语言的代码示例。您不需要深入掌握这些语言即可从示例中获益,但如果您乐于阅读一些代码,您将能从本书中获得更多收益。我还假设您熟悉指针的概念,它用来标识内存位置。
示例代码和练习
本书包含大量的代码示例。如果您希望亲自尝试这些示例,可以访问 https://github.com/lizrice/learning-ebpf 获取配套的 GitHub 仓库及安装和运行代码的说明。
我还在大多数章节的末尾附上了练习,帮助您通过扩展示例或编写自己的程序来探索 eBPF 编程。
由于 eBPF 不断发展,您可用的特性取决于您运行的内核版本。许多适用于早期版本的限制在后来的版本中已被解除或放宽。Iovisor 项目提供了不同 BPF 特性在各内核版本中添加情况的有用概述,本书中我尽量注明了所描述特性被添加的具体版本。这些示例在 5.15 版本的内核上进行了测试,但在撰写本文时,一些流行的 Linux 发行版尚未支持如此新的内核版本。如果您在本书刚出版时阅读,可能会发现某些特性在您的生产环境所用的 Linux 内核上无法运行。
eBPF 只适用于 Linux 吗?
eBPF 最初是为 Linux 开发的。实际上,这种方法完全可以应用于其他操作系统——事实上,微软已经正在开发基于 Windows 平台的 eBPF 实现。我在第 11 章简要讨论了这一点,但本书其余部分将重点关注 Linux 的实现,所有示例也都基于 Linux。
本书中使用的约定
本书中使用了以下排版约定:
-
斜体:用于表示新术语、URL、电子邮件地址、文件名和文件扩展名。
-
等宽字体:用于程序列表,以及在段落中引用程序元素,如变量或函数名、数据库、数据类型、环境变量、语句和关键字。 -
等宽粗体:显示用户应逐字输入的命令或其他文本。 -
等宽斜体:显示应由用户提供的值或由上下文确定的值。
tip
此元素表示提示或建议。
note
此元素表示一般说明。
warning
此元素表示警告或注意事项。
在2017年巴黎的dotGo会议上,我做了一场展示调试器工作原理的演讲。
第 1 章 什么是 eBPF,为何它如此重要?
eBPF 是一种革命性的内核技术,允许开发者编写自定义代码并动态加载到内核中,从而改变内核的行为。(如果您对内核的概念不太自信,不用担心——我们将在本章稍后进行介绍。)
这种技术使得新一代高性能网络、可观察性和安全工具成为可能。正如您将看到的,如果您想用这些基于 eBPF 的工具来检测应用程序,您不需要以任何方式修改或重新配置应用程序,这要归功于 eBPF 在内核中的优势地位。
使用 eBPF,您可以做的事情包括但不限于:
- 对系统几乎任何方面的性能追踪
- 高性能网络,具有内置的可见性
- 检测并(可选地)阻止恶意活动
让我们从伯克利数据包过滤器(Berkeley Packet Filter)开始,简要回顾一下 eBPF 的历史。
eBPF 的起源:伯克利数据包过滤器
我们今天所说的 "eBPF" 起源于 BSD 数据包过滤器,最早由劳伦斯伯克利国家实验室的 Steven McCanne 和 Van Jacobson 在 1993 年的一篇论文1中描述。该论文讨论了一种能够运行过滤器的伪机器,这些过滤器是用来决定是否接受或拒绝网络数据包的程序。这些程序是用 BPF 指令集编写的,这是一组通用的 32 位指令,与汇编语言非常相似。以下是直接取自该论文的一个示例:
ldh [12]
jeq #ETHERTYPE IP, L1, L2
L1: ret #TRUE
L2: ret #0
这段简短的代码过滤掉不是互联网协议(IP 协议)的数据包。该过滤器的输入是一个以太网数据包,第一条指令(ldh)从该数据包的第 12 字节开始加载一个 2 字节的值。接下来的指令(jeq)将该值与代表 IP 数据包的值进行比较。如果匹配,则执行跳转到标记为 L1 的指令,并通过返回一个非零值(这里标识为 #TRUE)来接受数据包。如果不匹配,则数据包不是 IP 数据包,通过返回 0 来拒绝该数据包。
您可以想象(或参考该论文找到示例)更复杂的过滤程序,这些程序基于数据包的其他方面做出决定。重要的是,过滤器的作者可以编写自己的自定义程序在内核中执行,而这正是 eBPF 的核心功能。
BPF 代表“Berkeley Packet Filter”,它首次引入 Linux 是在 1997 年的内核版本 2.1.75 中2,用于 tcpdump 工具中,作为一种高效的捕获数据包的方法。
时间快进到 2012 年,seccomp-bpf 在内核版本 3.5 中引入。这使得可以使用 BPF 程序来决定是否允许用户空间应用程序进行系统调用。我们将在第 10 章中详细探讨这一点。这是将 BPF 从数据包过滤的狭窄范围演变为今天的通用平台的第一步。从此之后,名称中的“数据包过滤器”一词开始变得不那么有意义!
从 BPF 到 eBPF
从 2014 年的内核 3.18 版本开始,BPF 演变为我们所说的 "extended BPF" 或 "eBPF"。这涉及到几项重大变更:
- 为了在 64 位机器上更高效的运行,BPF 指令集被彻底改造,解释器也被完全重写。
- 引入了 eBPF 映射(maps),这是可以由 BPF 程序和用户空间应用程序访问的数据结构,允许在它们之间共享信息。您将在第 2 章中了解映射。
- 添加了
bpf()系统调用,以便用户空间程序可以与内核中的 eBPF 程序进行交互。您将在第 4 章中阅读到关于这个系统调用的内容。 - 增加了几个 BPF 辅助函数。您将在第 2 章中看到一些示例,并在第 6 章中了解更多细节。
- 增加了 eBPF 验证器,以便确保 eBPF 程序可以安全运行。这将在第 6 章中讨论。
这些变化奠定了 eBPF 的基础,但发展并没有放缓!自那以后,eBPF 取得了显著的发展。
eBPF 向生产系统的演变
自 2005 年以来,Linux 内核中一直存在一种名为 kprobes(内核探针)的特性,允许在内核代码的几乎任何指令上设置陷阱(traps)。开发者可以编写内核模块,将函数附加到 kprobes 上,用于调试或性能测量3。
2015 年,添加了将 eBPF 程序附加到 kprobes 的功能,这开启了 Linux 系统中追踪方式的革命性变革。同时,内核的网络协议栈中开始添加钩子(hooks),允许 eBPF 程序处理更多的网络功能。在第 8 章中,我们将详细探讨这一点。
到 2016 年,基于 eBPF 的工具已在生产系统中使用。Brendan Gregg在 Netflix 的追踪工作在基础设施和运维领域中广为人知,他曾表示eBPF“为 Linux 带来了超能力”。同年,Cilium 项目宣布成立,这是第一个使用 eBPF 替换容器环境中整个数据路径的网络项目。
接下来的一年,Facebook(现在是 Meta)将 Katran 项目开源。Katran 是一个四层负载均衡器,满足了 Facebook 对高度可扩展和快速的解决方案的需求。自 2017 年以来,所有发送到 Facebook.com 的数据包都通过 eBPF/XDP 进行处理。(这一精彩事实来自 Daniel Borkmann 在 KubeCon 2020 上发表的题为 “eBPF 和 Kubernetes:用于扩展微服务的小助手”。)对我个人而言,这一年点燃了我对这项技术所带来可能性的兴奋,因为我在德克萨斯州奥斯汀的 DockerCon 上看到了 Thomas Graf 关于 eBPF 和 Cilium 项目的演讲。
次年,Facebook(现在是 Meta)将Katran开源。Katran 是一个四层负载均衡器,满足了 Facebook 对高度可扩展和快速解决方案的需求。自 2017 年以来,每一个访问Facebook.com的数据包都通过了 eBPF/XDP4。对我个人而言,这一年点燃了我对这种技术可能性的热情,在得克萨斯州奥斯汀的 DockerCon 上听到Thomas Graf 关于 eBPF 和 Cilium 项目的演讲后尤为如此。
2018 年,eBPF 成为 Linux 内核中的一个独立子系统,由来自 Isovalent 的Daniel Borkmann和来自 Meta 的Alexei Starovoitov担任维护者(后来同样来自 Meta 的 Andrii Nakryiko 加入了他们)。同年,引入了 BPF 类型格式(BTF),使得 eBPF 程序更具可移植性。我们将在第 5 章中探讨这一点。
2020 年引入了 LSM BPF,允许 eBPF 程序附加到 Linux 安全模块 (Linux Security Module,LSM) 内核接口。这表明 eBPF 的第三个主要用途已经确定:除了网络和可观察性之外,eBPF 还成为了安全工具的优秀平台。
多年来,得益于 300 多名内核开发者以及众多相关用户空间工具(如第 3 章中会介绍的 bpftool)、编译器和编程语言库的贡献,eBPF 的功能得到了显著提升。程序曾经被限制为 4,096 条指令,但如今这一限制已增加到 100 万条经过验证的指令5,并且通过对尾调用(tail calls)和函数调用的支持(将在第 2 章和第 3 章中看到),这一限制实际上变得无关紧要。
note
要深入了解 eBPF 的历史,最好参考那些从一开始就致力于此的维护者。
Alexei Starovoitov 曾发表过一场引人入胜的演讲,讲述了 BPF 从软件定义网络(SDN)起源的发展历程。在这次演讲中,他讨论了早期 eBPF 补丁被接受到内核中的策略,并透露 eBPF 的正式生日是 2014 年 9 月 26 日,这标志着包括验证器、BPF 系统调用和映射的第一组补丁的接受。
Daniel Borkmann 也讨论了 BPF 的历史及其支持网络和追踪功能的演变。我强烈推荐他题为“eBPF 和 Kubernetes: 用于扩展微服务的小助手”的演讲,其中充满了有趣的信息。
艰难的命名
eBPF 的应用范围已经远远超出了数据包过滤的范畴,因此这个缩写现在本质上已经失去了意义,它已经成为一个独立的术语。由于当前广泛使用的 Linux 内核都对 "extended" 部分提供支持,因此 eBPF 和 BPF 这两个术语通常可以互换使用。在内核源代码和 eBPF 编程中,常用的术语是 BPF。例如,在第 4 章中我们会看到,与 eBPF 进行交互的系统调用是bpf(),辅助函数以bpf_开头,不同类型的(e)BPF 程序以BPF_PROG_TYPE开头的名称进行标识。在内核社区之外,"eBPF"这个名称似乎已经被广泛使用,例如在社区网站 ebpf.io 上和 eBPF 基金会的名称中都使用了这个术语。
eBPF 的应用范围远远超出了数据包过滤的范畴,以至于这个缩写如今基本上没有实际意义,已经成为一个独立的术语。而且,由于目前广泛使用的 Linux 内核都支持“扩展(extended)”部分,因此 eBPF 和 BPF 的术语基本上可以互换使用。在内核源代码和 eBPF 编程中,常用的术语是 BPF。例如,正如我们将在第 4 章中看到的,与 eBPF 交互的系统调用是 bpf(),辅助函数以 bpf_ 开头,不同类型的 (e)BPF 程序以 BPF_PROG_TYPE 开头。在内核社区之外,“eBPF”这个名称似乎已经被固定下来,例如,在社区网站 ebpf.io 和 eBPF 基金会的名称中都使用了这个术语。
Linux 内核
要理解 eBPF,您需要对 Linux 中内核空间和用户空间之间的区别有深入的了解。我在我的报告“什么是 eBPF?(What Is eBPF?)”6中谈到了这一点,并将其中的一些内容进行调整,形成接下来的几个段落。
Linux 内核是应用程序与其运行的硬件之间的软件层。应用程序运行在一个称为*用户空间(user space)*的非特权层,无法直接访问硬件。相反,应用程序使用系统调用(syscall)接口请求内核代表其执行操作。硬件访问可能涉及读取和写入文件、发送或接收网络流量,甚至只是访问内存。内核还负责协调并发进程,使许多应用程序能够同时运行。如图 1-1 所示。
作为应用程序开发者,我们通常不直接使用系统调用接口,因为编程语言为我们提供了更高级的抽象和更易编程的标准库。因此,很多人对内核在我们的程序运行时所做的大量工作并不知情。如果您想了解内核被调用的频率,可以使用 strace 工具显示应用程序进行的所有系统调用。
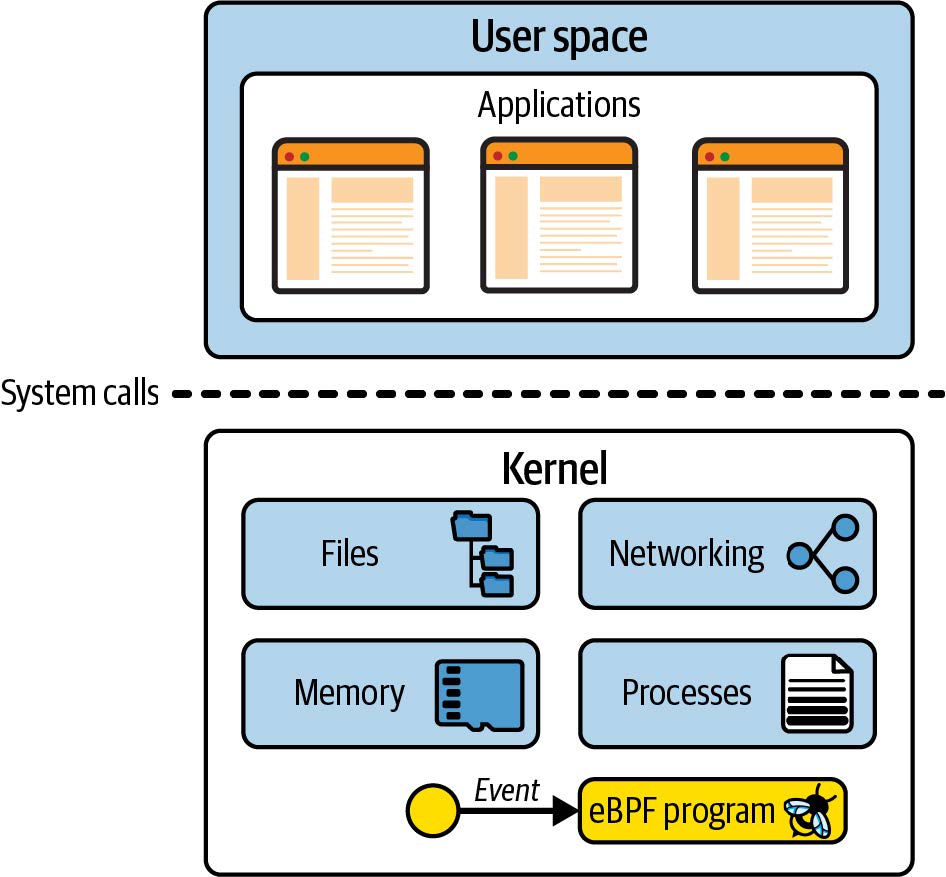
图 1-1. 用户空间中的应用程序通过系统调用接口向内核发出请求
以下是一个示例,使用 cat 命令将“hello”这个词回显到屏幕上,涉及超过 100 次系统调用:
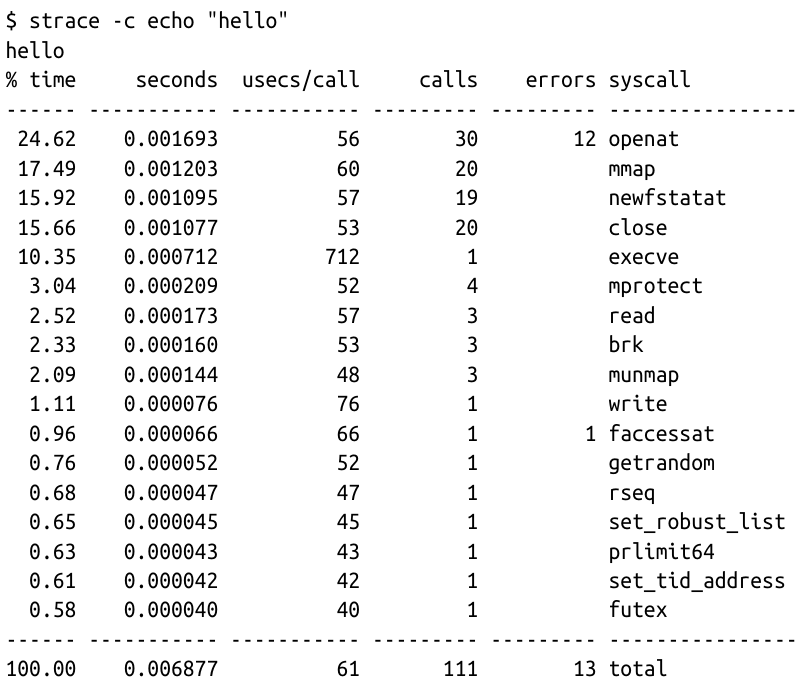
由于应用程序严重依赖内核,这意味着如果我们能够观察应用程序与内核的交互,我们可以了解很多关于应用程序行为的信息。通过 eBPF,我们可以在内核中添加检测点来获得观察能力。
例如,如果您能拦截打开文件的系统调用,您就可以准确地查看任何应用程序访问了哪些文件。但是,如何进行拦截呢?让我们考虑一下,如果我们想修改内核,添加新代码,在每次调用该系统调用时创建某种输出,会涉及到什么问题。
向内核添加新功能
Linux 内核非常复杂,截至撰写本文时,代码量大约为 3000 万行7。对任何代码库进行更改都需要对现有代码有一定的熟悉程度,因此除非您已经是内核开发者,否则这可能会是一个挑战。
此外,如果您想将您的更改贡献到上游,您将面临的不仅仅是技术挑战。Linux 是一个通用操作系统,用于各种环境和情况下。这意味着,如果您希望您的更改成为官方 Linux 版本的一部分,那就不是简单的编写代码就可以了。该代码必须被社区(更具体地说,是 Linux 的创建者 Linus Torvalds 和主要开发者)接受,认为这一更改对所有人都有益。这并不是理所当然的——提交的内核补丁中只有三分之一被接受8。
假设您已经找到了一个良好的技术方法来拦截打开文件的系统调用。经过数月的讨论和您的辛勤开发工作,假设您的更改被接受到内核中。太棒了!但这项更改何时才能到达每个人的机器上呢?
Linux 内核每两到三个月发布一个新版本,但即使某个更改被纳入这些版本中的一个,它离大多数人的生产环境中可用还有一段时间。这是因为大多数人并不直接使用 Linux 内核——我们使用的是像 Debian、Red Hat、Alpine 和 Ubuntu 这样的 Linux 发行版,这些发行版将 Linux 内核与各种其他组件一起打包。您很可能会发现您最喜欢的发行版使用的是几年前的内核版本。
例如,很多企业用户使用 Red Hat Enterprise Linux(RHEL)。截至撰写本文时,当前版本是 2021 年 11 月发布的 RHEL 8.5,它使用的是 2018 年 8 月发布的 Linux 内核版本 4.18。
正如图 1-2 中的漫画所示,从想法阶段到将新功能纳入生产环境的 Linux 内核中,需要数年的时间9。

图 1-2. 向内核添加功能(插图由 Isovalent 的 Vadim Shchekoldin 绘制)
内核模块
如果您不想等待数年才能将更改纳入内核,还有另一种选择。Linux 内核被设计允许接受内核模块(Kernel Modules),这些模块可以按需加载和卸载。如果您想更改或扩展内核行为,编写一个模块无疑是一种方法。内核模块可以独立于官方的 Linux 内核发布而进行分发,因此无需被接受到主要的上游代码库中。
这里最大的挑战在于,这仍然是完全的内核编程。用户历来对使用内核模块非常谨慎,原因很简单:如果内核代码崩溃,整台机器及其上运行的所有程序都会崩溃。用户如何确信内核模块是安全的?
“安全运行”不仅意味着不会崩溃——用户还希望知道内核模块在安全性方面是可靠的。它是否包含攻击者可以利用的漏洞?我们是否信任模块的作者不会在其中加入恶意代码?由于内核是特权代码,它可以访问机器上的所有内容,包括所有数据,因此内核中的恶意代码将是一个严重的问题。这同样适用于内核模块。
内核安全性是 Linux 发行版需要很长时间才能引入新版本的一个重要原因。如果其他人在各种情况下运行某个内核版本数月或数年,这应该已经排除了问题。发行版维护者可以相对自信地认为,他们提供给用户/客户的内核是经过*加固(hardened)*的——即安全运行的。
eBPF 提供了一种非常不同的安全方法:eBPF 验证器(eBPF verifier),确保只有在安全运行的情况下才能加载 eBPF 程序——它不会导致机器崩溃或陷入死循环,也不会允许数据被泄露。我们将在第 6 章中更详细地讨论验证过程。
eBPF 程序的动态加载
eBPF 程序可以动态地加载到内核中和从内核中移除。一旦它们被附加到某个事件上,无论是什么原因触发该事件,它们都会被触发。例如,如果您将程序附加到打开文件的系统调用上,只要任何进程尝试打开文件,该程序就会被触发。无论该进程是在程序加载时就已经运行,还是之后才运行,都无关紧要。与升级内核后需要重启机器才能使用新功能相比,这是一个巨大的优势。
这引出了使用 eBPF 的可观察性或安全工具的一个巨大优势——它可以立即获得对机器上所有活动的可见性。在运行容器的环境中,这包括对所有在这些容器内运行的进程以及主机上的进程的可见性。在本章稍后部分,我将深入探讨这对云原生部署的影响。
此外,如图 1-3 所示,人们可以通过 eBPF 非常快速地创建新的内核功能,而不需要每个 Linux 用户都接受相同的更改。

图 1-3. 使用 eBPF 添加内核功能(插图由 Isovalent 的 Vadim Shchekoldin 绘制)
eBPF 程序的高性能
eBPF 程序是一种非常高效的添加检测点的方法。在加载并进行 JIT 编译(JIT-compiled)后(第 3 章中将看到),程序将以原生机器指令在 CPU 上运行。此外,在处理事件时,无需在内核和用户空间之间进行转换(这是一项代价高昂的操作)。
2018 年描述 eXpress Data Path(XDP)的论文10中包含了一些关于 eBPF 在网络中实现性能改进的示例。例如,与常规的 Linux 内核实现相比,在 XDP 中实现路由可以“将性能提高 2.5 倍”,在负载均衡方面,“XDP 提供了比 IPVS 高 4.3 倍的性能提升”。
对于性能追踪和安全可观察性,eBPF 的另一个优势是相关事件可以在内核中被过滤掉,然后再将其发送到用户空间,从而减少了开销。毕竟,过滤特定的网络数据包正是最初 BPF 实现的目的。如今,eBPF 程序可以收集关于系统中各种事件的信息,并使用复杂的、定制的可编程过滤器,只将相关信息的子集发送到用户空间。
云原生环境中的 eBPF
如今,许多组织选择不直接在服务器上执行程序来运行应用程序。相反,许多组织采用云原生方法:容器、如 Kubernetes 或 ECS 的编排器,或无服务器方法,如 Lambda、云函数、Fargate 等。这些方法都使用自动化技术来选择每个工作负载运行的服务器;在无服务器环境中,我们甚至不知道每个工作负载在哪个服务器上运行。
尽管如此,仍然涉及服务器,每台服务器(无论是虚拟机还是裸金属机器)都运行一个内核。如果应用程序在容器中运行,那么它们在同一(虚拟)机器上运行时,共享同一个内核。在 Kubernetes 环境中,这意味着在给定节点上所有 pod 中的所有容器都使用相同的内核。当我们用 eBPF 程序对该内核进行检测时,该节点上所有容器化的工作负载对于这些 eBPF 程序都是可见的,如图 1-4 所示。
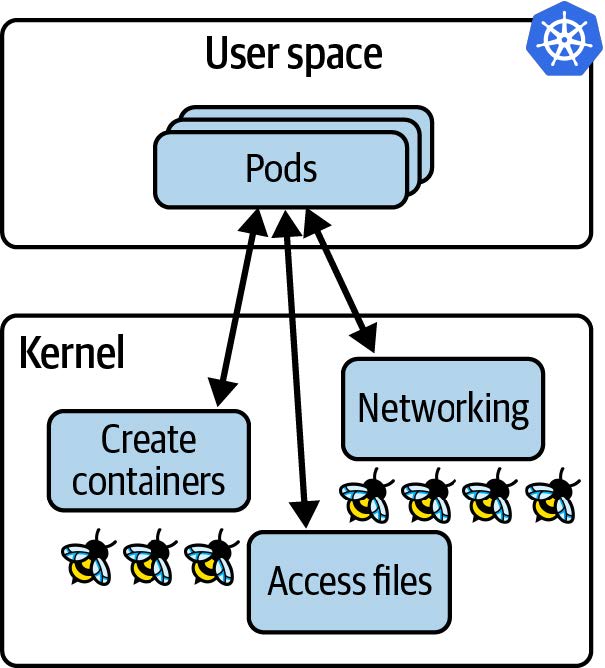
图 1-4. 内核中的 eBPF 程序可以看到在 Kubernetes 节点上运行的所有应用程序
对节点上所有进程的可见性,加上动态加载 eBPF 程序的能力,为云原生计算中的 eBPF 工具带来了真正的超能力:
- 我们无需更改应用程序,甚至不需要更改它们的配置,就可以用 eBPF 工具对应用程序进行检测。
- 一旦 eBPF 程序加载到内核并附加到一个事件上,它就可以开始观察预先存在的应用程序进程。
与之相比,Sidecar 模型已被用于向 Kubernetes 应用程序添加日志记录、追踪、安全和服务网格功能等功能。在 Sidecar 方法中,检测工具作为一个容器“注入”到每个应用程序 pod 中。该过程涉及修改定义应用程序 pod 的 YAML,添加 sidecar 容器的定义。这种方法比将检测工具添加到应用程序的源代码中(在 sidecar 方法出现之前,我们不得不这样做;例如,在我们的应用程序中包含一个日志库,并在代码的适当位置调用该库)更方便。然而,Sidecar 方法有一些缺点:
- 为了添加 Sidecar,必须重新启动应用程序 pod。
- 必须修改应用程序的 YAML。这通常是一个自动化过程,但如果出问题,Sidecar 就不会被添加,这意味着 pod 无法被检测。例如,一次部署可能会标注,来指示准入控制器将 Sidecar 的 YAML 添加到本次部署的 pod spec 中。但如果部署没有正确标注,Sidecar 就不会被添加,因此检测工具不具备可见性。
- 当一个 pod 中有多个容器时,它们可能会在不同的时间达到就绪状态,其顺序可能不可预测。注入 Sidecar 可能会显著延长 Pod 的启动时间,甚至更糟糕的是,可能会引发竞争条件或其他不稳定性问题。例如,Open Service Mesh 文档描述了应用程序容器必须能够应对所有流量在 Envoy 代理容器准备就绪之前被丢弃的情况。
- 当网络功能(如服务网格(service mesh))作为 Sidecar 实现时,这意味着所有进出应用程序容器的流量都必须通过内核中的网络协议栈到达网络代理容器,从而增加了流量的延迟;如图 1-5 所示。我们将在第 9 章讨论用 eBPF 改善网络效率的方法。
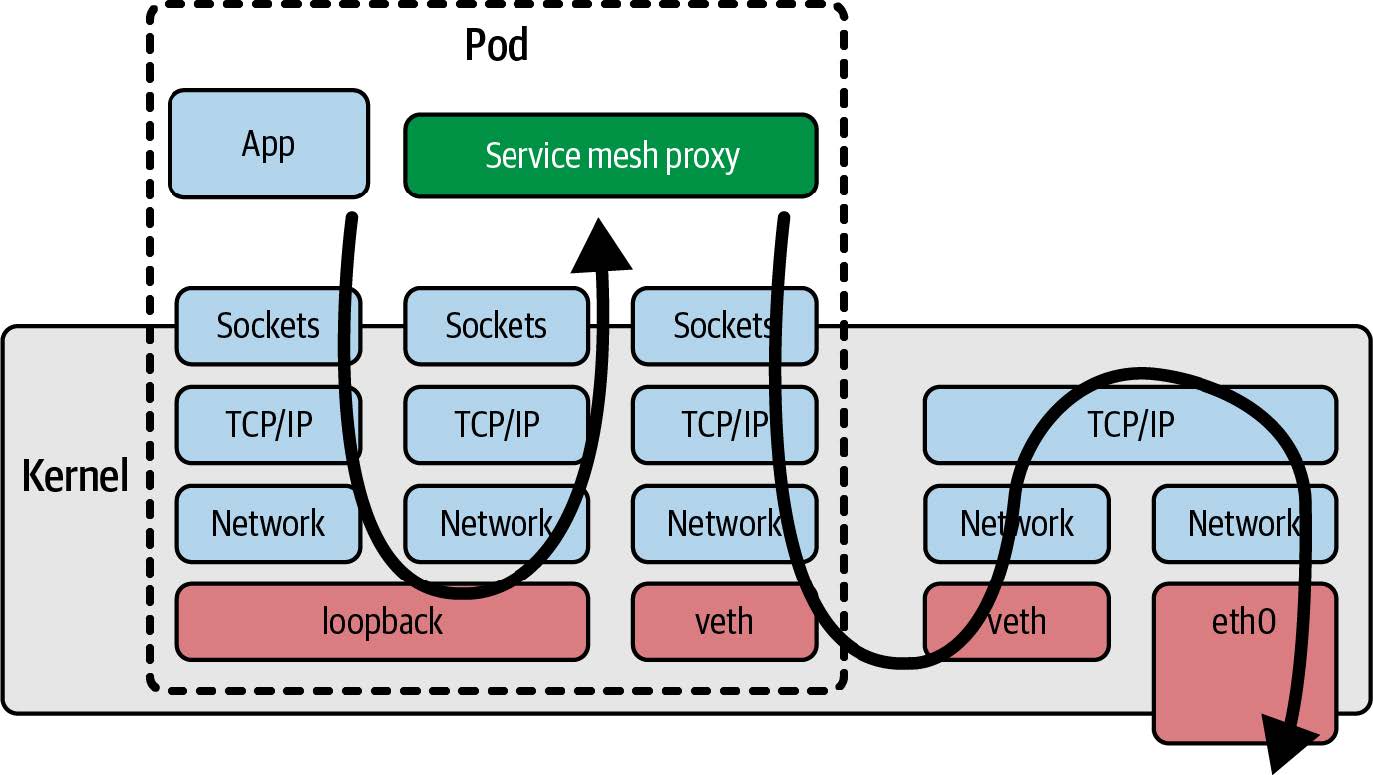
图 1-5. 使用服务网格代理 sidecar 容器的网络数据包路径
所有这些问题都是 Sidecar 模型固有的。幸运的是,现在有了 eBPF 作为平台,我们有了一种新的模型可以避免这些问题。此外,由于基于 eBPF 的工具可以观察到(虚拟)机器上发生的一切,恶意行为者很难绕过这些工具。例如,如果攻击者设法在您的主机上部署了一款加密货币挖矿应用程序,他们可能不会将您在应用程序工作负载中使用的 Sidecar 工具部署在他们的挖矿应用程序上。假设您依赖基于 Sidecar 的安全工具来防止应用程序进行意外的网络连接,那么如果 Sidecar 没有被注入,该工具将无法发现挖矿应用程序连接到其挖矿池的行为。相比之下,基于 eBPF 实现的网络安全可以监控主机上的所有流量,因此可以轻松阻止这种加密货币挖矿行为。我们将在第 8 章中重新讨论出于安全原因丢弃网络数据包的能力。
总结
希望本章能让您了解到为何 eBPF 作为一个平台如此强大。它允许我们改变内核的行为,提供构建定制工具或自定义策略的灵活性。基于 eBPF 的工具可以观察到内核中的任何事件,从而观察到(虚拟)机器上运行的所有应用程序,无论它们是否容器化。eBPF 程序还可以动态部署,允许行为随时更改。
到目前为止,我们主要从概念层面讨论了 eBPF。在下一章中,我们将更具体地探索基于 eBPF 的应用程序的组成部分。
Steven McCanne 和 Van Jacobson. “The BSD Packet Filter: A New Architecture for User-level Packet Capture”
这些及其他细节来自 Alexei Starovoitov 在 2015 年 NetDev 演讲中的“BPF – 内核中的虚拟机(BPF – in-kernel virtual machine)”。
内核文档中对 kprobes 工作原理有详细的描述。
这一精彩事实来自 Daniel Borkmann 在 2020 年 KubeCon 演讲中的“eBPF 和 Kubernetes: 用于扩展微服务的小助手(eBPF and Kubernetes: Little Helper Minions for Scaling Microservices)”。
有关指令限制和“复杂性限制”的更多细节,请参见 https://oreil.ly/0iVer。
摘自 Liz Rice 的 “什么是 eBPF?(What Is eBPF?)”。版权 © 2022 O’Reilly Media。经许可使用。
“Linux 5.12 的代码量约 2880 万行”。Phoronix,2021 年 3 月。
Jiang Y, Adams B, German DM. 2013. “我的补丁会被接受吗?会有多快?”(2013)。根据这篇研究论文,33%的补丁被接受,大多数补丁需要三到六个月的时间。
庆幸的是,现有功能的安全补丁会更快地发布。
Høiland-Jørgensen T, Brouer JD, Borkmann D 等人 “eXpress 数据路径:操作系统内核中的快速可编程数据包处理”。第 14 届国际网络实验与技术会议(CoNEXT ’18)论文集。计算机协会;2018:54–66。
第 2 章 eBPF 的 Hello World
在上一章中,我讨论了 eBPF 的强大之处,但如果您尚未具体理解运行 eBPF 程序的真正含义,那也没有关系。在本章中,我将通过一个简单的“Hello World”示例,让您更好地了解它。
正如您在阅读本书时会了解到的,有几种不同的库和框架可用于编写 eBPF 应用程序。作为热身,我将向您展示从编程角度来看可能最易于理解的方法:使用BCC Python 框架。这提供了一种非常简单的方式来编写基本的 eBPF 程序。出于我将在第 5 章中介绍的原因,对于分发给其他用户的生产应用程序,这不一定是我推荐的方法,但对于初学者来说非常棒。
正如您在阅读本书时将了解到的,编写 eBPF 应用程序有多种不同的库和框架。作为热身,我将向您展示从编程角度来看最容易上手的方法:BCC Python 框架。这提供了一种非常简单的方法来编写基本的 eBPF 程序。出于我将在第 5 章中介绍的原因,对于分发给其他用户的生产应用程序,这不一定是我推荐的方法,但它非常适合于入门。
note
如果您想亲自尝试这些代码,可以在 https:// github.com/lizrice/learning-ebpf 的 chapter2 目录中找到。
您可以在https://github.com/iovisor/bcc 找到 BCC 项目,并在 https://github.com/iovisor/bcc/blob/master/INSTALL.md 上找到安装 BCC 的说明。
BCC 的 “Hello World”
下面是 hello.py 的全部源代码,这是一个使用 BCC 的 Python 库编写的 eBPF “Hello World”应用程序1:
#!/usr/bin/python3
from bcc import BPF
program = r"""
int hello(void *ctx) {
bpf_trace_printk("Hello World!");
return 0;
}
"""
b = BPF(text=program)
syscall = b.get_syscall_fnname("execve")
b.attach_kprobe(event=syscall, fn_name="hello")
b.trace_print()
这段代码由两部分组成:将在内核中运行的 eBPF 程序,和将 eBPF 程序加载到内核并读取其生成的跟踪信息的一些用户空间代码。如图 2-1 所示,hello.py 是该应用程序的用户空间部分,而 hello() 是在内核中运行的 eBPF 程序。
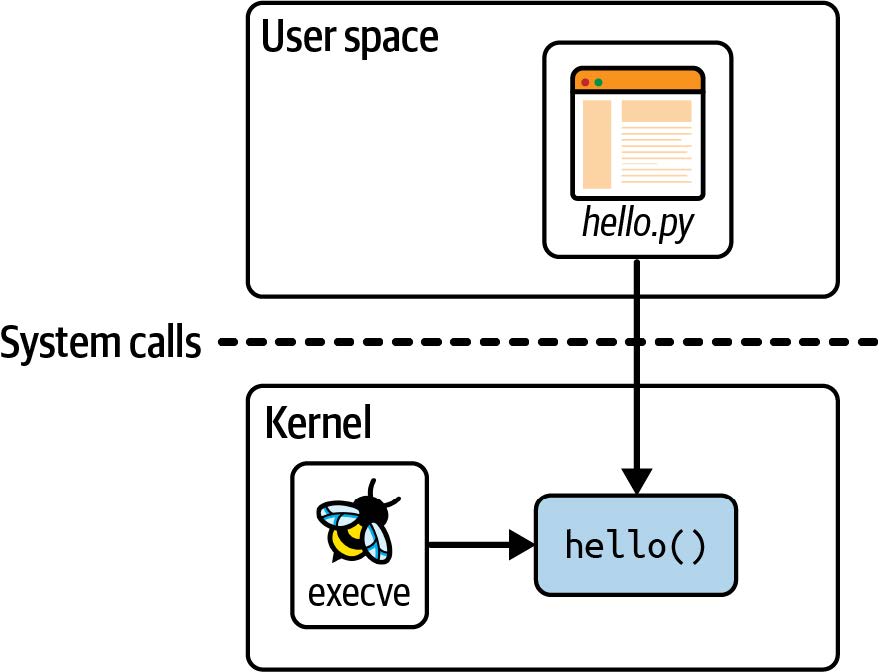
图 2-1. “Hello World” 的用户空间和内核组件
让我们深入了解源代码的每一行,以便更好地理解它。
第一行表明这是 Python 代码,可以运行它的程序是 Python 解释器 (/usr/bin/python)。
eBPF 程序本身是用 C 代码编写的,具体如下:
int hello(void *ctx) {
bpf_trace_printk("Hello World!");
return 0;
}
这个 eBPF 程序所做的只是使用一个辅助函数 bpf_trace_printk() 来写一条消息。辅助函数是“扩展(extended)”BPF 与其“经典(classic)”前身的另一个区别特征。它们是一组 eBPF 程序可以调用与系统交互的函数;我将在第 5 章进一步讨论它们。目前,您可以将其视为打印一行文本。
整个 eBPF 程序在 Python 代码中被定义为一个名为 program 的字符串。该 C 程序需要先进行编译才能执行,但 BCC 会为您处理好。 (您将在下一章中看到如何自己编译 eBPF 程序)您所需要做的就是在创建 BPF 对象时将此字符串作为参数传递,如下行所示:
整个 eBPF 程序在 Python 代码中定义为一个名为 program 的字符串。这个 C 程序需要在执行之前进行编译,但 BCC 为您处理了这一点。(您将在下一章中看到如何自己编译 eBPF 程序。)您所需要做的就是在创建 BPF 对象时将此字符串作为参数传入,如下所示:
b = BPF(text=program)
eBPF 程序需要附加到一个事件上,在这个例子中,我选择附加到系统调用 execve 上,这是用于执行程序的系统调用。无论何时,在这台机器上启动新程序,都会调用 execve(),从而触发 eBPF 程序。虽然“execve()”名称是 Linux 中的标准接口,但实现它的内核函数的名称取决于芯片架构,但 BCC 提供了一种方便的方法来查找我们运行的机器的函数名称:
syscall = b.get_syscall_fnname("execve")
现在,syscall代表我要使用kprobe附加到的内核函数的名称(第 1 章已经介绍了kprobe的概念)2。您可以像这样将hello函数附加到该事件上:
b.attach_kprobe(event=syscall, fn_name="hello")
此时,eBPF 程序被加载到内核中并附加到一个事件上,因此只要机器上启动新的可执行文件时,该程序就会被触发。 Python 代码中剩下要做的就是读取内核输出的跟踪信息并将其输出到屏幕上:
b.trace_print()
这个 trace_print() 函数将无限循环(直到您停止程序,例如通过 Ctrl+C),显示所有跟踪信息。
图 2-2 说明了这段代码。Python 程序编译 C 代码,将其加载到内核,并将其附加到 execve 系统调用的 kprobe 上。无论何时在这台(虚拟)机器上调用 execve(),都会触发 eBPF 程序 hello() ,后者会将一行跟踪信息写入一个特定的伪文件中。(稍后在本章中我会介绍该伪文件的位置。)Python 程序从伪文件中读取跟踪消息并显示给用户。
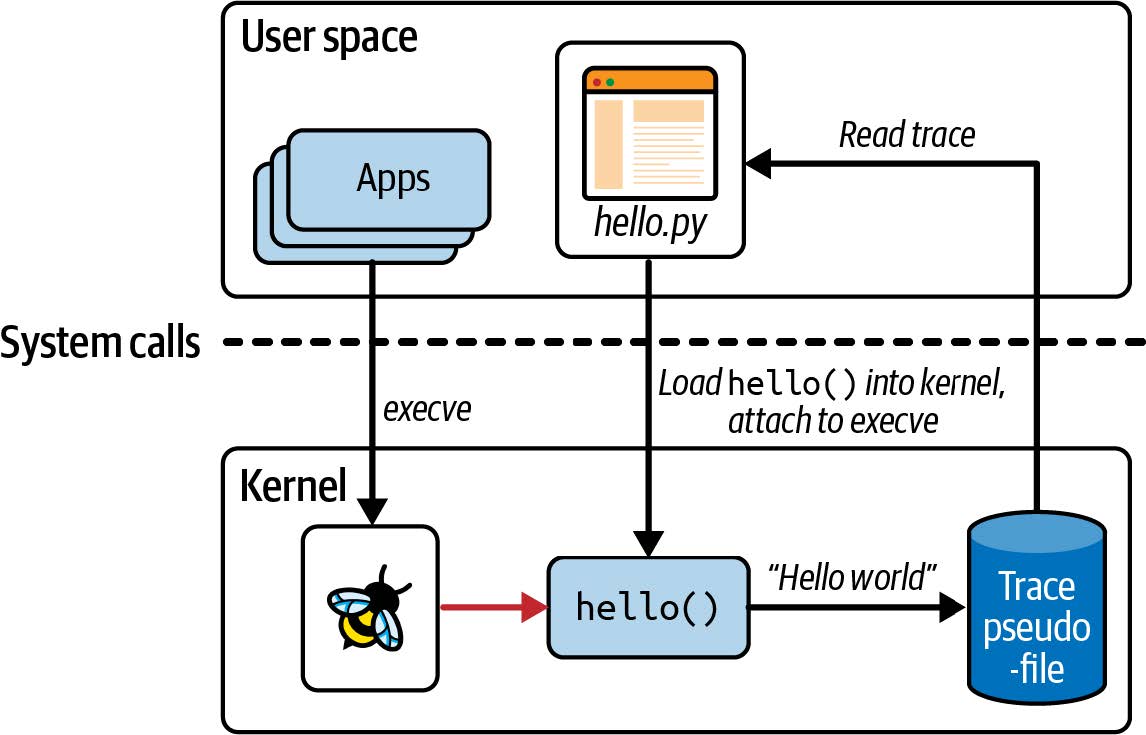
图 2-2. "Hello World" 的操作
运行 "Hello World"
运行这个程序,根据您使用的(虚拟)机器上发生的情况,您可能会立即看到生成的跟踪信息,因为其他进程可能正在执行带有 execve 系统调用的程序3。如果没有看到任何输出,请打开第二个终端并执行您喜欢的任何命令4,您将看到 “Hello World” 生成的相应跟踪信息:
$ hello.py
b' bash-5412 [001] .... 90432.904952: 0: bpf_trace_printk: Hello World'
note
由于 eBPF 非常强大,因此需要特殊权限才能使用它。权限会自动分配给 root 用户,因此最简单的方法是以 root 身份运行 eBPF 程序,或使用 sudo 命令。为清晰起见,本书中的示例命令不会包含 sudo,但如果您遇到“Operation not permitted”错误,首先要检查的是您是否以非特权用户身份尝试运行 eBPF 程序。
CAP_BPF 是在内核版本 5.8 中引入的,它赋予了一些执行 eBPF 操作(如创建某些类型的映射)的足够权限。然而,您可能还需要额外的权限:
- 加载跟踪程序需要
CAP_PERFMON和CAP_BPF。 - 加载网络程序需要
CAP_NET_ADMIN和CAP_BPF。
关于这方面的详细信息,请参阅 Milan Landaverde 的博客文章 “CAP_BPF 简介(Introduction to CAP_BPF)”。
一旦 eBPF 程序 hello 加载并附加到一个事件,就可以被预先存在的进程生成的事件触发。这应该进一步巩固了您在第 1 章中学到的几点::
- eBPF 程序可用于动态更改系统行为。无需重新启动机器或重启现有进程。eBPF 代码一旦附加到事件上,就会立即生效。
- 无需更改其他应用程序,即可使它们对 eBPF 可见。无论您在该机器上的哪个终端访问,如果您在其中运行可执行文件,它将使用
execve()系统调用,而如果您将 hello 程序附加到该系统调用,它将被触发生成跟踪输出。同样,如果您有一个运行可执行文件的脚本,它也会触发 eBPF 程序 hello。您无需更改终端的 shell、脚本或正在运行的可执行文件。
跟踪输出不仅显示了 "Hello World" 字符串,还显示了一些关于触发 eBPF 程序 hello 运行的事件的附加上下文信息。在本节开头显示的示例输出中,执行 execve 系统调用的进程 ID 为 5412,并且它正在运行 bash 命令。对于跟踪消息,这些上下文信息作为内核跟踪基础结构的一部分被添加(这并不是 eBPF 所特有的),但正如您将在本章稍后看到的,也可以在 eBPF 程序中检索到这样的上下文信息。
您可能会想知道 Python 代码是如何知道从哪里读取跟踪输出的。答案并不复杂——内核中的 bpf_trace_printk() 辅助函数总是将输出发送到同一个预定义的伪文件位置:/sys/kernel/debug/tracing/trace_pipe。您可以通过使用 cat 查看其内容来确认这一点;您需要 root 权限才能访问它。
对于简单的 “Hello World” 示例或基本的调试目的来说,一个单一的跟踪管道(trace pipe)位置是可以接受的,但也非常有限。输出格式几乎没有灵活性,并且只支持字符串输出,因此对于传递结构化信息并不是特别有用。或许最重要的是,整个(虚拟)机器上只有这样一个位置。如果同时运行多个 eBPF 程序,它们都会将跟踪输出写入同一个跟踪管道,这对操作人员来说可能会非常混乱。
有一种获取 eBPF 程序信息的更好方法:使用 eBPF 映射(eBPF Map)。
BPF 映射(eBPF Maps)
*映射(map)*是一种数据结构,可以从 eBPF 程序和用户空间访问。映射是将扩展 BPF 与其经典前身区分开来的一个重要特性。(您可能会认为这意味着它们通常被称为 “eBPF 映射(eBPF maps)”。但实际上,您会经常看到 “BPF 映射(BPF maps)”。通常,这两个术语可以互换使用。)
映射可以用于在多个 eBPF 程序之间共享数据,或在用户空间应用程序与内核中运行的 eBPF 代码之间进行通信。典型的用途包括:
- 用户空间写入配置信息,以便 eBPF 程序检索
- eBPF 程序存储状态,供另一个 eBPF 程序(或未来运行的同一程序)检索
- eBPF 程序将结果或指标写入映射,以供用户空间应用程序检索并展示结果
在 Linux 的 uapi/linux/bpf.h 文件中定义了各种类型的 BPF 映射,并且内核文档中也有一些关于它们的信息。一般来说,它们都是键-值存储,在本章中,您将看到哈希表(hash tables)、perf 和环形缓冲区(ring buffers)、eBPF 程序数组(arrays of eBPF programs)等映射的示例。
有些映射类型被定义为数组,其键类型始终为 4 字节索引;其他映射是哈希表,可以使用任意数据类型作为键。
有些映射类型针对特定类型的操作进行了优化,例如先进先出队列、后进先出栈、最近最少使用的数据存储、最长前缀匹配和布隆过滤器(一种概率数据结构,旨在提供非常快速的元素存在性检查)。
有些 eBPF 映射类型保存特定类型对象的信息。例如,sockmaps 和 devmaps 保存有关套接字和网络设备的信息,并被网络相关的 eBPF 程序用来重定向流量。程序数组映射(program array map)存储一组索引的 eBPF 程序(正如您将在本章稍后看到的),这用于实现尾调用(tail calls),即一个程序可以调用另一个程序。甚至还有一种 map-of-maps 类型,支持存储关于映射的信息。
有些映射类型有 per-CPU 变体,即每个 CPU 核心对于该映射都有各自的版本,并且内核使用不同的内存块来存储它们。这可能会让您担心非 per-CPU 映射的并发问题,即多个 CPU 核心可能会同时访问同一个映射。内核版本 5.1 中添加了对(某些)映射的自旋锁支持,我们将在第 5 章中回到这个话题。
下一个示例(GitHub 仓库中的 chapter2/hello-map.py)展示了一些使用哈希表映射(hash table map)的基本操作。它还演示了 BCC 提供的一些方便的抽象,使映射的使用变得非常容易。
哈希表映射(Hash Table Map)
像本章前面的示例一样,这个 eBPF 程序将附加到 execve 系统调用的入口处的 kprobe。它将用键值对填充哈希表,其中键是用户 ID,值是该用户 ID 下运行的进程调用 execve 的次数。实际上,这个示例将显示不同用户运行程序的次数。
首先,让我们看一下 eBPF 程序本身的 C 代码:
BPF_HASH(counter_table); // 1
int hello(void *ctx) {
u64 uid;
u64 counter = 0;
u64 *p;
uid = bpf_get_current_uid_gid() & 0xFFFFFFFF; // 2
p = counter_table.lookup(&uid); // 3
if (p != 0) { // 4
counter = *p;
}
counter++; // 5
counter_table.update(&uid, &counter); // 6
return 0;
}
BPF_HASH()是一个 BCC 宏,用于定义一个哈希表映射。bpf_get_current_uid_gid()是一个辅助函数,用于获取触发此 kprobe 事件的进程的用户 ID。用户 ID 保存在返回的 64 位值的低 32 位中。(高 32 位保存组 ID,但在这里,该部分被屏蔽掉。)- 在哈希表中查找与用户 ID 匹配的键条目。它返回指向哈希表中对应值的指针。
- 如果该用户 ID 有条目,将
counter变量设置为哈希表中的当前值(由p指向)。如果哈希表中没有该用户 ID 的条目,指针将为0,counter值将保持为0。 - 无论当前的
counter值是多少,它都会增加一。 - 用该用户 ID 的新
counter值更新哈希表。
仔细看一下访问哈希表的代码行:
p = counter_table.lookup(&uid);
以及后面的:
counter_table.update(&uid, &counter);
如果您在想“这不是标准的 C 代码!”,那么没错,您绝对是正确的。C 语言不支持在结构体上定义这样的方法5。这是一个很好的例子,说明了 BCC 的 C 版本实际上是一种类 C 语言,BCC 在将代码发送到编译器之前会对其进行重写。BCC 提供了一些便捷的快捷方式和宏,将其转换为“标准”的 C 代码。
就像前面的例子一样,C 代码被定义为一个名为 program 的字符串。该程序被编译、加载到内核,并附加到 execve 的 kprobe,方式与之前的 “Hello World” 示例完全相同:
b = BPF(text=program)
syscall = b.get_syscall_fnname("execve")
b.attach_kprobe(event=syscall, fn_name="hello")
这次在 Python 端需要做更多的工作来读取哈希表中的信息:
while True: # 1
sleep(2)
s = ""
for k,v in b["counter_table"].items(): # 2
s += f"ID {k.value}: {v.value}\t"
print(s)
- 这段代码会无限循环,每两秒钟查看一次输出并显示。
- BCC 自动创建一个 Python 对象来表示哈希表。该代码循环遍历所有值并将其打印到屏幕上。
当您运行此示例时,您将需要第二个终端窗口,您可以在其中运行一些命令。这是我获得的一些示例输出,在右侧用我在另一个终端中运行的命令进行了注释:
运行此示例时,您需要第二个终端窗口,来运行一些命令。以下是我获得的示例输出,在右侧注释了我在另一个终端中运行的命令:
Terminal 1 Terminal 2
$ ./hello-map.py
[blank line(s) until I run something]
ID 501: 1 ls
ID 501: 1
ID 501: 2 ls
ID 501: 3 ID 0: 1 sudo ls
ID 501: 4 ID 0: 1 ls
ID 501: 4 ID 0: 1
ID 501: 5 ID 0: 2 sudo ls
这个示例每两秒生成一行输出,无论是否发生任何事情。在该输出的末尾,哈希表包含两个条目:
key=501, value=5key=0, value=2
在第二个终端中,我的用户 ID 为 501。运行 ls 命令时,该用户 ID 下的 execve 计数器会增加。当我运行 sudo ls 时,会导致两次 execve 调用:一次是以用户 ID 501 执行 sudo;另一次是以 root 的用户 ID 0 执行 ls。
在这个例子中,我使用了哈希表来将数据从 eBPF 程序传递到用户空间。(我也可以使用数组类型的 Map,因为键是整数;而哈希表允许您使用任意类型作为键)当数据自然地以键值对的形式存在时,哈希表非常方便,但用户空间的代码必须定期轮询表来获取数据。Linux 内核已经支持了 perf 子系统,用于从内核向用户空间发送数据,而且 eBPF 还包括对 perf 缓冲区(perf buffers)和其后继者 BPF 环形缓冲区(BPF ring buffers)的支持。让我们来看一下。
Perf 和环形缓冲区映射(Ring Buffer Maps)
在本节中,我将描述一个稍微复杂一些的 “Hello World” 示例,该示例使用 BCC 的 BPF_PERF_OUTPUT 功能,将数据写入到一个 perf 环形缓冲区映射(perf ring buffer map)中。
note
如果您使用的是 5.8 或更高版本的内核,现在通常更推荐使用 “BPF 环形缓冲区(BPF ring buffers)” 这一新构造,而不是 BPF perf 缓冲区(BPF perf buffers)。Andrii Nakryiko 在他的 BPF 环形缓冲区(BPF ring buffers)博客文章中讨论了它们之间的区别。您将在第 4 章中看到 BCC 的 BPF_RINGBUF_OUTPUT 的示例。
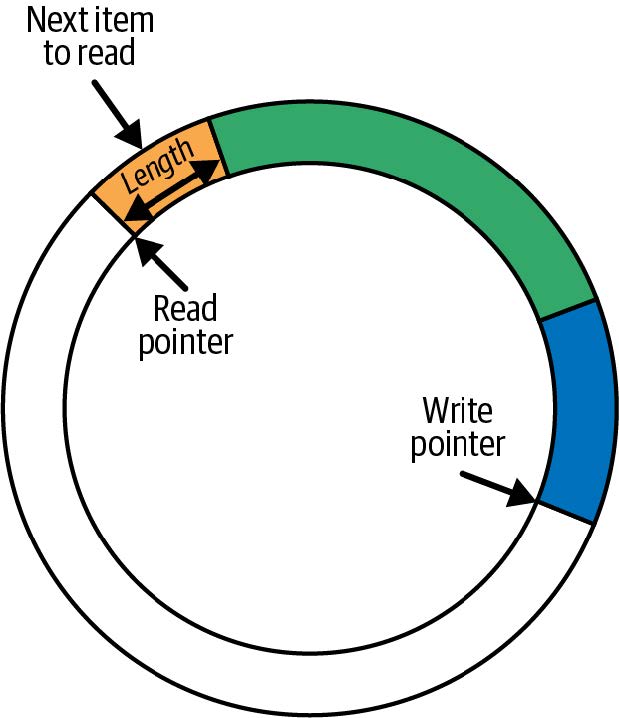
环形缓冲区并不是 eBPF 独有的,但我会解释一下,以防您之前没有接触过。您可以将环形缓冲区想象为一个在逻辑上组织成环形的内存片段,具有独立的“写”指针和“读”指针。任意长度的数据写入写指针所在的位置,数据的长度信息包含在该数据的头部中。写指针移动到该数据的末尾,为下一个写操作做好准备。
同样,对于读操作,数据从读指针所在的位置读取,使用头部来确定要读取的数据量。读指针沿着与写指针相同的方向移动,指向下一个可用的数据片段。如图 2-3 所示,显示了一个具有三个不同长度可读项的环形缓冲区。
如果读指针追上了写指针,意味着没有数据可读。如果写操作会使写指针超过读指针,数据将不会被写入,并且丢弃计数器(drop counter)会增加。读操作包括丢弃计数器,以指示自上次成功读取以来是否有数据丢失。
如果读写操作完全以相同的速率恒定地进行,并且总是包含相同的数据量,理论上您可以使用一个刚好容纳这些数据大小的环形缓冲区。在大多数应用中,读取、写入之间或两者之间的时间会有所不同,因此需要调整缓冲区大小以应对这些变化。
您可以在 Learning eBPF GitHub 仓库的chapter2/hello-buffer.py中找到此示例的源代码。与本章早期展示的第一个“Hello World”示例一样,该版本在每次使用execve()系统调用时都会将字符串“Hello World”写入屏幕。它还会查找每个调用 execve()的进程 ID 和命令名称,以便您能够获得类似于第一个示例的输出。这为我提供了展示几个 BPF 辅助函数的机会。
您可以在 Learning eBPF GitHub 仓库的 chapter2/hello-buffer.py 中找到此示例的源代码。与本章开头看到的第一个 “Hello World” 示例一样,该版本将在每次使用 execve() 系统调用时将字符串 "Hello World" 写到屏幕上。此外,它还会查找每个调用 execve() 的进程 ID 和命令名称,以便您能够获得类似于第一个示例的输出。这给了我展示更多 BPF 辅助函数的机会。
这是将加载到内核的 eBPF 程序:
BPF_PERF_OUTPUT(output); // 1
struct data_t { // 2
int pid;
int uid;
char command[16];
char message[12];
};
int hello(void *ctx) {
struct data_t data = {}; // 3
char message[12] = "Hello World";
data.pid = bpf_get_current_pid_tgid() >> 32; // 4
data.uid = bpf_get_current_uid_gid() & 0xFFFFFFFF; // 5
bpf_get_current_comm(&data.command, sizeof(data.command)); // 6
bpf_probe_read_kernel(&data.message, sizeof(data.message), message); // 7
output.perf_submit(ctx, &data, sizeof(data)); // 8
return 0;
}
- BCC 定义了用于创建映射的宏
BPF_PERF_OUTPUT,该映射用于将消息从内核传递到用户空间。我将这个映射命名为output。 - 每次运行
hello()时,代码都会写入一个结构体的数据。以下是该结构体的定义,包含进程 ID、当前运行命令的名称和一条文本消息。 data是一个局部变量,保存要提交的数据结构,而message保存"Hello World"字符串。bpf_get_current_pid_tgid()是一个辅助函数,用于获取触发此 eBPF 程序运行的进程 ID。它返回一个 64 位值,其中进程 ID 位于高 32 位6。bpf_get_current_uid_gid()是您在前一个示例中看到的用于获取用户 ID 的辅助函数。- 同样,
bpf_get_current_comm()是一个辅助函数,用于获取执行execve系统调用的进程中正在运行的可执行文件(或“命令”)的名称。这是一个字符串,而不是像进程和用户 ID 那样的数值,在 C 语言中您不能简单地使用=赋值字符串。您必须将字符串应写入的字段的地址&data.command作为参数传递给辅助函数。 - 对于这个示例,每次的消息都是
"Hello World"。bpf_probe_read_kernel()将其复制到数据结构体中的正确位置。 - 此时,数据结构体已经填充了进程 ID、命令名称和消息。调用
output.perf_submit()将这些数据放入映射中。
就像第一个“Hello World”示例一样,这个 C 程序被分配给 Python 代码中的一个名为 program 的字符串。接下来是其余的 Python 代码:
b = BPF(text=program) # 1
syscall = b.get_syscall_fnname("execve")
b.attach_kprobe(event=syscall, fn_name="hello")
def print_event(cpu, data, size): # 2
data = b["output"].event(data)
print(f"{data.pid} {data.uid} {data.command.decode()} {data.message.decode()}")
b["output"].open_perf_buffer(print_event) # 3
while True: # 4
b.perf_buffer_poll()
- 编译 C 代码,将其加载到内核中,并附加到
syscall事件,与之前看到的“Hello World”版本相同。 print_event是一个回调函数,它将在屏幕上输出一行数据。BCC 进行了一些繁重的工作,以便可以简单地通过b["output"]引用映射,并使用b["output"].event()从中获取数据。b["output"].open_perf_buffer()打开 perf 环形缓冲区。该函数将print_event作为参数,以定义在缓冲区中有数据可读取时使用的回调函数。- 现在,该程序将无限循环7,轮询 perf 环形缓冲区。如果有任何可用数据,
print_event将被调用。
运行此代码,我们会得到类似于原来“Hello World”的输出:
$ sudo ./hello-buffer.py
11654 node Hello World
11655 sh Hello World
...
与以前一样,您可能需要打开第二个终端连接到相同的(虚拟)机器,并运行一些命令来触发输出。
与原来“Hello World”示例的最大区别在于,它不再使用一个中央跟踪管道(central trace pipe),而是通过一个名为 output 的环形缓冲区映射传递数据,该映射是由此程序创建供其自身使用的,如图 2-4 所示。
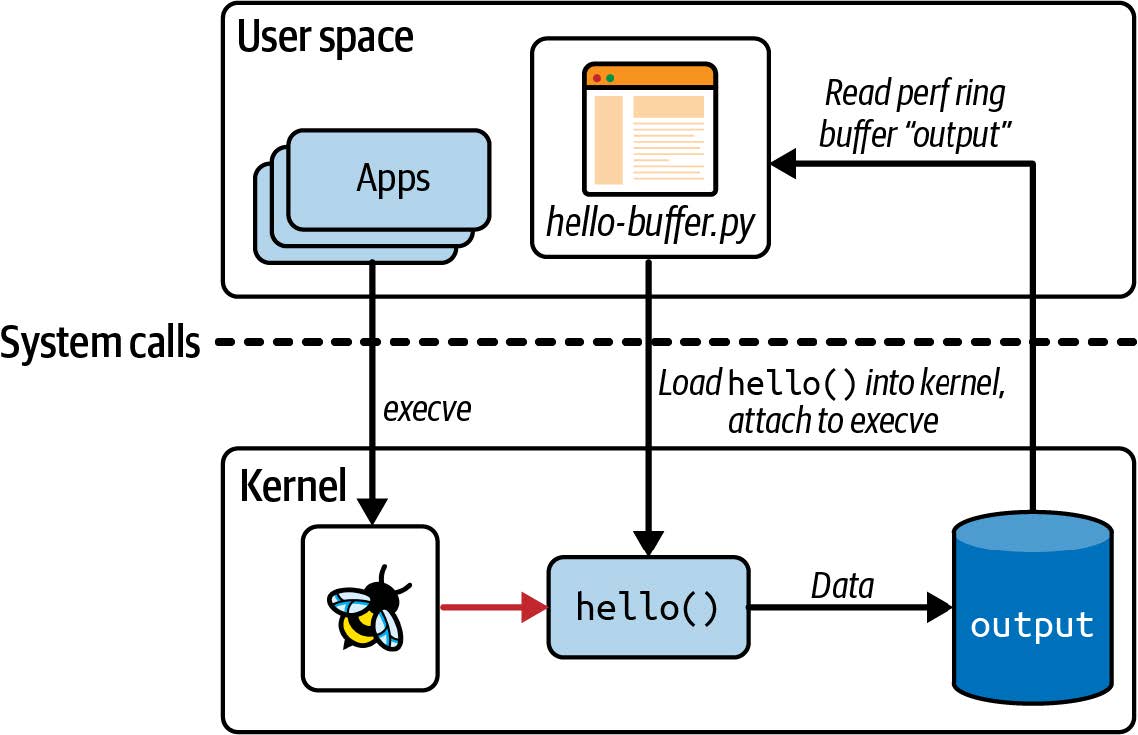
图 2-4.使用 perf 环形缓冲器从内核向用户空间传递数据
您可以使用 cat /sys/kernel/debug/tracing/trace_pipe 来验证信息没有传递到跟踪管道(trace pipe)。
除了展示环缓冲区映射的使用外,此示例还展示了一些 eBPF 辅助函数,用于检索触发 eBPF 程序运行的事件的上下文信息。这里您已经看到辅助函数获取用户 ID、进程 ID 和当前命令的名称。如第七章所述,程序类型和触发事件的类型决定了可用的上下文信息集合以及可用于检索信息的有效辅助函数集合。
上下文信息的可用性使得 eBPF 代码在可观测性方面极具价值。每当事件发生时,eBPF 程序不仅可以报告事件发生的事实,还可以报告触发事件的相关信息。由于所有这些信息都可以在内核内收集,而无需同步上下文切换到用户空间,因此性能也非常高。
在本书中,您将看到更多使用 eBPF 辅助函数收集其他上下文数据的示例,以及一些 eBPF 程序更改上下文数据甚至阻止事件发生的示例。
函数调用
您已经看到 eBPF 程序可以调用内核提供的辅助函数,但如果您想将编写的代码分割成多个函数呢?在软件开发中,通常被认为是良好的实践8是将常见代码提取到一个函数中,然后从多个地方调用它,而不是一遍又一遍地重复相同的代码行。但在早期,eBPF 程序不允许调用辅助函数以外的其他函数。为了解决这个问题,程序员通常会指示编译器“始终内联(always inline)”他们的函数,如下所示:
static __always_inline void my_function(void *ctx, int val)
通常,源代码中的一个函数会导致编译器发出一个跳转指令,这会使执行跳转到构成被调用函数的指令集合(然后在该函数完成时跳转回来)。您可以在图 2-5 的左侧看到这种情况的示意图。右侧显示了内联函数时的情况:没有跳转指令;相反,在调用函数内直接包含函数的指令副本。
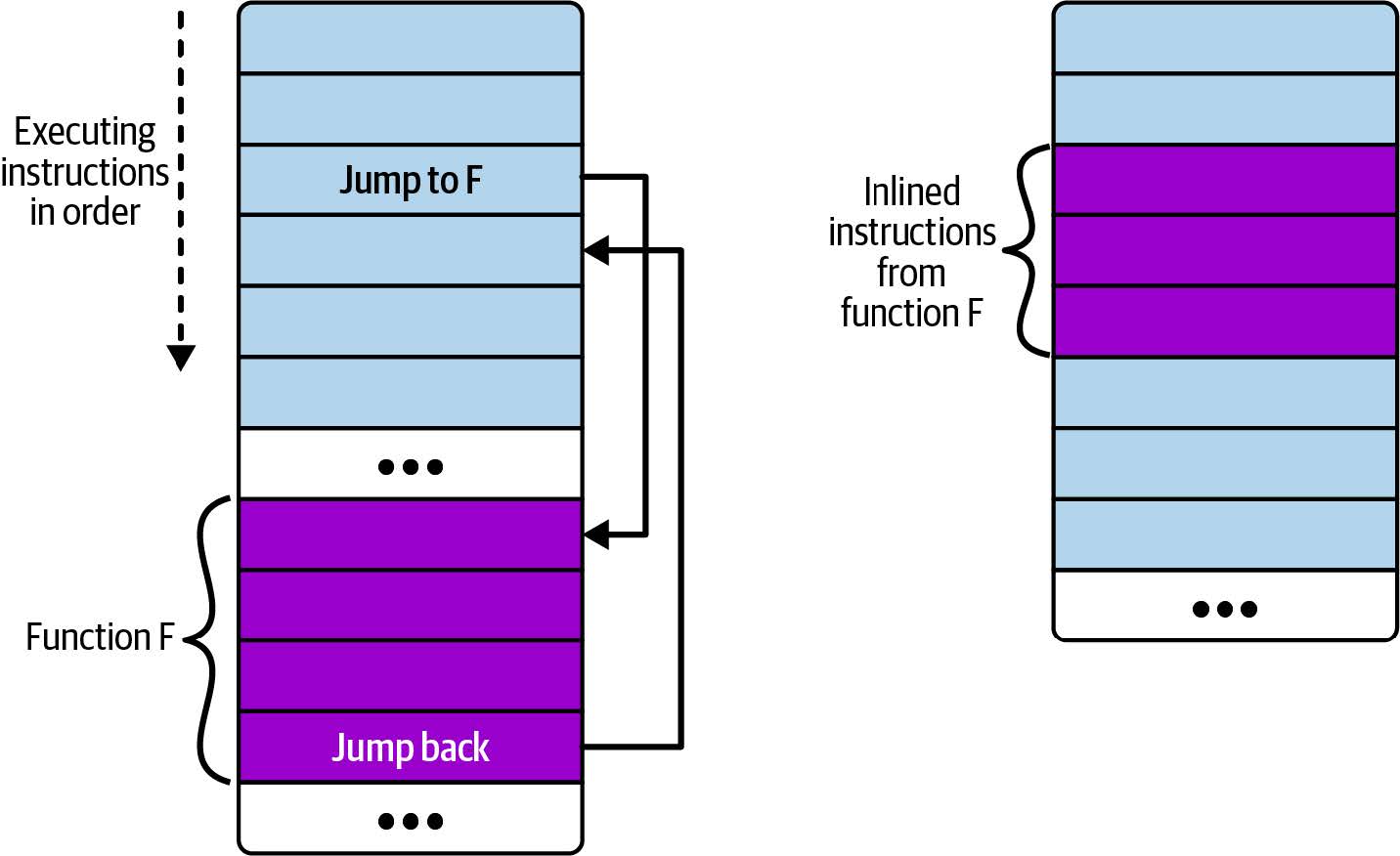
图 2-5. 非内联函数和内联函数的指令布局
如果函数从多个地方调用,那么在编译后的可执行文件中将会有多个该函数的指令副本。(有时编译器可能选择内联某个函数以进行优化,这也是为什么您可能无法将 kprobe 附加到某些内核函数的原因之一。我将在第 7 章中再次讨论这个问题。)
如果从多个地方调用该函数,这会导致在编译后的可执行文件中包含多个该函数指令的副本。(有时编译器可能会出于优化目的,选择内联一个函数。这也是为什么您可能无法附加 kprobe 到某些内核函数的原因之一。在第七章中,我会再提到这一点。)
从 Linux 内核 4.16 和 LLVM 6.0 开始,解除了需要将函数内联的限制,以便 eBPF 程序员可以更自然地编写函数调用。然而,这个名为“BPF to BPF function calls”或“BPF 子程序”的特性目前不受 BCC 框架支持,所以我们将在下一章中回顾它。(当然,如果函数是内联的,您仍然可以继续在 BCC 中使用函数。)
从 Linux 内核 4.16 和 LLVM 6.0 开始,解除了要求函数内联的限制,因此 eBPF 程序员可以更自然地编写函数调用。然而,目前 BCC 框架不支持“BPF 到 BPF 函数调用(BPF to BPF function calls)”或“BPF 子程序(BPF subprograms)”这一特性,因此我们将在下一章中再讨论它。(当然,如果函数是内联的,您仍然可以在 BCC 中继续使用它们。)
在 eBPF 中,还有另一种机制可以将复杂功能分解成更小的部分:尾调用(tail calls)。
尾调用(Tail Calls)
正如 ebpf.io 所描述的那样,“尾调用可以调用并执行另一个 eBPF 程序,并替换执行上下文,类似于 execve() 系统调用对常规进程的操作。”换句话说,尾调用完成后执行不会返回给调用者。
note
尾调用绝不仅仅限于 eBPF 编程。尾调用的总体动机是避免在函数递归调用时一遍又一遍地增加栈帧,这最终可能导致栈溢出错误。如果您可以安排代码在最后调用递归函数,那么调用函数关联的栈帧实际上没有任何作用了。(译者注:在一个函数的最后一条语句调用递归函数,那么当前这个函数的栈帧也就没有什么用了,信息都已经传递给新的函数了。)尾调用允许调用一系列函数而不增加栈。这在 eBPF 中特别有用,因为栈被限制为 512 字节。
尾调用使用 bpf_tail_call() 辅助函数来完成,其签名如下:
long bpf_tail_call(void *ctx, struct bpf_map *prog_array_map, u32 index)
该函数的三个参数的含义如下:
ctx允许从调用的 eBPF 程序传递上下文到被调用程序。prog_array_map是一个BPF_MAP_TYPE_PROG_ARRAY类型的 eBPF 映射,用于保存一组文件描述符,这些描述符用于标识 eBPF 程序。index表示应调用该组 eBPF 程序中的哪个程序。。
这个辅助函数有点不寻常,因为如果它成功执行,将永远不会返回。当前运行的 eBPF 程序的栈会被被调用的程序替换。如果指定的程序不存在于映射中,则可能会失败。在这种情况下,调用程序会继续执行。
用户空间代码必须(像往常一样)将所有 eBPF 程序加载到内核中,并设置程序数组映射(program array map)。
让我们看一个使用 BCC 编写的简单 Python 示例;您可以在GitHub 仓库中的 chapter2/hello-tail.py 找到代码。主 eBPF 程序附加到所有系统调用公共入口点的跟踪点(tracepoint)上。这个程序使用尾调用来跟踪特定系统调用操作码的消息。如果给定操作码没有尾调用,程序会跟踪一个通用消息。
如果您使用 BCC 框架,可以通过稍微简化的形式进行尾调用:
prog_array_map.call(ctx, index)
在将代码传递到编译步骤之前,BCC 会将这一行重写为:
bpf_tail_call(ctx, prog_array_map, index)
以下是 eBPF 程序及其尾调用的源代码:
BPF_PROG_ARRAY(syscall, 300); // 1
int hello(struct bpf_raw_tracepoint_args *ctx) { // 2
int opcode = ctx->args[1]; // 3
syscall.call(ctx, opcode); // 4
bpf_trace_printk("Another syscall: %d", opcode); // 5
return 0;
}
int hello_exec(void *ctx) { // 6
bpf_trace_printk("Executing a program");
return 0;
}
int hello_timer(struct bpf_raw_tracepoint_args *ctx) { // 7
int opcode = ctx->args[1];
switch (opcode) {
case 222:
bpf_trace_printk("Creating a timer");
break;
case 226:
bpf_trace_printk("Deleting a timer");
break;
default:
bpf_trace_printk("Some other timer operation");
break;
}
return 0;
}
int ignore_opcode(void *ctx) { // 8
return 0;
}
- BCC 提供了一个
BPF_PROG_ARRAY宏,用于轻松定义BPF_MAP_TYPE_PROG_ARRAY类型的映射。我将该映射命名为syscall,并设置了 300 个条目9,对于这个示例来说应该足够了。 - 在您稍后将看到的用户空间代码中,我将把这个 eBPF 程序附加到
sys_enter原始跟踪点(raw tracepoint),任何系统调用都会触发该程序。附加到原始跟踪点的 eBPF 程序接收的上下文以bpf_raw_tracepoint_args结构体的形式传递。 - 对于
sys_enter,原始跟踪点参数包括用于标识正在进行的系统调用的操作码(opcode)。 - 在这里,我们对程序数组中键与操作码匹配的条目进行尾调用。BCC 在将源代码传递给编译器之前,会将这一行代码重写为对
bpf_tail_call()辅助函数的调用。 - 如果尾调用成功,这一行跟踪操作码值的代码将永远不会被执行。我用它来为映射中没有对应程序条目的操作码提供一个默认的跟踪行。
hello_exec()是一个将加载到syscall程序数组映射中的程序。当操作码表示系统调用为execve()时,它将作为尾调用执行。它只是生成一行跟踪,告诉用户一个新程序正在执行。hello_timer()是另一个将加载到syscall程序数组中的程序。在本例中,它将被程序数组中的多个条目引用。ignore_opcode()是一个什么都不做的尾调用程序。我将它用于不希望生成任何跟踪的系统调用。
现在让我们看看加载和管理这一组 eBPF 程序的用户空间代码:
b = BPF(text=program)
b.attach_raw_tracepoint(tp="sys_enter", fn_name="hello") # 1
ignore_fn = b.load_func("ignore_opcode", BPF.RAW_TRACEPOINT) # 2
exec_fn = b.load_func("hello_exec", BPF.RAW_TRACEPOINT)
timer_fn = b.load_func("hello_timer", BPF.RAW_TRACEPOINT)
prog_array = b.get_table("syscall")
prog_array[ct.c_int(59)] = ct.c_int(exec_fn.fd) # 3
prog_array[ct.c_int(222)] = ct.c_int(timer_fn.fd)
prog_array[ct.c_int(223)] = ct.c_int(timer_fn.fd)
prog_array[ct.c_int(224)] = ct.c_int(timer_fn.fd)
prog_array[ct.c_int(225)] = ct.c_int(timer_fn.fd)
prog_array[ct.c_int(226)] = ct.c_int(timer_fn.fd)
# 忽略一些经常出现的系统调用
prog_array[ct.c_int(21)] = ct.c_int(ignore_fn.fd)
prog_array[ct.c_int(22)] = ct.c_int(ignore_fn.fd)
prog_array[ct.c_int(25)] = ct.c_int(ignore_fn.fd)
...
b.trace_print()
- 这次,用户空间代码不是附加到 kprobe,而是将主 eBPF 程序附加到
sys_enter跟踪点。 - 调用
b.load_func()会为每个尾调用程序返回一个文件描述符。注意,尾调用需要与其父程序具有相同的程序类型——在此示例中是BPF.RAW_TRACEPOINT。同时需要指出的是,每个尾调用程序本身也是一个独立的 eBPF 程序。 - 用户空间代码在
syscall映射中创建条目。不必为每个可能的操作码都填充条目;如果某个特定操作码没有条目,这只是意味着不会执行尾调用。此外,多个条目指向同一个 eBPF 程序是完全可以的。在这种情况下,我希望hello_timer()尾调用被执行以处理一组与计时器相关的系统调用。 - 系统中的某些系统调用被系统频繁地运行,如果为每个系统调用都生成一行跟踪信息,会导致跟踪输出混乱到无法阅读的程度。对于某些系统调用,我使用了
ignore_opcode()尾调用来处理。 - 将跟踪输出打印到屏幕上,直到用户终止程序。
运行此程序会为(虚拟)机器上运行的每个系统调用生成跟踪输出,除非操作码对应的条目链接到 ignore_opcode() 尾调用。以下是从另一个终端运行 ls 命令的示例输出(为了可读性省略了一些细节):
./hello-tail.py
b' hello-tail.py-2767 ... Another syscall: 62'
b' hello-tail.py-2767 ... Another syscall: 62'
...
b' bash-2626 ... Executing a program'
b' bash-2626 ... Another syscall: 220'
...
b' <...>-2774 ... Creating a timer'
b' <...>-2774 ... Another syscall: 48'
b' <...>-2774 ... Deleting a timer'
...
b' ls-2774 ... Another syscall: 61'
b' ls-2774 ... Another syscall: 61'
...
具体执行的系统调用并不是重点,但您可以看到不同的尾调用被调用并生成跟踪消息。您还可以看到,对于在尾调用程序映射中没有对应条目的操作码,会生成默认消息 Another syscall。
note
请查阅 Paul Chaignon 关于不同内核版本上BPF 尾调用代价的博客文章。
自内核版本 4.2 起,eBPF 开始支持尾调用,但在很长一段时间内,尾调用与 BPF 到 BPF 函数调用(BPF to BPF function calls)是不兼容的。这一限制在内核版本 5.10 中被解除10。
尾调用最多可以链式组合达到 33 次,再加上每个 eBPF 程序的指令复杂度限制为 100 万条指令,这意味着如今的 eBPF 程序员在编写完全在内核中运行的非常复杂的代码方面有很大的灵活性。
总结
希望通过展示一些具体的 eBPF 程序示例,本章可以帮助您巩固在内核中运行、由事件触发的 eBPF 代码的思维模型。您还看到了使用 BPF 映射从内核向用户空间传递数据的示例。
使用 BCC 框架隐藏了许多关于程序如何构建、加载到内核以及附加到事件的细节。在下一章中,我将向您展示编写“Hello World”的另一种方法,并深入探讨这些隐藏的细节。
练习
如果您想进一步探索 "Hello World",这里有一些可选的活动,您可能想尝试一下(或思考一下):
-
修改 eBPF 程序 hello-buffer.py,使其对奇数和偶数进程 ID 输出不同的跟踪消息。
-
修改 hello-map.py,使 eBPF 代码由多个系统调用触发。例如,
openat()常用于打开文件,write()用于向文件写入数据。您可以先将 hello eBPF 程序附加到多个系统调用 kprobes。然后尝试为不同的系统调用修改 eBPF 程序 hello 的版本,证明您可以从多个不同的程序访问同一个映射。 -
eBPF 程序 hello-tail.py 是一个附加到
sys_enter原始跟踪点的示例。任何系统调用被调用时,都会触发该跟踪点。修改 hello-map.py ,通过将其附加到相同的sys_enter原始跟踪点,展示每个用户 ID 发出的总系统调用的数量。 以下是我做出该修改后得到的一些示例输出:$ ./hello-map.py ID 104: 6 ID 0: 225 ID 104: 6 ID 101: 34 ID 100: 45 ID 0: 332 ID 501: 19 ID 104: 6 ID 101: 34 ID 100: 45 ID 0: 368 ID 501: 38 ID 104: 6 ID 101: 34 ID 100: 45 ID 0: 533 ID 501: 57 -
BCC 提供的
RAW_TRACEPOINT_PROBE宏简化了附加到原始跟踪点的过程,它会告诉用户空间 BCC 代码自动将其附加到指定的跟踪点。尝试在 hello-tail.py 中使用它,如下所示:- 将
hello()函数的定义替换为RAW_TRACEPOINT_PROBE(sys_enter)。 - 从 Python 代码中移除显式的附加调用
b.attach_raw_tracepoint()。
您应该会看到 BCC 自动附加,并且程序工作正常。这是 BCC 提供的许多方便宏的一个示例。
- 将
-
您可以进一步修改 hello_map.py,使哈希表中的键标识特定的系统调用(而不是特定的用户)。输出将显示整个系统中该系统调用被调用的次数。
我最初为一个名为“eBPF 编程初学者指南”的讲座编写了这段代码。您可以在 https://github.com/lizrice/ebpf-beginners 找到原始代码以及幻灯片和视频的链接。
从 5.5 版本的内核开始,有一种更高效的方式来将 eBPF 程序附加到函数上,这种方式使用 fentry(以及相应的 fexit,代替 kretprobe 用于函数的退出)。我会在本书后面的章节中讨论这个话题,但现在为了使本章的示例尽可能简单,我仍然使用 kprobe。
我经常使用 VSCode 远程连接到云中的虚拟机。这台虚拟机上运行了大量的 Node 脚本,生成了很多来自这个“Hello World”应用的跟踪信息。
一些命令(比如 echo 是一个常见的例子)可能是 shell 内置命令,这些命令作为 shell 进程的一部分运行,而不是执行一个新的程序。因此,这些命令不会触发 execve() 事件,所以不会生成跟踪信息。
C++ 支持,但 C 不支持。
低 32 位是线程组 ID(thread group ID)。对于单线程进程,这与进程 ID 相同;对于多线程进程,额外的线程会被分配不同的 ID。GNU C 库的文档对进程 ID 和线程组 ID 之间的区别有很好的描述。
这只是示例代码,所以我不担心在键盘中断或其他细节上的清理工作!
这一原则通常被称为“DRY”(“Don’t Repeat Yourself”),由《程序员修炼之道》(The Pragmatic Programmer)推广。
在 Linux 中有大约 300 个系统调用,由于在这个示例中我没有使用最近添加的系统调用,所以这个数量已经足够了。
从 BPF 子程序中进行尾调用需要 JIT 编译器的支持,您将在下一章中遇到这个概念。在我用来编写本书示例的内核版本中,只有 x86 的 JIT 编译器支持这一功能,尽管在 6.0 版本的内核中,ARM 也添加了对这一功能的支持。
第 3 章 eBPF 程序剖析
在前一章中,您已经看到了一个使用 BCC 框架编写的简单的 eBPF“Hello World”程序。在本章中,有一个完全用 C 语言编写的“Hello World”程序示例,以便您能够看到 BCC 在幕后处理的一些细节。
本章还展示了 eBPF 程序从源代码到执行过程中所经历的各个阶段,如图 3-1 所示。

图 3-1. C(或 Rust)源代码被编译为 eBPF 字节码,该字节码要么可以被即时编译(JIT-compiled),要么被解释成本地机器代码指令
eBPF 程序是一组 eBPF 字节码指令。可以直接用编写 eBPF 字节码的方式编写 eBPF 代码,就像可以用汇编语言编程一样。通常,人们更容易处理高级编程语言。至少在撰写本文时,我可以说绝大多数 eBPF 代码是用 C 语言1编写的,然后编译成 eBPF 字节码。
从概念上讲,这些字节码在内核中的 eBPF 虚拟机中运行。
eBPF 虚拟机
eBPF 虚拟机,和其他虚拟机一样,是计算机软件实现的。它接收以 eBPF 字节码指令形式表示的程序,并将这些指令转换为在 CPU 上运行的本地机器指令。
在早期的 eBPF 实现中,字节码指令是在内核中解释执行的——也就是说,每次运行 eBPF 程序时,内核都会检查指令并将其转换为机器码,然后执行它们。出于性能原因以及为了避免 eBPF 解释器中出现一些 Spectre 相关的漏洞,解释执行已在很大程度上被即时(just-in-time,JIT)编译替代。编译意味着当程序加载到内核时,从字节码到本机机器指令的转换只发生一次。
eBPF 字节码由一组指令组成,这些指令作用于(虚拟的)eBPF 寄存器。eBPF 指令集和寄存器模型的设计旨在与常见的 CPU 架构相匹配,以便将字节码编译或解释为机器码的步骤相对简单。
eBPF 寄存器
eBPF 虚拟机使用 10 个通用寄存器,编号从 0 到 9。此外,寄存器 10 被用作栈帧指针(只能读取,不能写入)。在执行 BPF 程序时,这些寄存器中存储的值用于跟踪状态。
需要理解的是,eBPF 虚拟机中的这些寄存器是通过软件实现的。您可以在 Linux 内核源代码的 include/uapi/linux/bpf.h 头文件中看到它们,从 BPF_REG_0 到 BPF_REG_10。
在 eBPF 程序开始执行之前,上下文参数被加载到寄存器 1 中。函数的返回值存储在寄存器 0 中。
eBPF 代码在调用函数之前,该函数的参数被放置在寄存器 1 到寄存器 5 中(如果参数少于五个,则不会使用所有寄存器)。
eBPF 指令
同样的 linux/bpf.h 头文件定义了一个名为 bpf_insn 的结构体,该结构体代表一条 BPF 指令:
struct bpf_insn {
__u8 code; /* opcode */ // 1
__u8 dst_reg:4; /* dest register */ // 2
__u8 src_reg:4; /* source register */
__s16 off; /* signed offset */ // 3
__s32 imm; /* signed immediate constant */
};
- 每条指令都有一个操作码,用于定义该指令要执行的操作:例如,将一个值加到寄存器(所存储的值)中,或跳转到程序中的另一条指令2。Iovisor 项目的“非官方 eBPF 规范(Unofficial eBPF spec)”中列出了有效指令的列表。
- 不同的操作可能涉及最多两个寄存器。
- 根据操作的不同,可能还会有一个偏移值和/或一个“立即”整数值。
bpf_insn 结构体的长度为 64 位(或 8 字节)。然而,有时一条指令可能需要多于 8 字节的空间。如果要将寄存器设置为 64 位值,则无法将该值的所有 64 位与操作码和寄存器信息一起挤进一个结构体中。在这些情况下,指令使用总长度为 16 字节的宽指令编码。您将在本章中看到这方面的示例。
当加载到内核中时,eBPF 程序的字节码由一系列 bpf_insn 结构体表示。验证器对这些信息进行多项检查,以确保代码的运行安全。您将在第 6 章中了解更多关于验证过程的内容。
大多数不同的操作码可以分为以下几类:
- 将一个值加载到寄存器中(可以是立即数、从内存或其他寄存器读取的值)
- 将一个寄存器中的值存储到内存中
- 执行算术操作,例如,将一个值加到寄存器中
- 如果满足特定条件,则跳转到另一条指令
note
关于 eBPF 架构的概述,我推荐 Cilium 项目文档中的 BPF 和 XDP 参考指南。如果您需要更多详细信息,内核文档清晰的描述了 eBPF 指令和编码。
让我们使用另一个简单的 eBPF 程序示例,并跟踪它从 C 源代码,到 eBPF 字节码,再到机器码指令的过程。
note
如果您想自己构建并运行此代码,可以在 github.com/lizrice/learning-ebpf 上找到代码及设置环境的说明。本章的代码在 chapter3 目录中。
本章中的示例是使用名为 libbpf 的库,用 C 语言编写的。您将在第 5 章中了解有关该库的更多信息。
用于网络接口的 eBPF “Hello World”
上一章中的示例通过系统调用的 kprobe 触发了“Hello World”的跟踪输出;这次我要展示一个 eBPF 程序,当网络数据包到达时触发,输出一行跟踪信息。
数据包处理是 eBPF 的一个非常常见的应用。在第 8 章中,我将详细介绍这个内容。但现在,了解每次数据包到达网络接口时,会触发 eBPF 程序的基本概念可能会有所帮助。该程序可以检查甚至修改数据包的内容,并对内核如何处理该数据包做出决定(或判决(verdict))。判决可以指示内核按常规处理它、丢弃它或将其重定向到其他地方。
在这里展示的简单示例中,程序不会对网络数据包做任何处理;它只是在每次接收到网络数据包时,将 Hello World 和一个计数器写入跟踪管道。
示例程序位于 chapter3/hello.bpf.c 中。为了将 eBPF 程序与可能存在于相同源代码目录中的用户空间 C 代码区分开来,将 eBPF 程序放在以 bpf.c 结尾的文件名中是一种相当常见的约定。以下是整个程序:
#include <linux/bpf.h> // 1
#include <bpf/bpf_helpers.h>
int counter = 0; // 2
SEC("xdp") // 3
int hello(struct xdp_md *ctx) { // 4
bpf_printk("Hello World %d", counter);
counter++;
return XDP_PASS;
}
char LICENSE[] SEC("license") = "Dual BSD/GPL"; // 5
- 此示例首先包含了一些头文件。假设您不熟悉 C 编程,每个程序都必须包含定义程序将要使用的任何结构体或函数的头文件。从这些头文件的名称可以看出,它们与 BPF 有关。
- 该示例展示了 eBPF 程序如何使用全局变量。每次程序运行时,这个计数器都会递增。
- 宏
SEC()定义了一个名为xdp的段(section),您将在编译后的目标文件中看到它。稍后在第 5 章中,我会详细解释段名称的用法,但现在您可以简单地将其视为定义一个 eXpress Data Path(XDP)类型的 eBPF 程序。 - 这里可以看到实际的 eBPF 程序。在 eBPF 中,程序名称就是函数名称,所以这个程序名为
hello。它使用一个辅助函数bpf_printk来输出一串文本,递增全局变量counter,然后返回值XDP_PASS。这是指示内核正常处理此网络包的判决。 - 最后,还有另一个定义许可证字符串的
SEC()宏,这是 eBPF 程序的关键要求。内核中的一些 BPF 辅助函数被定义为“仅限 GPL(GPL only)”。如果您想使用这些函数,您的 BPF 代码必须声明为具有 GPL 兼容的许可证。如果声明的许可证与程序使用的函数不兼容,验证器(我们将在第 6 章中讨论)会拒绝加载。某些类型的 eBPF 程序,包括使用 BPF LSM 的程序(将在第 9 章介绍),也必须符合 GPL 兼容性要求。
note
您可能想知道为什么前一章使用 bpf_trace_printk() ,而这个版本使用 bpf_printk()。简而言之,BCC 的版本叫做 bpf_trace_printk(),而 libbpf 的版本叫做 bpf_printk(),但这两个都是对内核函数 bpf_trace_printk() 的封装。Andrii Nakryiko 在他的博客上写了一篇很好的贴子。
这是一个附加到网络接口上的 XDP 钩子点的 eBPF 程序示例。您可以将 XDP 事件视为在网络数据包到达(物理或虚拟)网络接口时立即触发。
note
一些网卡支持将 XDP 程序卸载(offload)到网卡本身执行。这意味着每个到达的网络数据包都可以在网卡上处理,而不会接触到机器的 CPU。XDP 程序可以检查甚至修改每个网络数据包,因此这对于进行 DDoS 防护、防火墙或负载均衡等高性能操作非常有用。您将在第 8 章中进一步了解此功能。
您已经看到了 C 源代码,下一步是将其编译成内核可以理解的目标文件。
编译 eBPF 目标文件
我们的 eBPF 源代码需要编译成 eBPF 虚拟机能理解的机器指令:eBPF 字节码。LLVM 项目中的 Clang 编译器可以通过指定 -target bpf 来完成这项任务。以下是一个 Makefile 的摘录,用于进行编译:
hello.bpf.o: %.o: %.c
clang \
-target bpf \
-I/usr/include/$(shell uname -m)-linux-gnu \
-g \
-O2 -c $< -o $@
这将从 hello.bpf.c 源代码生成一个名为 hello.bpf.o 的目标文件。这里的 -g 标志是可选的3,它可以生成调试信息,这样您在检查目标文件时可以同时看到源代码和字节码。让我们检查一下这个目标文件,以便更好地理解它包含的 eBPF 代码。
检查 eBPF 目标文件
通常使用 file 工具来确定文件的内容:
$ file hello.bpf.o
hello.bpf.o: ELF 64-bit LSB relocatable, eBPF, version 1 (SYSV), with debug_info, not stripped
这表明它是一个 ELF(Executable and Linkable Format,可执行和可链接格式)文件,包含 eBPF 代码,适用于具有 LSB(最低有效位)架构的 64 位平台。如果在编译步骤中使用了-g标志,它将包含调试信息。
您可以使用 llvm-objdump 进一步检查此目标文件,以查看其中的 eBPF 指令:
$ llvm-objdump -S hello.bpf.o
即使您不熟悉反汇编,此命令的输出也不难理解:
hello.bpf.o: file format elf64-bpf # 1
Disassembly of section xdp: # 2
0000000000000000 <hello>: # 3
; bpf_printk("Hello World %d", counter); # 4
0: 18 06 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r6 = 0 ll
2: 61 63 00 00 00 00 00 00 r3 = *(u32 *)(r6 + 0)
3: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll
5: b7 02 00 00 0f 00 00 00 r2 = 15
6: 85 00 00 00 06 00 00 00 call 6
; counter++; # 5
7: 61 61 00 00 00 00 00 00 r1 = *(u32 *)(r6 + 0)
8: 07 01 00 00 01 00 00 00 r1 += 1
9: 63 16 00 00 00 00 00 00 *(u32 *)(r6 + 0) = r1
; return XDP_PASS; # 6
10: b7 00 00 00 02 00 00 00 r0 = 2
11: 95 00 00 00 00 00 00 00 exit
- 第一行进一步确认了 hello.bpf.o 是一个 64 位 ELF 文件,包含 eBPF 代码(有些工具使用 BPF 术语,有些使用 eBPF 术语,没有特别的原因;正如之前所说,这些术语现在几乎是可以互换使用)。
- 接下来是
xdp段的反汇编,与 C 源代码中的SEC()定义相匹配。 - 该段是一个名为
hello的函数。 - 源代码中的
bpf_printk("Hello World %d", counter");行对应的五行 eBPF 字节码指令。 - 三行 eBPF 字节码指令用于增加变量
counter。 - 另外两行字节码由源代码
return XDP_PASS;生成。
除非您特别有兴趣,否则没有必要准确理解每行字节码如何与源代码相关联。编译器会生成字节码,使您不必去考虑这些细节!但让我们稍微详细地查看输出,以便您能够了解这些输出与您本章早些时候学习的 eBPF 指令和寄存器之间的关系。
在每行字节码的左侧,您可以看到该指令在内存中相对于 hello 所在位置的偏移量。正如本章前面所述,eBPF 指令长度通常是 8 字节,而在 64 位平台上,每个内存位置可以容纳 8 字节,因此偏移量通常会每条指令递增 1。然而,该程序中的第一条指令恰好需要 16 字节的宽指令编码,以便将寄存器 6 设置为 64 位值 0。因此,输出的第二行指令的偏移量为 2。之后还有一个 16 字节的指令,将寄存器 1 设置为 64 位值 0。再往后,剩下的指令每条占用 8 字节,因此每行的偏移量递增一。
每行的第一个字节是操作码,指示内核执行的操作,指令行的右侧是人类可读的指令解释。撰写本文时,Iovisor 项目有最完整的 eBPF 操作码文档,但官方的 Linux 内核文档正在逐步完善,eBPF 基金会正在制定不依赖于特定操作系统的标准文档。
例如,我们来看一下偏移量为 5 的指令,如下所示:
5: b7 02 00 00 0f 00 00 00 r2 = 15
这条指令的操作码是0xb7,根据文档的说明,其对应的伪代码是 dst = imm,可以理解为“将目标寄存器设置为立即数”。目标由第二个字节 0x02 定义,表示“寄存器 2”。这里的“立即”(或字面)数是 0x0f,即十进制的 15。因此,我们可以理解这条指令是告诉内核“将寄存器 2 设置为值 15”。这与指令右侧看到的输出相对应:r2 = 15。
偏移量为 10 的指令类似:
10: b7 00 00 00 02 00 00 00 r0 = 2
这行指令同样使用操作码 0xb7,这次是将寄存器 0 的值设置为 2。当一个 eBPF 程序运行结束时,寄存器 0 存放返回值,而 XDP_PASS 的值是 2。这与源代码中的逻辑一致,即始终返回 XDP_PASS。
您现在知道了 hello.bpf.o 包含一个以字节码形式存在的 eBPF 程序。下一步是将其加载到内核中。
将程序加载到内核中
在这个示例中,我们将使用一个名为 bpftool 的工具。您也可以通过编程的方式加载程序,稍后在书中您将看到相关示例。
note
某些 Linux 发行版提供了包含 bpftool 的软件包,或者您可以从源代码编译。您可以在 Quentin Monnet 的博客上找到有关安装或构建此工具的更多详细信息,也可以在 Cilium 网站上找到更多文档和用法。
下面是使用 bpftool 将程序加载到内核的示例。请注意,您可能需要以 root 身份(或使用 sudo)获得 bpftool 所需的 BPF 权限。
$ bpftool prog load hello.bpf.o /sys/fs/bpf/hello
这将从我们编译的目标文件中加载 eBPF 程序,并将其“固定”到位置 /sys/fs/bpf/hello4。对于该命令,没有输出响应表明成功,您也可以使用 ls 确认程序是否已就位:
$ ls /sys/fs/bpf
hello
eBPF 程序已成功加载。让我们使用 bpftool 工具了解有关该程序及其在内核中的状态的更多信息。
检查已加载的程序
bpftool 工具可以列出加载到内核中的所有程序。如果您自己尝试,可能会在输出中看到几个预先存在的 eBPF 程序,但为了清楚起见,我只展示与我们的“Hello World”示例相关的行:
$ bpftool prog list
...
540: xdp name hello tag d35b94b4c0c10efb gpl
loaded_at 2022-08-02T17:39:47+0000 uid 0
xlated 96B jited 148B memlock 4096B map_ids 165,166
btf_id 254
程序已被分配 ID 540。此标识是为每个加载的程序分配的编号。知道 ID 后,您可以使用 bpftool 显示有关此程序的更多信息。这次,我们以美化的 JSON 格式输出,以便字段名称和值可见:
$ bpftool prog show id 540 --pretty
{
"id": 540,
"type": "xdp",
"name": "hello",
"tag": "d35b94b4c0c10efb",
"gpl_compatible": true,
"loaded_at": 1659461987,
"uid": 0,
"bytes_xlated": 96,
"jited": true,
"bytes_jited": 148,
"bytes_memlock": 4096,
"map_ids": [165,166
],
"btf_id": 254
}
根据字段名称,很多内容都很容易理解:
- 程序的 ID 是 540。
type字段告诉我们这个程序可以使用 XDP 事件附加到网络接口。其他类型的 BPF 程序可以附加到不同类型的事件上,我们将在第七章中详细讨论这一点。- 程序名称为
hello,这是源代码中的函数名称。 tag是该程序的另一个标识符,我稍后会详细描述。- 该程序采用 GPL 兼容许可证。
- 有一个时间戳显示程序的加载时间。
- 用户 ID 0(即 root)加载了该程序。
- 此程序中有 96 字节的翻译后的 eBPF 字节码,我会在稍后向您展示。
- 该程序已经过 JIT 编译,编译产生了 148 字节的机器码,我也会在稍后介绍。
bytes_memlock字段告诉我们,此程序保留了 4,096 字节的内存,这些内存不会被分页。- 该程序引用了 ID 为 165 和 166 的 BPF 映射。由于在源代码中没有明显的映射引用,这可能会让人感到意外。您将在本章稍后看到如何使用映射语义来处理 eBPF 程序中的全局数据。
- 您将在第 5 章学习有关 BTF 的内容,现在只需要知道
btf_id表示该程序有一个 BTF 信息块。只有在使用-g标志进行编译时,才会将此信息包含在目标文件中。
BPF 程序标签(tag)
标签(tag)是所有程序指令的 SHA(Secure Hashing Algorithm,安全哈希算法)散列值,可以用作程序的另一个标识符。每次加载或卸载程序时,ID 可能会变化,但标签将保持不变。bpftool 工具接受通过 ID、名称、标签或固定路径来引用 BPF 程序,因此在此示例中,以下所有命令将给出相同的输出:
bpftool prog show id 540bpftool prog show name hellobpftool prog show tag d35b94b4c0c10efbbpftool prog show pinned /sys/fs/bpf/hello
您可以拥有多个同名的程序,甚至是具有相同标签的多个程序实例,但 ID 和固定路径始终是唯一的。
翻译后的字节码
bytes_xlated 字段告诉我们有多少字节的“翻译后”eBPF 代码。这是 eBPF 字节码在通过验证器之后(并可能被内核修改,原因我将在本书后面讨论)得到的结果。
让我们使用 bpftool 来显示我们“Hello World”代码的翻译版本:
$ bpftool prog dump xlated name hello
int hello(struct xdp_md * ctx):
; bpf_printk("Hello World %d", counter);
0: (18) r6 = map[id:165][0]+0
2: (61) r3 = *(u32 *)(r6 +0)
3: (18) r1 = map[id:166][0]+0
5: (b7) r2 = 15
6: (85) call bpf_trace_printk#-78032
; counter++;
7: (61) r1 = *(u32 *)(r6 +0)
8: (07) r1 += 1
9: (63) *(u32 *)(r6 +0) = r1
; return XDP_PASS;
10: (b7) r0 = 2
11: (95) exit
这与您之前从 llvm-objdump 输出中看到的反汇编代码非常相似。偏移地址相同,指令也相似——例如,我们可以看到偏移量为 5 的指令是 r2=15。
JIT 编译的机器代码
翻译后的字节码虽然很低级,但还不是机器代码。eBPF 使用 JIT 编译器将 eBPF 字节码转换为在目标 CPU 上本地运行的机器代码。bytes_jited 字段显示,经此转换之后,程序长度为 108 字节。
note
为了获得更高的性能,eBPF 程序通常会进行 JIT 编译。另一种选择是在运行时解释 eBPF 字节码。eBPF 指令集和寄存器的设计与本机机器指令相当接近,使得解释直接且相对快速,但编译后的程序会更快,现在大多数架构都支持 JIT5。
bpftool 工具可以生成这个 JIT 代码的汇编语言转储。即便您对汇编语言不熟悉,这看起来完全不可理解也无需担心!我之所以将其包括在内,是为了展示 eBPF 代码从源代码到可执行机器指令所经历的所有转换过程。以下是命令及其输出:
$ bpftool prog dump jited name hello
int hello(struct xdp_md * ctx):
bpf_prog_d35b94b4c0c10efb_hello:
; bpf_printk("Hello World %d", counter);
0: hint #34
4: stp x29, x30, [sp, #-16]!
8: mov x29, sp
c: stp x19, x20, [sp, #-16]!
10: stp x21, x22, [sp, #-16]!
14: stp x25, x26, [sp, #-16]!
18: mov x25, sp
1c: mov x26, #0
20: hint #36
24: sub sp, sp, #0
28: mov x19, #-140733193388033
2c: movk x19, #2190, lsl #16
30: movk x19, #49152
34: mov x10, #0
38: ldr w2, [x19, x10]
3c: mov x0, #-205419695833089
40: movk x0, #709, lsl #16
44: movk x0, #5904
48: mov x1, #15
4c: mov x10, #-6992
50: movk x10, #29844, lsl #16
54: movk x10, #56832, lsl #32
58: blr x10
5c: add x7, x0, #0
; counter++;
60: mov x10, #0
64: ldr w0, [x19, x10]
68: add x0, x0, #1
6c: mov x10, #0
70: str w0, [x19, x10]
; return XDP_PASS;
74: mov x7, #2
78: mov sp, sp
7c: ldp x25, x26, [sp], #16
80: ldp x21, x22, [sp], #16
84: ldp x19, x20, [sp], #16
88: ldp x29, x30, [sp], #16
8c: add x0, x7, #0
90: ret
note
某些打包的 bpftool 发行版尚不支持转储 JIT 输出。如果出现这种情况,您将看到“Error: No libbfd support.”。您可以按照 https://github.com/libbpf/bpftool 上的说明自行构建 bpftool。
您已经看到,“Hello World”程序已加载到内核中,但此时它尚未与事件关联,因此没有任何东西会触发它运行。它需要附加到一个事件上。
附加到事件
程序类型必须与其附加的事件类型匹配;您将在第 7 章中了解更多相关信息。本示例是一个 XDP 程序,您可以使用 bpftool 将示例 eBPF 程序附加到网络接口上的 XDP 事件,如下所示:
$ bpftool net attach xdp id 540 dev eth0
note
在撰写本文时,bpftool 工具还不支持附加所有程序类型,但最近已扩展以自动附加 k(ret)probes、u(ret)probes 和 tracepoints。
这里,我使用了程序的 ID 540,但您也可以使用名称(前提是它是唯一的)或标签来标识要附加的程序。在此示例中,我已将程序附加到网络接口 eth0。
您可以使用 bpftool 查看所有网络附加的 eBPF 程序:
$ bpftool net list
xdp:
eth0(2) driver id 540
tc:
flow_dissector:
ID 为 540 的程序已附加到 eth0 接口上的 XDP 事件。此输出还提供了一些有关网络协议栈中可以附加 eBPF 程序的其他潜在事件的线索:tc 和 flow_dissector。更多内容请参阅第 7 章。
您还可以使用 ip link 检查网络接口,输出如下所示(为清晰起见,已删除了一些细节):
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT
group default qlen 1000
...
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdp qdisc fq_codel state UP
mode DEFAULT group default qlen 1000
...
prog/xdp id 540 tag 9d0e949f89f1a82c jited
...
在此示例中,有两个接口:用于将流量发送到本机进程的回环接口 lo,以及将本机连接到外界的 eth0 接口。此输出还显示 eth0 有一个 JIT 编译的 eBPF 程序,其 ID 为 540,标签为 9d0e949f89f1a82c,附加到其 XDP 钩子上。
note
您也可以使用 ip link 将 XDP 程序附加到网络接口或将其从接口分离。我已将其作为本章结尾的练习,并在第 7 章中提供了更多示例。
此时,每当接收到网络数据包时,eBPF 程序 hello 会产生跟踪输出。您可以通过运行 cat /sys/kernel/debug/tracing/trace_pipe 来检查。这应该会显示大量类似如下的输出:
<idle>-0 [003] d.s.. 655370.944105: bpf_trace_printk: Hello World 4531
<idle>-0 [003] d.s.. 655370.944587: bpf_trace_printk: Hello World 4532
<idle>-0 [003] d.s.. 655370.944896: bpf_trace_printk: Hello World 4533
如果您不记得跟踪管道的位置,可以使用命令 bpftool prog tracelog 获得相同的输出。
与第 2 章中的输出相比,这次每个事件都没有与之关联的命令或进程 ID;而是看到每行跟踪的开头都是 <idle>-0。在第 2 章中,每个系统调用事件都是因为用户空间中执行命令的进程调用了系统调用 API。该进程 ID 和命令是 eBPF 程序执行的上下文的一部分。但在这里的示例中,XDP 事件是由于网络数据包的到达而发生的。此时没有与该数据包关联的用户空间进程——当 eBPF 程序 hello 被触发时,系统除了在内存中接收该数据包外,还没有对其执行任何操作,也不知道该数据包是什么或要去哪里。
正如预期的那样,您可以看到跟踪输出的计数器值每次递增 1。在源代码中,counter 是一个全局变量。让我们看看如何在 eBPF 中使用映射实现这一点。
全局变量
正如您在前一章中所了解到的,eBPF 映射是一种可以从 eBPF 程序或用户空间访问的数据结构。由于同一映射可以由同一程序的不同运行多次访问,因此它可以用于在不同执行之间保存状态。多个程序也可以访问同一映射。由于这些特性,映射语义可以被用作全局变量。
note
在 2019 年增加对全局变量的支持之前,eBPF 程序员必须显式编写映射来执行相同的任务。
您之前看到 `bpftool 显示此示例程序使用了两个 ID 为 165 和 166 的映射。(如果您自己尝试,可能会看到不同的 ID,因为这些 ID 是在内核中创建映射时分配的)。让我们来探索一下这些映射包含的内容。
bpftool 工具可以显示加载到内核中的映射。为清晰起见,我将只展示与“Hello World”示例程序相关的条目 165 和 166:
$ bpftool map list
165: array name hello.bss flags 0x400
key 4B value 4B max_entries 1 memlock 4096B
btf_id 254
166: array name hello.rodata flags 0x80
key 4B value 15B max_entries 1 memlock 4096B
btf_id 254 frozen
在从 C 程序编译的目标文件中,bss6 段通常保存全局变量,您可以使用 bpftool 检查其内容,如下所示:
$ bpftool map dump name hello.bss
[{
"value": {
".bss": [{
"counter": 11127
}
]
}
}
]
我也可以使用 bpftool map dump id 165 来检索相同的信息。如果我再次运行这些命令中的任何一个,我会看到计数器增加了,因为每当接收到网络数据包时,程序都会运行。
正如您将在第 5 章中了解到的,bpftool 只有在 BTF 信息可用时才能美化地打印出映射中的字段名称(在这里是变量名称 counter),并且只有在使用 -g 标志编译时才会包含这些信息。如果在编译步骤中省略了该标志,您会看到如下内容:
$ bpftool map dump name hello.bss
key: 00 00 00 00 value: 19 01 00 00
Found 1 element
没有 BTF 信息,bpftool 无法知道源代码中使用的变量名称。由于此映射中只有一项,您可以推断出十六进制值 19 01 00 00 必定是 counter 的当前值(十进制为 281,因为字节的顺序最低有效位)。
您在此看到 eBPF 程序使用映射语义来读写全局变量。在检查另一个映射时,如您所见,映射还用于保存静态数据。
另一个名为 hello.rodata 的映射暗示这可能是与我们的 hello 程序相关的只读数据。您可以转储此映射的内容,以查看它包含 eBPF 程序用于跟踪的字符串:
$ bpftool map dump name hello.rodata
[{
"value": {
".rodata": [{
"hello.____fmt": "Hello World %d"
}
]
}
}
]
如果您没有使用 -g 标志编译目标文件,您将看到如下输出:
$ bpftool map dump id 166
key: 00 00 00 00 value: 48 65 6c 6c 6f 20 57 6f 72 6c 64 20 25 64 00
Found 1 element
此映射中有一个键值对,该值包含以 0 结尾的 12 个字节的数据。您可能不会惊讶于这些字节是字符串 "Hello World %d" 的 ASCII 表示。
现在我们已经完成了对这个程序及其映射的检查,是时候清理它了。我们首先将其与触发它的事件分离。
分离程序
您可以通过如下命令将程序从网络接口分离(detach):
$ bpftool net detach xdp dev eth0
如果该命令成功运行,则不会有输出,但您可以通过 bpftool net list 的输出中缺少 XDP 条目,来确认程序已不再附加:
$ bpftool net list
xdp:
tc:
flow_dissector:
然而,程序仍然加载在内核中:
$ bpftool prog show name hello
395: xdp name hello tag 9d0e949f89f1a82c gpl
loaded_at 2022-12-19T18:20:32+0000 uid 0
xlated 48B jited 108B memlock 4096B map_ids 4
卸载程序
目前,还没有 bpftool prog load 的反向命令(至少在撰写本文时没有),但您可以通过删除固定的伪文件来从内核中移除该程序:
$ rm /sys/fs/bpf/hello
$ bpftool prog show name hello
由于程序不再加载在内核中,因此此 bpftool 命令没有输出。
BPF 到 BPF 调用(BPF to BPF Calls)
在上一章中,您看到了尾调用的应用,并且我提到现在还可以从 eBPF 程序中调用函数。让我们来看一个简单的例子,与尾调用示例一样,将其附加到 sys_enter 跟踪点,但这次它将跟踪输出系统调用的操作码。您可以在 chapter3/hello-func.bpf.c 中找到代码。
出于演示目的,我编写了一个非常简单的函数,用于从跟踪点参数中提取系统调用操作码:
static __attribute((noinline)) int get_opcode(struct bpf_raw_tracepoint_args *ctx) {
return ctx->args[1];
}
在可能的情况下,编译器可能会内联这个非常简单的函数,因为我只会从一个地方调用它。由于这会削弱这个示例的意义,我添加了 __attribute((noinline)) 来强制编译器不内联。在正常情况下,您可能应该省略这一点,并允许编译器根据需要进行优化。
调用该函数的 eBPF 函数如下所示:
SEC("raw_tp")
int hello(struct bpf_raw_tracepoint_args *ctx) {
int opcode = get_opcode(ctx);
bpf_printk("Syscall: %d", opcode);
return 0;
}
将其编译为 eBPF 目标文件后,您可以使用 bpftool 将其加载到内核中并确认它已加载:
$ bpftool prog load hello-func.bpf.o /sys/fs/bpf/hello
$ bpftool prog list name hello
893: raw_tracepoint name hello tag 3d9eb0c23d4ab186 gpl
loaded_at 2023-01-05T18:57:31+0000 uid 0
xlated 80B jited 208B memlock 4096B map_ids 204
btf_id 302
这个练习的有趣部分是检查 eBPF 字节码以查看 get_opcode() 函数:
$ bpftool prog dump xlated name hello
int hello(struct bpf_raw_tracepoint_args * ctx):
; int opcode = get_opcode(ctx); # 1
0: (85) call pc+7#bpf_prog_cbacc90865b1b9a5_get_opcode
; bpf_printk("Syscall: %d", opcode);
1: (18) r1 = map[id:193][0]+0
3: (b7) r2 = 12
4: (bf) r3 = r0
5: (85) call bpf_trace_printk#-73584
; return 0;
6: (b7) r0 = 0
7: (95) exit
int get_opcode(struct bpf_raw_tracepoint_args * ctx): # 2
; return ctx->args[1];
8: (79) r0 = *(u64 *)(r1 +8)
; return ctx->args[1];
9: (95) exit
- 在这里,您可以看到 eBPF 程序
hello()调用了get_opcode()。偏移量为0的 eBPF 指令是0x85,根据指令集文档,对应于“函数调用”。接下来,不会继续执行下一条指令(即偏移量为1的指令),而是会跳过七条指令(pc+7),这意味着将执行偏移量为8的指令。 - 这是
get_opcode()的字节码,正如您所希望的那样,第一条指令偏移量为8。
函数调用指令需要将当前状态放在 eBPF 虚拟机的栈上,以便在被调用函数退出时,可以在调用函数中继续执行。由于栈大小限制为 512 字节,因此 BPF 到 BPF 的调用不能嵌套得太深。
note
关于尾调用和 BPF 到 BPF 调用的更多细节,请参阅 Jakub Sitnicki 在 Cloudflare 博客上的一篇优秀文章:“Assembly within! BPF tail calls on x86 and ARM”。
总结
在本章中,您看到了如何将一些示例 C 源代码转换为 eBPF 字节码,然后编译为机器代码,以便在内核中执行。您还学习了如何使用 bpftool 检查加载到内核中的程序和映射,以及如何附加到 XDP 事件。
此外,您还看到了由不同事件触发的不同类型 eBPF 程序的示例。XDP 事件由网络接口上的数据包到达触发,而 kprobe 和 tracepoint 事件则是通过触发内核代码中的某些特定点来触发。在第 7 章中,我将讨论其他类型的 eBPF 程序。
您还学习了如何使用映射来实现 eBPF 程序的全局变量,并且看到了 BPF 到 BPF 的函数调用。
下一章将更深入地介绍当 bpftool 或其他用户空间代码加载程序并将其附加到事件时,在系统调用级别发生的事情。
练习
以下是一些可供尝试的内容,以便进一步探索 BPF 程序:
-
尝试使用如下所示的
ip link命令来附加和分离 XDP 程序:$ ip link set dev eth0 xdp obj hello.bpf.o sec xdp $ ip link set dev eth0 xdp off -
运行第 2 章中的任何 BCC 示例。当程序正在运行时,在第二个终端窗口使用
bpftool检查加载的程序。以下是我运行 hello-map.py 示例时看到的内容:$ bpftool prog show name hello 197: kprobe name hello tag ba73a317e9480a37 gpl loaded_at 2022-08-22T08:46:22+0000 uid 0 xlated 296B jited 328B memlock 4096B map_ids 65 btf_id 179 pids hello-map.py(2785)您还可以使用
bpftool prog dump命令查看这些程序的字节码和机器码。 -
在 chapter2 目录下运行 hello-tail.py,当它运行时,看看它加载的程序。当它正在运行时,查看它加载的程序。您将看到每个尾调用程序被单独列出,如下所示:
$ bpftool prog list ... 120: raw_tracepoint name hello tag b6bfd0e76e7f9aac gpl loaded_at 2023-01-05T14:35:32+0000 uid 0 xlated 160B jited 272B memlock 4096B map_ids 29 btf_id 124 pids hello-tail.py(3590) 121: raw_tracepoint name ignore_opcode tag a04f5eef06a7f555 gpl loaded_at 2023-01-05T14:35:32+0000 uid 0 xlated 16B jited 72B memlock 4096B btf_id 124 pids hello-tail.py(3590) 122: raw_tracepoint name hello_exec tag 931f578bd09da154 gpl loaded_at 2023-01-05T14:35:32+0000 uid 0 xlated 112B jited 168B memlock 4096B btf_id 124 pids hello-tail.py(3590) 123: raw_tracepoint name hello_timer tag 6c3378ebb7d3a617 gpl loaded_at 2023-01-05T14:35:32+0000 uid 0 xlated 336B jited 356B memlock 4096B btf_id 124 pids hello-tail.py(3590)您还可以使用
bpftool prog dump xlated来查看字节码指令,并将其与“BPF 到 BPF 调用”节中的内容进行比较。 -
请谨慎对待此问题,最好只是思考为什么会发生这种情况,而不是尝试实际操作! 如果您从 XDP 程序返回
0值,这对应于XDP_ABORTED,告诉内核中止对此数据包的任何进一步处理。考虑到在 C 中,0通常表示成功,这可能看起来有些违反直觉,但事实就是如此。因此,如果您尝试修改程序以返回0并将其附加到虚拟机的eth0接口,则所有网络数据包都会被丢弃。如果您使用 SSH 连接到该机器,这将是非常不幸的,您可能需要重启机器才能重新获得访问权限!您可以在容器中运行该程序,以便将 XDP 程序附加到仅影响该容器的虚拟以太网接口,而不是整个虚拟机。在 https://github.com/lizrice/lb-from-scratch 上有一个示例。
越来越多的 eBPF 程序也开始使用 Rust 编写,因为 Rust 编译器支持将 eBPF 字节码作为目标。
有一些指令的操作会受到指令中其他字段值的“修改”。例如,在内核 5.12 中引入了一组原子指令,这些指令包括在 imm 字段中指定操作类型的算术操作(ADD、AND、OR、XOR)。
-g 标志被用来生成 BTF 信息,这对于 CO-RE eBPF 程序是必需的,我将在第 5 章进行介绍。
通常情况下,eBPF 程序可以加载到内核中而不必固定到文件位置——但对于 bpftool 来说,这并非可选项,它必须将加载的程序固定。这个原因在“BPF 程序和映射引用”一节中有进一步的解释。
启用 JIT 编译需要在内核中启用CONFIG_BPF_JIT配置选项,并且在运行时可以通过net.core.bpf_jit_enable sysctl设置启用或禁用 JIT 编译。关于不同芯片架构上的 JIT 支持的更多信息,请参阅文档。
这里,bss 代表 “block started by symbol”。
第 4 章 bpf()系统调用
正如您在第 1 章中所看到的,当用户空间应用程序希望内核代表它们执行某项操作时,它们会使用系统调用 API 发出请求。因此,如果用户空间应用程序想将 eBPF 程序加载到内核中,必然会涉及到一些系统调用。实际上,这个系统调用是 bpf()。在本章中,我将向您展示如何使用它来加载 eBPF 程序和映射并与之交互。
值得注意的是,运行在内核中的 eBPF 代码并不使用系统调用来访问映射。系统调用接口仅供用户空间应用程序使用。相反,eBPF 程序使用辅助函数来读写映射;在前两章中,您已经看到了这方面的例子。
如果您自己去编写 eBPF 程序,很可能不会直接调用这些 bpf() 系统调用。我将在书中稍后讨论一些提供更高级抽象的库,使其更容易使用。尽管如此,这些抽象通常与您在本章中看到的底层系统调用命令直接对应。无论您使用什么库,都需要掌握底层操作——加载程序、创建和访问映射等,这些操作将在本章中介绍。
在向您展示 bpf() 系统调用的示例之前,让我们先看看 bpf() 的手册页上的说明,即 bpf() 用于“对扩展的 BPF 映射或程序执行命令”。它还告诉我们,bpf() 的函数签名如下:
int bpf(int cmd, union bpf_attr *attr, unsigned int size);
bpf() 的第一个参数 cmd 指定要执行的命令。bpf() 系统调用不仅执行一个操作——可以使用许多不同的命令来操作 eBPF 程序和映射。图 4-1 展示了一些用户空间代码可能用来加载 eBPF 程序、创建映射、将程序附加到事件以及访问映射中键值对的常见命令。
%E7%B3%BB%E7%BB%9F%E8%B0%83%E7%94%A8/figure-4-1.png)
图 4-1. 用户空间程序使用系统调用与内核中的 eBPF 程序和映射进行交互
bpf() 系统调用的 attr 参数保存用于指定命令参数的必要数据,而 size 表示 attr 中数据的字节数。
您已经在第 1 章中遇到过 strace,当时我用它来展示用户空间代码如何通过系统调用 API 发出许多请求。在本章中,我将用它来演示 bpf() 系统调用的使用。strace 的输出包括每个系统调用的参数,但为了避免本章示例输出过于繁杂,除非 attr 参数中特别有趣的细节,否则我会省略大量细节。
note
您可以在 github.com/lizrice/learning-ebpf 找到代码以及运行环境的设置说明。本章的代码位于 chapter4 目录中。
在这个例子中,我将使用一个名为 hello-buffer-config.py 的 BCC 程序,该程序基于您在第 2 章中看到的示例构建。与 hello-buffer.py 示例类似,该程序每次运行时都会向 perf 缓冲区发送消息,将关于 execve() 系统调用事件的信息从内核传递到用户空间。此版本的新功能是,它允许为每个用户 ID 配置不同的消息。
以下是 eBPF 源代码:
struct user_msg_t { // 1
char message[12];
};
BPF_HASH(config, u32, struct user_msg_t); // 2
BPF_PERF_OUTPUT(output); // 3
struct data_t { // 4
int pid;
int uid;
char command[16];
char message[12];
};
int hello(void *ctx) { // 5
struct data_t data = {};
struct user_msg_t *p;
char message[12] = "Hello World";
data.pid = bpf_get_current_pid_tgid() >> 32;
data.uid = bpf_get_current_uid_gid() & 0xFFFFFFFF;
bpf_get_current_comm(&data.command, sizeof(data.command));
p = config.lookup(&data.uid); // 6
if (p != 0) {
bpf_probe_read_kernel(&data.message, sizeof(data.message), p->message);
} else {
bpf_probe_read_kernel(&data.message, sizeof(data.message), message);
}
output.perf_submit(ctx, &data, sizeof(data));
return 0;
}
- 这行代码定义了一个用于保存 12 字符长度消息的结构体
user_msg_t。 - BCC 宏
BPF_HASH用于定义一个名为config的哈希表映射。它将存储类型为user_msg_t的值,键为类型u32,该类型适用于用户 ID。(如果未指定键和值的类型,BCC 会默认将两者设置为u64。) perf缓冲区输出的定义与第 2 章完全相同。您可以将任意数据提交到缓冲区,因此无需在此处指定任何数据类型...- ...尽管实际上在此示例中程序始终提交一个
data_t结构。这与第 2 章的示例没有变化。 - 其余的大部分 eBPF 程序与您之前看到的
hello()版本相比没有变化。 - 唯一的区别是,代码使用辅助函数获取用户 ID 后,在
config哈希映射中查找以该用户 ID 为键的条目。如果找到匹配的条目,值中包含的消息将替代默认的“Hello World”。
Python 代码增加了两行:
b["config"][ct.c_int(0)] = ct.create_string_buffer(b"Hey root!")
b["config"][ct.c_int(501)] = ct.create_string_buffer(b"Hi user 501!")
它们在 config 哈希表中定义了用户 ID 0 和 501 的消息,它们对应于该虚拟机上的 root 用户 ID 和我的用户 ID。此代码使用 Python 的 ctypes 包来确保键和值的类型与 C 语言中 user_msg_t 的定义相同。
以下是这个示例的一些输出说明,以及我在第二个终端中运行的命令:
Terminal 1 Terminal 2
$ ./hello-buffer-config.py
37926 501 bash Hi user 501! ls
37927 501 bash Hi user 501! sudo ls
37929 0 sudo Hey root!
37931 501 bash Hi user 501! sudo -u daemon ls
37933 1 sudo Hello World
现在您已经了解了该程序的功能,接下来,我想向您展示它运行时使用的 bpf() 系统调用。我将使用 strace 重新运行该程序,并指定 -e bpf 来表示我只对查看 bpf() 系统调用感兴趣:
$ strace -e bpf ./hello-buffer-config.py
如果您亲自尝试,将看到几个调用此系统调用的实例。对于每个实例,您将看到指示 bpf() 系统调用应执行什么操作的命令。大致内容如下:
bpf(BPF_BTF_LOAD, ...) = 3
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_PERF_EVENT_ARRAY...) = 4
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH...) = 5
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE,...prog_name="hello",...) = 6
bpf(BPF_MAP_UPDATE_ELEM, ...}
...
让我们逐一分析这些调用。您和我都没有无限的耐心,因此我不会讨论每次调用的每个参数!我将重点关注我认为有助于讲述用户空间程序与 eBPF 程序交互时所发生事情的部分。
加载 BTF 数据
我看到的第一个 bpf() 调用如下:
bpf(BPF_BTF_LOAD, {btf="\237\353\1\0...}, 128) = 3
在此输出中,您看到的命令是 BPF_BTF_LOAD。这是(至少在撰写本文时)在内核源代码中最全面记录的一组有效命令之一1。
如果您使用的是相对较旧的 Linux 内核,可能不会看到带有此命令的调用,因为它与 BTF2(BPF Type Fromat,BPF 类型格式)有关。BTF 允许 eBPF 程序在不同的内核版本之间移植,这样您就可以在一台机器上编译程序,并在另一台可能使用不同内核版本并因此具有不同内核数据结构的机器上使用它。我将在第 5 章中对此进行更详细的讨论。
这次对 bpf() 的调用将一块 BTF 数据加载到内核中,并且 bpf() 系统调用的返回值(在我的示例中为 3)是引用该数据的文件描述符。
note
文件描述符是打开文件(或类文件对象)的标识符。如果您打开一个文件(使用 open() 或 openat() 系统调用),返回值是一个文件描述符,然后将其作为参数传递给其他系统调用,如 read() 或 write(),以执行对该文件的操作。这里的数据块并不完全是文件,但被赋予一个文件描述符作为标识符,可以用于以后的相关操作。
创建映射
接下来的 bpf() 调用创建了 perf 缓冲区映射 output:
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_PERF_EVENT_ARRAY, , key_size=4,
value_size=4, max_entries=4, ... map_name="output", ...}, 128) = 4
您可以从命令名称 BPF_MAP_CREATE 推测出此调用用于创建 eBPF 映射。可以看到,这个映射的类型是 PERF_EVENT_ARRAY,名为 output。在这个 perf 事件映射中,键和值都是 4 字节长。映射中最多可以存放 4 对键值对,这由 max_entries 字段定义;我将在本章稍后解释为什么这个映射有四个条目。返回值 4 是用于用户空间代码访问 output 映射的文件描述符。
输出中的下一个 bpf() 系统调用创建了 config 映射:
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH, key_size=4, value_size=12,
max_entries=10240... map_name="config", ...btf_fd=3,...}, 128) = 5
这个映射被定义为哈希表映射,键为 4 字节长(对应于可以用来保存用户 ID 的 32 位整数),值为 12 字节长(与 msg_t 结构的长度相匹配)。我没有指定表的大小,因此它使用了 BCC 的默认大小,拥有 10,240 个条目。
这个 bpf() 系统调用也返回了一个文件描述符 5,该描述符将用于在将来的系统调用中引用这个 config 映射。
您还可以看到字段 btf_fd=3,它告诉内核使用之前获得的 BTF 文件描述符 3。正如您将在第 5 章中看到的,BTF 信息描述了数据结构的布局,将其包含在映射定义中意味着拥有关于映射中使用的键和值类型布局的信息。这被 bpftool 等工具用于对映射转储进行美化打印,使其更易于人们理解——您在第 3 章中看到了这方面的例子。
加载程序
到目前为止,您已经看到示例程序使用系统调用将 BTF 数据加载到内核中并创建了一些 eBPF 映射。接下来,它通过以下 bpf() 系统调用将 eBPF 程序加载到内核中:
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=44,
insns=0xffffa836abe8, license="GPL", ... prog_name="hello", ...
expected_attach_type=BPF_CGROUP_INET_INGRESS, prog_btf_fd=3,...}, 128) = 6
这里有一些有趣的字段:
prog_type字段描述了程序类型,这里表示它将被附加到 kprobe。您将在第 7 章中了解更多关于程序类型的信息。insn_cnt字段表示“指令计数”。这是程序中的字节码指令的数量。- 构成这个 eBPF 程序的字节码指令在
insns字段指定的地址处的内存中保存。 - 这个程序被指定为 GPL 许可,以便它可以使用 GPL 许可的 BPF 辅助函数。
- 程序名称是
hello。 expected_attach_type为BPF_CGROUP_INET_INGRESS可能让人感到惊讶,因为它听起来像是与入站网络流量有关的东西,但您知道这个 eBPF 程序将要附加到 kprobe。实际上,expected_attach_type字段仅用于某些程序类型,而BPF_PROG_TYPE_KPROBE并不是其中之一。BPF_CGROUP_INET_INGRESS恰好是 BPF 附加类型列表中的第一个3,因此它的值为 0。prog_btf_fd字段告诉内核先前加载的 BTF 数据中的哪个块与此程序一起使用。这里的值3对应于您从BPF_BTF_LOAD系统调用返回的文件描述符(与用于config映射的 BTF 数据块相同)。
如果程序验证失败(我将在第 6 章中讨论),此系统调用将返回负值,但在这里您可以看到它返回文件描述符 6。 回顾一下,此时文件描述符的含义如表 4-1 所示。
如果程序验证失败(我将在第 6 章讨论),这个系统调用将返回一个负值,但在这里您可以看到它返回了文件描述符 6。概括来说,此时文件描述符的含义如表 4-1 所示。
表 4-1. 在运行 hello-buffer-config.py 时加载程序后的文件描述符
| 文件描述符 | 代表含义 |
|---|---|
| 3 | BTF 数据 |
| 4 | perf 缓冲区映射 output |
| 5 | 哈希表映射 config |
| 6 | eBPF 程序 hello |
从用户空间修改映射
您已经在 Python 用户空间源代码中看到了为用户 ID 为 0 的 root 用户和 ID 为 501 的用户配置特殊消息的代码行:
b["config"][ct.c_int(0)] = ct.create_string_buffer(b"Hey root!")
b["config"][ct.c_int(501)] = ct.create_string_buffer(b"Hi user 501!")
您可以看到这些条目被通过如下系统调用,在映射中定义:
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=5, key=0xffffa7842490, value=0xffffa7a2b410, flags=BPF_ANY}, 128) = 0
BPF_MAP_UPDATE_ELEM 命令用于更新映射中的键值对。BPF_ANY 标志表示如果该键在映射中不存在,则应创建它。这里有两次这样的调用,分别对应于为两个不同用户 ID 配置的两个条目。
map_fd 字段用于标识正在操作的映射。您可以在这看到它是 5,这是先前创建 config 映射时返回的文件描述符。
文件描述符是由内核为特定进程分配的,所以这个值 5 只对该特定用户空间进程有效,在该进程中运行着这个 Python 程序。然而,多个用户空间程序(以及内核中的多个 eBPF 程序)都可以访问相同的映射。两个访问内核中相同映射的用户空间程序可能被分配不同的文件描述符值;同样,两个用户空间程序可能对于完全不同的映射具有相同的文件描述符值。
键和值都是指针,所以无法从 strace 输出中判断键或值的数值。不过,您可以使用 bpftool 查看映射的内容,并看到类似这样的信息:
$ bpftool map dump name config
[{
"key": 0,
"value": {
"message": "Hey root!"
}
},{
"key": 501,
"value": {
"message": "Hi user 501!"
}
}
]
bpftool 是怎么知道如何格式化输出的呢?例如,它如何知道该值是一个结构体,其中包含一个名为 message 的字段,其中包含一个字符串?答案是它使用定义此 map 的 BPF_MAP_CREATE 系统调用中包含的 BTF 信息中的定义。您将在下一章中看到有关 BTF 如何传达此信息的更多详细信息。
bpftool 是怎么知道如何格式化这个输出的?例如,它是如何知道值是一个包含名为 message 字段的字符串的结构体?答案在于它使用了在定义这个映射时通过BPF_MAP_CREATE系统调用包含的 BTF(BPF Type Format)信息。在下一章中,您将了解更多关于 BTF 如何传达这些信息的细节。
您现在已经看到了用户空间如何与内核交互以加载程序和映射,并更新映射中的信息。在您到目前为止看到的系统调用序列中,程序尚未附加到任何事件。这个步骤必须执行,否则程序将永远不会被触发。
需要注意的是,不同类型的 eBPF 程序会以多种不同的方式附加到不同的事件上!在本章稍后,我将向您展示在本例中如何使用系统调用附加到 kprobe 事件上,而这个过程不涉及bpf()调用。相比之下,在本章末尾的练习中,我会展示另一个例子,说明如何通过bpf()系统调用将程序附加到原始跟踪点(raw tracepoint)事件上。
在我们深入了解这些细节之前,我想讨论当您停止运行程序时会发生什么。您会发现程序和映射会自动卸载,这是因为内核使用*引用计数(reference counts)*来跟踪它们。
BPF 程序和映射引用
您知道,使用 bpf() 系统调用将 BPF 程序加载到内核会返回一个文件描述符。在内核中,这个文件描述符是对程序的引用。发起系统调用的用户空间进程拥有这个文件描述符;当该进程退出时,文件描述符会被释放,程序的引用计数会减少。当 BPF 程序不再有任何引用时,内核会移除该程序。
当您将程序*固定(pin)*到文件系统时,会创建一个额外的引用。
固定(pinning)
您已经在第 3 章中看到了固定操作,使用了以下命令:
bpftool prog load hello.bpf.o /sys/fs/bpf/hello
note
这些固定的对象并不是持久化到磁盘上的真实文件。它们是在伪文件系统上创建的,这个文件系统的行为类似于具有目录和文件的常规基于磁盘的文件系统。但它们保存在内存中,这意味着在系统重启后它们将不会保留在原位置。
如果 bpftool 允许您加载程序而不固定它,那将毫无意义,因为当 bpftool 退出时文件描述符会被释放,并且如果引用为零,程序就会被删除,所以不会实现任何有用的功能。但是将程序固定到文件系统意味着程序有了一个额外的引用,所以程序在命令完成后仍然保持加载状态。
当 BPF 程序附加到触发它的钩子时,引用计数也会增加。这些引用计数的行为取决于 BPF 程序的类型。您将在第 7 章中了解更多关于这些程序类型的信息,但有一些与追踪相关(如 kprobes 和 tracepoints)并且总是与用户空间进程相关联;对于这些类型的 eBPF 程序,当该进程退出时,内核的引用计数会减少。在网络协议栈或 cgroups(“control group,控制组”的缩写)中附加的程序不与任何用户空间进程关联,因此即使加载它们的用户空间程序退出了,它们也会保持原位。当使用 ip link 命令加载 XDP 程序时,您已经看到了这样一个例子:
ip link set dev eth0 xdp obj hello.bpf.o sec xdp
ip 命令已经完成,没有定义固定的位置,但尽管如此,bpftool 会现实 XDP 程序已经加载到内核中:
$ bpftool prog list
…
1255: xdp name hello tag 9d0e949f89f1a82c gpl
loaded_at 2022-11-01T19:21:14+0000 uid 0
xlated 48B jited 108B memlock 4096B map_ids 612
这个程序的引用计数不为零,因为在 ip link 命令完成后 XDP 钩子的附加仍然存在。
eBPF 映射也有引用计数,当它们的引用计数降到零时,也会被清理。每个使用映射的 eBPF 程序都会增加计数,用户空间程序对映射持有的文件描述符也会增加计数。
可能的情况是,eBPF 程序的源代码可能会定义一个程序实际上并不引用的映射。假设您想要存储关于程序的一些元数据;您可以将其定义为一个全局变量,正如您在上一章中看到的,这些信息被存储在映射中。如果 eBPF 程序不对该映射执行任何操作,那么程序到映射之间不会自动产生一个引用计数。有一个 BPF(BPF_PROG_BIND_MAP)系统调用,用于将映射与程序关联起来,以便在用户空间加载程序退出并且不再持有映射的文件描述符引用时,映射不会被立即清理。
映射也可以被固定到文件系统中,用户空间程序可以通过映射的路径来获取对映射的访问。
note
Alexei Starovoitov 在他的博客文章“BPF 对象的生命周期”中很好地描述了 BPF 引用计数器和文件描述符。
创建 BPF 程序引用的另一种方式是使用 BPF 链接(link)。
BPF 链接(BPF Links)
BPF 链接为 eBPF 程序与其附加的事件之间提供了一个抽象层。BPF 链接本身可以被固定到文件系统中,这为程序创建了另一个引用。这意味着将程序加载到内核的用户空间进程可以终止,而程序仍然被加载。用户空间加载程序的文件描述符被释放,减少了程序的引用计数,但由于 BPF 链接的存在,引用计数将不为零。
如果您按照本章结尾的练习操作,您将有机会看到 BPF 链接的实际应用。现在,让我们回到 hello-buffer-config.py 使用的 bpf() 系统调用序列。
eBPF 中涉及的其他系统调用
回顾一下,到目前为止,您已经看到了 bpf() 系统调用,它将 BTF 数据、程序和映射,以及映射中的数据添加到内核。 strace 输出中接下来显示的内容与设置 perf 缓冲区有关。
note
本章其余部分将深入探讨在使用 perf 缓冲区、环形缓冲区、kprobes 和映射迭代时涉及的系统调用序列。并非所有的 eBPF 程序都需要做这些事情,所以如果您赶时间或者觉得内容过于详细,可以跳到本章总结。我不会介意的!
初始化 perf 缓冲区
您已经看到了 bpf(BPF_MAP_UPDATE_ELEM) 调用,它们向config 映射中添加条目。接下来,输出显示了一些类似以下格式的调用:
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0xffffa7842490, value=0xffffa7a2b410, flags=BPF_ANY}, 128) = 0
这些调用看起来与定义 config 映射条目的调用非常相似,只是在这种情况下,映射的文件描述符是 4,它代表 output perf 缓冲区映射。
与之前一样,键和值是指针,因此无法从 strace 输出中判断键或值的数值。我看到这个系统调用重复了四次,所有参数的值都相同,但无法知道在每次调用之间指针的值是否发生了变化。通过观察这些 BPF_MAP_UPDATE_ELEM bpf() 调用,我们对缓冲区是如何设置和使用有了一些疑问:
- 为什么有四次对
BPF_MAP_UPDATE_ELEM的调用?这与output映射创建时具有最大四个条目的事实有关吗? - 在这四个
BPF_MAP_UPDATE_ELEM实例之后,strace输出中没有出现更多的bpf()系统调用。这可能看起来有点奇怪,因为映射的存在是为了让 eBPF 程序每次被触发时都能写入数据,而您已经看到用户空间代码显示的数据。这些数据显然不是通过bpf()系统调用从映射中检索的,那么它是如何获取的呢?
您还没有看到任何证据表明 eBPF 程序是如何附加到触发它的 kprobe 事件的。为了解释所有这些问题,我需要 strace 在运行此示例时显示更多系统调用,如下所示:
$ strace -e bpf,perf_event_open,ioctl,ppoll ./hello-buffer-config.py
为了简洁起见,我将忽略与这个示例的 eBPF 功能无关的 ioctl() 调用。
附加到 Kprobe 事件
您已经看到,在 eBPF 程序 hello 加载到内核后,文件描述符 6 被分配来表示它。要将 eBPF 程序附加到一个事件上,您还需要一个代表该特定事件的文件描述符。以下是strace输出中的一行,显示了为execve() kprobe 创建文件描述符的过程:
perf_event_open({type=0x6 /* PERF_TYPE_??? */, ...},...) = 7
根据perf_event_open()系统调用的手册,它“创建了一个文件描述符,允许测量性能信息”。从输出可以看到,strace无法解释值为 6 的类型参数,但如果进一步查看手册,您会发现 Linux 如何支持性能测量单元(Performance Measurement Unit)的动态类型:
...在 /sys/bus/event_source/devices 下,每个 PMU 实例都有一个子目录。在每个子目录中都有一个类型文件,其内容是一个整数,可用于类型字段。
果然,如果您查看该目录,您会发现一个 kprobe/type 文件:
$ cat /sys/bus/event_source/devices/kprobe/type
6
从这里可以看到,对 perf_event_open() 的调用将类型设置为 6,表示这是一个 kprobe 类型的 perf 事件。
不幸的是,strace 没有输出能够明确显示 kprobe 附加到 execve() 系统调用的详细信息,但我希望这里的证据足以使您相信返回的文件描述符所代表的就是这个。
perf_event_open() 的返回码是 7,这代表了 kprobe 的 perf 事件的文件描述符,并且您知道文件描述符 6 代表的是 eBPF 程序 hello。perf_event_open() 的手册还解释了如何使用 ioctl() 在这两者之间创建关联:
PERF_EVENT_IOC_SET_BPF[...] 允许将 Berkeley Packet Filter (BPF)程序附加到现有的 kprobe 跟踪点事件。参数是之前由bpf (2)系统调用创建的 BPF 程序文件描述符。
这解释了您将在 strace 输出中看到的以下 ioctl() 系统调用,其中的参数指的是两个文件描述符:
ioctl(7, PERF_EVENT_IOC_SET_BPF, 6) = 0
还有一个 ioctl() 调用用来启动 kprobe 事件:
ioctl(7, PERF_EVENT_IOC_ENABLE, 0) = 0
有了这些,每当在这个机器上运行 execue() 时,就会触发 eBPF 程序。
设置和读取 Perf 事件
我已经提到,我看到了四个与 output perf 缓冲区相关的 bpf(BPF_MAP_UPDATE_ELEM) 调用。随着额外系统调用的跟踪,strace 输出显示了四个序列,如下所示:
perf_event_open({type=PERF_TYPE_SOFTWARE, size=0 /* PERF_ATTR_SIZE_??? */,
config=PERF_COUNT_SW_BPF_OUTPUT, ...}, -1, X, -1, PERF_FLAG_FD_CLOEXEC) = Y
ioctl(Y, PERF_EVENT_IOC_ENABLE, 0) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0xffffa7842490, value=0xffffa7a2b410, flags=BPF_ANY}, 128) = 0
在上面的输出中,我使用 X 的位置表示值 0、1、2 和 3 。查阅 perf_event_open() 系统调用的手册,您会看到这是 cpu,它前面的字段是 pid 或进程 ID。手册页中写道:
当 pid == -1 并且 cpu >= 0 时,会测量指定 CPU 上的所有进程/线程。
这一序列发生四次对应于我的笔记本电脑有四个 CPU 核心。这终于解释了为什么 "output" perf 缓冲区映射中有四个条目:每个 CPU 核心一个。这也解释了映射类型名称 BPF_MAP_TYPE_PERF_EVENT_ARRAY 中的 “array” 部分,因为该映射不仅仅代表一个 perf 环形缓冲区,而是一个缓冲区数组,每个核心都有一个。
如果您编写 eBPF 程序,无需担心诸如处理核心数量之类的细节,因为这会由第 10 章讨论的 eBPF 库为您处理,但我认为这是当您在此程序上使用 strace 时看到的系统调用中的一个有趣方面。
每个 perf_event_open() 调用都会返回一个文件描述符,我用 Y 表示这些值;这些值分别是 8、9、10 和 11。ioctl() 系统调用为每个文件描述符启用 perf 输出。BPF_MAP_UPDATE_ELEM bpf() 系统调用将映射条目设置为指向每个 CPU 核心的 perf 环形缓冲区,以指示它提交数据的位置。
然后,用户空间代码可以在所有这四个输出流文件描述符上使用 ppoll(),以便无论哪个核心恰好运行给定 execue() kprobe 事件的 eBPF 程序 hello,它都可以获得数据输出。以下是 ppoll() 的系统调用:
ppoll([{fd=8, events=POLLIN}, {fd=9, events=POLLIN}, {fd=10, events=POLLIN},
{fd=11, events=POLLIN}], 4, NULL, NULL, 0) = 1 ([{fd=8, revents=POLLIN}])
如您亲自尝试运行示例程序,您将会看到,这些 ppoll() 调用会阻塞,直到有一个文件描述符中有东西可读。在触发 execve() 之前,您不会在屏幕上看到返回值,而触发 execve() 后,eBPF 程序会写入数据,用户空间通过这个 ppoll() 调用检索这些数据。
在第 2 章中我提到,如果您有一个版本为 5.8 或以上的内核,BPF 环形缓冲区现在比 perf 缓冲区更受欢迎4。让我们看一下同一个示例代码的修改版,它使用了环形缓冲区。
环形缓冲区
正如内核文档中所讨论的,环形缓冲区之所以优于 perf 缓冲区,部分原因是性能优化,同时还能确保数据顺序得以保留,即便数据是由不同的 CPU 核心提交的。所有核心共享同一个缓冲区。
将 hello-buffer-config.py 转换为使用环形缓冲区不需要太多更改。在附带的 GitHub 仓库中,您会在 chapter4/hello-ring-buffer-config.py 中找到这个示例。表 4-2 展示了差异。
表 4-2. 使用 perf 缓冲区和环形缓冲区的示例 BCC 代码之间的差异
| hello-buffer-config.py | hello-ring-buffer-config.py |
|---|---|
BPF_PERF_OUTPUT(output); | BPF_RINGBUF_OUTPUT(output, 1); |
output.perf_submit(ctx, &data, sizeof(data)); | output.ringbuf_output(&data, sizeof(data), 0); |
b["output"].open_perf_buffer(print_event) | b["output"].open_ring_buffer(print_event) |
b.perf_buffer_poll() | b.ring_buffer_poll() |
如您所预期的,由于这些更改仅与输出缓冲区有关,因此与加载程序、config 映射以及将程序附加到 kprobe 事件相关的系统调用都保持不变。
创建 output 环形缓冲区映射的 bpf() 系统调用如下所示:
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_RINGBUF, key_size=0, value_size=0,
max_entries=4096, ... map_name="output", ...}, 128) = 4
strace 输出的主要区别在于,没有观察到在设置 perf 缓冲区时出现的四个不同的 perf_event_open()、ioctl() 和 bpf(BPF_MAP_UPDATE_ELEM) 系统调用序列。对于环形缓冲区,只有一个文件描述符在所有 CPU 核心之间共享。
在撰写本文时,BCC 正在使用我在前面展示的 ppoll 机制来处理 perf 缓冲区,但它使用较新的 epoll 机制来等待环形缓冲区的数据。让我们利用这个机会来了解 ppoll 和 epoll 之间的区别。
在 perf 缓冲区示例中,我展示了 hello-buffer-config.py 生成的一个 ppoll() 系统调用,如下所示:
ppoll([{fd=8, events=POLLIN}, {fd=9, events=POLLIN}, {fd=10, events=POLLIN},
{fd=11, events=POLLIN}], 4, NULL, NULL, 0) = 1 ([{fd=8, revents=POLLIN}])
注意,这传递了文件描述符集 8、9、10 和 11,用户空间进程希望从中检索数据。每次这个轮询事件返回数据时,都必须再次调用 ppoll() 来设置相同的文件描述符集。使用 epoll 时,文件描述符集由内核对象管理。
您可以在以下序列中看到这一点,当 hello-ring-buffer-config.py 在设置对 output 环形缓冲区的访问时,会进行一系列与 epoll 相关的系统调用。
首先,用户空间程序请求在内核中创建一个新的 epoll 实例:
epoll_create1(EPOLL_CLOEXEC) = 8
这返回文件描述符 8。然后有一个对 epoll_ctl() 的调用,告诉内核将文件描述符 4(output 缓冲区)添加到 epoll 实例中的文件描述符集中:
epoll_ctl(8, EPOLL_CTL_ADD, 4, {events=EPOLLIN, data={u32=0, u64=0}}) = 0
用户空间程序使用 epoll_pwait() 等待,直到环形缓冲区中有数据可用。此调用仅在数据可用时返回:
epoll_pwait(8, [{events=EPOLLIN, data={u32=0, u64=0}}], 1, -1, NULL, 8) = 1
当然,如果您正在使用 BCC(或 libbpf,或本书后面将要介绍的任何其他库)之类的框架编写代码,您实际上不需要了解这些底层细节,比如您的用户空间应用程序是如何通过 perf 缓冲区或环形缓冲区从内核获取信息的。我希望您对了解这些工作原理的幕后一瞥感到有趣。
然而,您很可能会发现自己编写了从用户空间访问映射的代码,看看如何实现这一点的示例可能会对您有所帮助。在本章前面,我使用 bpftool 检查了 config 映射的内容。由于这是一个在用户空间运行的工具,让我们使用 strace 来查看它为了检索这些信息而进行的系统调用。
从映射中读取信息
下面的命令显示了 bpftool 在读取 config 映射内容时进行的 bpf() 系统调用的摘录:
$ strace -e bpf bpftool map dump name config
如您将看到的,该序列主要由两个步骤组成:
- 遍历所有映射,寻找名为
config的映射。 - 如果找到匹配的映射,遍历该映射中的所有元素。
查找映射
输出以一系列重复的类似调用开始,因为 bpftool 会遍历所有映射,寻找 config:
bpf(BPF_MAP_GET_NEXT_ID, {start_id=0,...}, 12) = 0 # 1
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=48...}, 12) = 3 # 2
bpf(BPF_OBJ_GET_INFO_BY_FD, {info={bpf_fd=3, ...}}, 16) = 0 # 3
bpf(BPF_MAP_GET_NEXT_ID, {start_id=48, ...}, 12) = 0 # 4
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=116, ...}, 12) = 3
bpf(BPF_OBJ_GET_INFO_BY_FD, {info={bpf_fd=3...}}, 16) = 0
BPF_MAP_GET_NEXT_ID获取指定start_id后的下一个映射的 ID。BPF_MAP_GET_FD_BY_ID返回指定映射 ID 的文件描述符。BPF_OBJ_GET_INFO_BY_FD检索文件描述符所引用对象(在本例中为映射)的信息。此信息包括名称,以便bpftool可以检查这是否是它正在查找的映射。- 重复该序列,获取步骤 1 中映射之后的下一张映射 ID。
对于每个加载到内核中的映射,都有一组这三个系统调用,并且您还会看到 start_id 和 map_id 使用的值与这些映射的 ID 匹配。当没有更多映射可供查看时,重复模式结束,此时 BPF_MAP_GET_NEXT_ID 返回一个 ENOENT 值,如下所示:
bpf(BPF_MAP_GET_NEXT_ID, {start_id=133,...}, 12) = -1 ENOENT (No such file or directory)
如果找到匹配的映射,bpftool 会保存其文件描述符,以便可以从该映射中读取元素。
读取映射中的元素
此时,bpftool 对要读取的映射有一个文件描述符引用。让我们看看读取这些信息的系统调用序列:
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=NULL, # 1
next_key=0xaaaaf7a63960}, 24) = 0
bpf(BPF_MAP_LOOKUP_ELEM, {map_fd=3, key=0xaaaaf7a63960, # 2
value=0xaaaaf7a63980, flags=BPF_ANY}, 32) = 0
[{ # 3
"key": 0,
"value": {
"message": "Hey root!"
}
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=0xaaaaf7a63960, # 4
next_key=0xaaaaf7a63960}, 24) = 0
bpf(BPF_MAP_LOOKUP_ELEM, {map_fd=3, key=0xaaaaf7a63960,
value=0xaaaaf7a63980, flags=BPF_ANY}, 32) = 0
},{
"key": 501,
"value": {
"message": "Hi user 501!"
}
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=0xaaaaf7a63960, # 5
next_key=0xaaaaf7a63960}, 24) = -1 ENOENT (No such file or directory)
} # 6
]
+++ exited with 0 +++
- 首先,应用程序需要在映射中找到一个有效的键。它通过
bpf()系统调用的BPF_MAP_GET_NEXT_KEY来实现这一点。key参数是指向键的指针,系统调用将返回这个键之后的下一个有效键。通过传入一个 NULL 指针,应用程序请求映射中的第一个有效键。内核将键写入由next_key指针指向的位置。 - 给定一个键,应用程序请求关联的值,该值将被写入由
value指向的内存位置。 - 此时,
bpftool获得了第一个键值对的内容,并将该信息写入屏幕。 - 这里,
bpftool移动到映射中的下一个键,获取它的值,并将这个键值对写到屏幕上。 - 下一次调用
BPF_MAP_GET_NEXT_KEY返回ENOENT,表示映射中没有更多的条目。 - 此处,
bpftool最终确定屏幕上的输出并退出。
请注意,此处 bpftool 被分配了文件描述符 3 ,这对应于 config 映射。这与 hello-buffer-config.py 使用文件描述符 4 引用的是同一个映射。正如我之前提到的,文件描述符是特定于进程的。
对 bpftool 行为的分析展示了用户空间程序如何遍历可用的映射以及存储在映射中的键值对。
总结
在这一章中,您看到了用户空间代码如何使用 bpf() 系统调用加载 eBPF 程序和映射。您看到了使用 BPF_PROG_LOAD 和 BPF_MAP_CREATE 命令创建程序和映射。
您了解到,内核会跟踪对 eBPF 程序和映射的引用次数,并在引用计数降到零时释放它们。您还了解了,将 BPF 对象固定到文件系统以及使用 BPF 链接创建额外引用的概念。
您看到了一个示例,演示了如何使用 BPF_MAP_UPDATE_ELEM 从用户空间在映射中创建条目。还有类似的命令——BPF_MAP_LOOKUP_ELEM 和 BPF_MAP_DELETE_ELEM 用于从映射中检索和删除值。还有一个命令 BPF_MAP_GET_NEXT_KEY,用于查找映射中存在的下一个键。您可以使用它遍历所有有效条目。
您看到了用户空间程序使用 perf_event_open() 和 ioctl() 将 eBPF 程序附加到 kprobe 事件的示例。对于其他类型的 eBPF 程序,附加方法可能非常不同,其中一些甚至使用 bpf() 系统调用。例如,有一个 bpf(BPF_PROG_ATTACH) 系统调用可以用来附加 cgroup 程序,而 bpf(BPF_RAW_TRACEPOINT_OPEN) 用于原始跟踪点(参见本章末尾的练习 5)。
我还演示了如何使用 BPF_MAP_GET_NEXT_ID、BPF_MAP_GET_FD_BY_ID 和 BPF_OBJ_GET_INFO_BY_FD 来定位内核持有的映射(和其他)对象。
本章中还有一些 bpf() 命令没有涉及,但是您在这里看到的内容足以获得一个很好的全局视图了。
您还看到了一些 BTF 数据被加载到内核中,我提到 bpftool 使用这些信息来理解数据结构的格式,以便能够漂亮地打印它们。我还没有解释 BTF 数据的样子,或者它是如何用来使 eBPF 程序跨内核版本移植的。这些内容将在下一章中介绍。
练习
如果您想进一步探索 bpf() 系统调用,可以尝试以下几件事情:
-
确认从
BPF_PROG_LOAD系统调用中获取的insn_cnt字段与使用bpftool转储该程序翻译后的 eBPF 字节码时输出的指令数量相匹配。(这在bpf()系统调用的手册上有记录) -
运行示例程序的两个实例,以便有两个名为
config的映射。如果您运行bpftool map dump name config,输出将包括关于两个不同映射及其内容的信息。在strace下运行此命令,并跟踪系统调用输出中的不同文件描述符的使用。您能否看到它在哪里检索关于映射的信息,以及它在哪里检索存储在其中的键值对? -
在运行示例程序时,使用
bpftool map update修改config映射。使用sudo -u username来检查这些配置更改是否被 eBPF 程序采取。 -
当 hello-buffer-config.py 运行时,使用
bpftool将程序固定到 BPF 文件系统,如下所示:bpftool prog pin name hello /sys/fs/bpf/hi退出正在运行的程序,并使用
bpftool prog list检查hello程序是否仍然加载在内核中。您可以使用rm /sys/fs/bpf/hi删除固定来清理链接。 -
与附加到 kprobe 相比,在系统调用级别,附加到原始跟踪点要简单得多,因为它仅涉及一个
bpf()系统调用。尝试使用 BCC 的RAW_TRACEPOINT_PROBE宏,将 hello-buffer-config.py 转换为附加到sys_enter的原始跟踪点(如果您完成了第 2 章的练习,您已经有一个合适的程序可以使用)。在 Python 代码中,您不需要显式地附加程序,因为 BCC 会为您处理。在strace下运行此程序,您应该看到一个类似于以下的系统调用:bpf(BPF_RAW_TRACEPOINT_OPEN, {raw_tracepoint={name="sys_enter", prog_fd=6}}, 128) = 7内核中的跟踪点名为
sys_enter,文件描述符为6的 eBPF 程序正附加到它。从现在开始,每当内核中的执行到达该跟踪点时,都将触发该 eBPF 程序。 -
运行 BCC 的 libbpf 工具集中的 opensnoop 应用程序。此工具设置了一些 BPF 链接,您可以使用 bpftool 查看他们,如下所示:
$ bpftool link list 116: perf_event prog 1849 bpf_cookie 0 pids opensnoop(17711) 117: perf_event prog 1851 bpf_cookie 0 pids opensnoop(17711)确认程序 ID(在我的示例输出中为 1849 和 1851)与列出已加载 eBPF 程序的输出相匹配:
$ bpftool prog list ... 1849: tracepoint name tracepoint__syscalls__sys_enter_openat tag 8ee3432dcd98ffc3 gpl run_time_ns 95875 run_cnt 121 loaded_at 2023-01-08T15:49:54+0000 uid 0 xlated 240B jited 264B memlock 4096B map_ids 571,568 btf_id 710 pids opensnoop(17711) 1851: tracepoint name tracepoint__syscalls__sys_exit_openat tag 387291c2fb839ac6 gpl run_time_ns 8515669 run_cnt 120 loaded_at 2023-01-08T15:49:54+0000 uid 0 xlated 696B jited 744B memlock 4096B map_ids 568,571,569 btf_id 710 pids opensnoop(17711) -
在 opensnoop 运行时,尝试使用
bpftool link pin id 116 /sys/fs/bpf/mylink(使用您在bpftool link list输出中看到的链接 ID 之一)来固定其中一个链接。您应该看到,即使您终止了 opensnoop,链接和相应的程序仍然在内核中保持加载状态。 -
如果您跳转到第 5 章的示例代码,您会找到一个使用 libbpf 库编写的 hello-buffer-config.py 版本。这个库会自动为加载到内核中的程序设置一个 BPF 链接。使用
strace检查它进行的bpf()系统调用,并查看bpf(BPF_LINK_CREATE)系统调用。
如果您想查看完整的 BPF 命令集,可以参考 linux/bpf.h 头文件中的文档。
BTF 是在 5.1 内核中引入的,但在一些 Linux 发行版中已被回溯移植,正如这个讨论中所展示的那样。
这些定义在 linux/bpf.h 中的 bpf_attach_type 枚举类型中。
提醒您,要了解更多信息,请阅读 Andrii Nakryiko 的“BPF 环形缓冲区”博客文章。
第五章 CO-RE、BTF 和 Libbpf
在上一章中,您第一次遇到了 BTF(BPF Type Format,BPF 类型格式)。本章讨论它存在的原因以及如何使用它来使 eBPF 程序在不同版本的内核之间可移植。它是 BPF 一次编译、到处运行 (compile once-run everywhere,CO-RE) 方法的关键部分,该方法解决了 eBPF 程序在不同内核版本之间可移植的问题。
许多 eBPF 程序访问内核数据结构体,eBPF 程序员需要包含相关的 Linux 头文件,以便他们的 eBPF 代码可以正确定位这些数据结构体中的字段。然而,Linux 内核正在不断开发,这意味着不同内核版本之间的内部数据结构体可能会发生变化。如果您要将在一台机器上编译的 eBPF 目标文件加载到具有不同内核版本的机器上,则无法保证数据结构体相同。(严格来说,数据结构体定义来自内核头文件,您可以选择基于一组头文件进行编译,其中这组头文件可以与用于构建当前机器上运行的内核的头文件不同。为了正确工作(没有本章中描述的 CO-RE 机制),内核头必须与运行 eBPF 程序的目标机器上的内核兼容。)
CO-RE 方法在高效解决可移植性问题方面迈出了一大步。它允许 eBPF 程序包含编译时的数据结构体布局信息,并提供了一种机制,用于在目标机器上运行时,如果数据结构体布局不同,就调整字段的访问方式。只要程序不访问目标机器内核中根本不存在的字段或数据结构体,程序就可以在不同内核版本之间移植。
在我们深入探讨 CO-RE 如何工作的细节之前,让我们先看看 BCC 项目最初实现内核可移植性的方法,讨论一下为什么它如此受欢迎。
BCC 的可移植性方法
在第 2 章中,我使用 BCC 展示了 eBPF 程序的基本“Hello World”示例。 BCC 项目是第一个用于实现 eBPF 程序的流行项目,为用户空间和内核方面提供了一个框架,对于没有太多内核经验的程序员来说相对容易访问。为了解决跨内核的可移植性,BCC 采用了在运行时、在目标计算机上就地编译 eBPF 代码的方法。这种方法存在许多问题:
- 编译工具链需要安装在您希望运行代码的每台目标计算机上,内核头文件也需要安装(默认情况下并不总是存在)。
- 您必须等待编译完成才能启动该工具,这可能意味着每次启动该工具时都会延迟几秒钟。
- 如果您在大量相同的机器上运行该工具,则在每台机器上重复编译会浪费计算资源。
- 一些基于 BCC 的项目将其 eBPF 源代码和工具链打包到容器镜像中,这使得分发到每台机器变得更容易。但这并不能解决确保内核头文件存在的问题,如果在每台机器上安装多个这样的 BCC 容器,甚至可能意味着更多的重复。
- 嵌入式设备可能没有足够的内存资源来运行编译步骤。
由于这些问题,如果您计划开始开发一个重要的新 eBPF 项目,我不建议使用这种遗留的 BCC 方法,特别是如果您计划将其分发给其他人使用。在本书中,我给出了一些基于 BCC 的示例,因为这是学习 eBPF 基本概念的好方法,特别是因为 Python 用户空间代码非常紧凑且易于阅读。如果您对它比较熟悉,并且想快速完成一些事情,它也是一个很好的选择。但它并不是现代 eBPF 开发的最佳方法。
CO-RE 方法为 eBPF 程序的跨内核可移植性问题提供了更好的解决方案。
提示
github.com/iovisor/bcc 上的 BCC 项目包含各种命令行工具,用于观察 Linux 机器行为的各种信息。位于 tools 目录中的原始版本主要是使用我在本节中描述的这种传统的可移植性方法在 Python 中实现的。
在 BCC 的 libbpf-tools 目录中,您会发现这些用 C 语言编写的工具的更新版本,它们利用了 libbpf 和 CO-RE,并且不会遇到我刚刚列出的问题。它们是一组非常有用的实用程序!
CO-RE 概述
CO-RE 方法由几个要素组成(本节部分内容改编自“What Is eBPF?”,作者:Liz Rice。一项小型且不科学的调查表明,大多数人将其发音与 core 一词相同,而不是两个音节):
- BTF
- BTF 是一种表达数据结构体和函数签名布局的格式。在 CO-RE 中,它用于确定编译时和运行时使用的结构体之间的任何差异。 BTF 还被 bpftool 等工具用来以人类可读的格式转储数据结构体。 Linux 内核从 5.4 开始支持 BTF。
- 内核头
- Linux 内核源代码包含描述其使用的数据结构体的头文件,并且这些头文件在 Linux 版本之间可能发生变化。 eBPF 程序员可以选择包含单独的头文件,或者,正如您将在本章中看到的,您可以使用 bpftool 从正在运行的系统生成一个名为 vmlinux.h 的头文件,它包含了 BPF 程序可能需要的关于内核的所有数据结构体信息。
- 编译器支持
- Clang 编译器得到了增强,因此当它使用 -g 标志编译 eBPF 程序时,它包括所谓的 CO-RE 重定位(CO-RE relocations),该重定位源自描述内核数据结构体的 BTF 信息。 GCC 编译器还在版本 12 中添加了对 BPF 目标的 CO-RE 支持。
- 支持数据结构体重定位的库
- 当用户空间程序将 eBPF 程序加载到内核中时,CO-RE 方法要求根据编译时的数据结构体与即将运行的目标机器上的数据结构体之间的差异,调整字节码以进行补偿。这基于编译到对象中的 CO-RE 重定位信息。有几个库可以处理这个问题:libbpf 是包含此重定位功能的原始 C 库,Cilium eBPF 库为 Go 程序员提供了相同的功能,Aya 为 Rust 提供了同样的功能。
- 可选地,BPF 框架(skeleton)
- 可以从编译的 BPF 对象文件自动生成一个框架,其中包含用户空间代码可以调用的便捷函数,用于管理 BPF 程序的生命周期,如将它们加载到内核中、将它们附加到事件等。如果您使用 C 编写用户空间代码,可以使用 bpftool gen skeleton 命令生成该框架。这些函数是更高级的抽象,对开发人员来说比直接使用底层库(如 libbpf、cilium/ebpf 等)更方便。
提示
Andrii Nakryiko 撰写了一篇出色的博客文章,描述了 CO-RE 的背景,并阐述了它的工作原理和使用方法。他还编写了规范的 BPF CO-RE 参考指南,因此如果您要自己编写代码,请务必阅读该指南。他的 libbpf-bootstrap 指南使用 CO-RE + libbpf + sketchs 从头开始构建 eBPF 应用程序是另一个必读的内容。
现在,您已经对 CO-RE 的要素有了一个大致的了解,让我们从探讨 BTF 开始,深入了解它们是如何工作的。
BPF 类型格式(BPF Type Format)
BTF 信息描述了数据结构体和代码在内存中的布局方式。这些信息可以有多种不同的用途。
BTF 用例
在 CO-RE 章节中讨论 BTF 的主要原因是,了解编译 eBPF 程序的结构体布局与将要运行的结构体布局之间的差异,可以在程序加载到内核时进行适当的调整。我将在本章后面讨论重定位过程,但是现在,让我们考虑一下 BTF 信息的其他用途。
了解结构体的布局方式以及该结构体中每个字段的类型,可以以人类可读的形式漂亮地打印结构体的内容。例如,从计算机的角度来看,字符串只是一系列字节,但是将这些字节转换为字符使字符串更容易被人类理解。您已经在前一章中看到了这样的示例,其中 bpftool 使用 BTF 信息来格式化映射转储的输出。
BTF 信息还包括行和函数信息,这些信息使 bpftool 能够在翻译或即时编译后的程序转储的输出中交错输出源代码,如您在第 3 章中看到的那样。当您阅读第 6 章时,您还将看到源代码信息与验证器日志输出交错在一起,这也来自 BTF 信息。
BPF 自旋锁也需要 BTF 信息。自旋锁用于阻止两个 CPU 核心同时访问相同的 map 值。锁必须作为 map 值结构体的一部分,如下所示:
struct my_value {
... <other fields>
struct bpf_spin_lock lock;
... <other fields>
};
在内核中,eBPF 程序使用 bpf_spin_lock() 和 bpf_spin_unlock() 辅助函数来获取和释放锁。只有当 BTF 信息可以描述锁字段在结构体中的位置时,才能使用这些辅助程序。
提示
内核版本 5.1 中添加了自旋锁支持。自旋锁的使用有很多限制:它们只能用于哈希或数组 map 类型,并且不能用于跟踪或套接字过滤器类型的 eBPF 程序。请阅读 lwn.net 有关 BPF 并发管理文章,了解有关自旋锁的更多信息。
现在您已经知道为什么 BTF 信息有用,让我们通过一些示例来更具体地了解。
使用 bpftool 列出 BTF 信息
与程序和 map 一样,您可以使用 bpftool 实用程序来显示 BTF 信息。以下命令列出了加载到内核中的所有 BTF 数据:
bpftool btf list
1: name [vmlinux] size 5843164B
2: name [aes_ce_cipher] size 407B
3: name [cryptd] size 3372B
...
149: name <anon> size 4372B prog_ids 319 map_ids 103
pids hello-buffer-co(7660)
155: name <anon> size 37100B
pids bpftool(7784)
(为了简洁起见,我省略了结果中的许多条目。)
列表中的第一个条目是 vmlinux,它对应于我之前提到的 vmlinux 文件,该文件保存有关当前运行的内核的 BTF 信息。
提示
本章前面的一些示例重用了第 4 章中的程序,然后在本章后面您将找到新示例,其源代码位于 github.com/lizrice/learning-ebpf 的 Chapter5 目录中。
为了获得这个示例输出,我在运行第 4 章中的 hello-buffer-config 示例时运行了此命令。您可以在以 149: 开头的行上看到描述此进程正在使用的 BTF 信息的条目:
149: name <anon> size 4372B prog_ids 319 map_ids 103
pids hello-buffer-co(7660)
这行带给我们的信息有:
- 这块 BTF 信息的 ID 为 149。
- 这是一个大约 4 KB BTF 信息的匿名 blob。
- 它由 prog_id 319 的 BPF 程序和 map_id 103 的 BPF 映射使用。
- 它还被 ID 为 7660(显示在括号内)的进程使用,该进程运行 hello-buffer-config 可执行文件(其名称已被截断为 15 个字符)。
这些程序、map 和 BTF 标识符与 bpftool 显示的有关 hello-buffer-config 名为 hello 的程序的以下输出相匹配:
bpftool prog show name hello
319: kprobe name hello tag a94092da317ac9ba gpl
loaded_at 2022-08-28T14:13:35+0000 uid 0
xlated 400B jited 428B memlock 4096B map_ids 103,104
btf_id 149
pids hello-buffer-co(7660)
这两组信息之间唯一看起来不完全匹配的是程序引用了一个额外的 map_id, 104。这是 perf 事件缓冲区 map,它不使用 BTF 信息;因此,它不会出现在 BTF 相关输出中。
就像 bpftool 可以转储程序和 map 的内容一样,它也可以用于查看数据块中包含的 BTF 类型信息。
BTF 类型
知道 BTF 信息的 ID 后,您可以使用命令 bpftool btf dump id <id> 检查其内容。当我使用之前获得的 ID 149 运行此程序时,我得到了 69 行输出,每行都是一个类型定义。我将只描述前几行,这应该可以让您很好地了解如何解释其余的内容。前几行的 BTF 信息与配置哈希 map 相关,它在源代码中定义如下:
struct user_msg_t {
char message[12];
};
BPF_HASH(config, u32, struct user_msg_t);
该哈希表的键类型为 u32,值类型为结构体 user_msg_t。该结构体包含一个 12 字节的 message 字段。让我们看看在相应的 BTF 信息中是如何定义这些类型的。
BTF 输出的前三行如下:
[1] TYPEDEF 'u32' type_id=2
[2] TYPEDEF '__u32' type_id=3
[3] INT 'unsigned int' size=4 bits_offset=0 nr_bits=32 encoding=(none)
每行开头方括号中的数字是类型 ID(因此,以 [1] 开头的第一行定义了 type_id 1,等等)。让我们更详细地探讨这三种类型:
- 类型 1 定义了一个名为 u32 的类型,其类型由 type_id 2 定义,即以 [2] 开头的行中定义的类型。如您所知,哈希表中的键的类型为 u32。
- 类型 2 的名称为 __u32,类型由 type_id 3 定义。
- 类型 3 是一个整数类型,名称为 unsigned int,长度为 4 个字节。
上面这三种类型都是 32 位无符号整数类型的同义词。在 C 语言中,整数的长度与平台相关,因此 Linux 定义了像 u32 这样的类型来显式定义特定长度的整数。在本机上,u32 对应于无符号整数。引用这些的用户空间代码应该使用带下划线前缀的同义词,如 __u32。
BTF 输出中的接下来的几种类型如下所示:
[4] STRUCT 'user_msg_t' size=12 vlen=1
'message' type_id=6 bits_offset=0
[5] INT 'char' size=1 bits_offset=0 nr_bits=8 encoding=(none)
[6] ARRAY '(anon)' type_id=5 index_type_id=7 nr_elems=12
[7] INT '__ARRAY_SIZE_TYPE__' size=4 bits_offset=0 nr_bits=32 encoding=(none)
这些与用于 config map 中的值的 user_msg_t 结构体相关:
- 类型 4 是 user_msg_t 结构本身,总共 12 个字节长。它包含一个名为 message 的字段,该字段由类型 6 定义。 vlen 字段指示此定义中有多少个字段。
- 类型 5 被命名为 char,是一个 1 字节整数——这正是 C 程序员对 "char "类型的期望定义。
- 类型 6 将该 message 字段的类型定义为包含 12 个元素的数组。每个元素的类型为 5(它是一个字符),数组的索引为类型 7。
- 类型 7 是一个 4 字节整数。
通过这些定义,您可以完整了解 user_msg_t 结构体在内存中的布局,如图 5-1 所示。
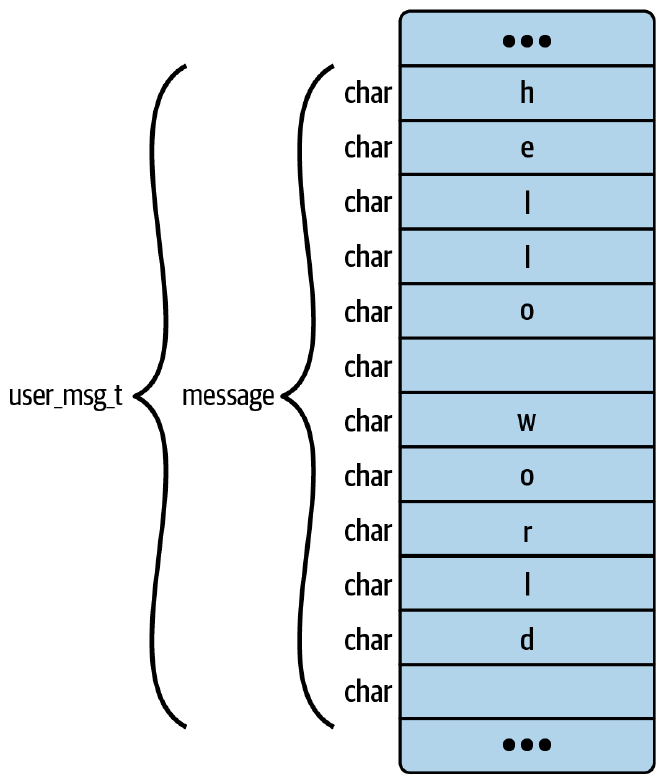
图 5-1. user_msg_t 结构体占用 12 字节内存
到目前为止,所有条目的 bits_offset 都设置为 0,但下一行输出的结构体包含多个字段:
[8] STRUCT '____btf_map_config' size=16 vlen=2
'key' type_id=1 bits_offset=0
'value' type_id=4 bits_offset=32
这是存储在名为 config 的 map 中的键值对的结构定义。我没有在源代码中定义这个btf_map_config 类型,但它是由 BCC 生成的。键的类型为 u32,值是 user_msg_t 结构体。这些对应于您之前看到的类型 1 和 4。
关于该结构体的 BTF 信息的另一个重要部分是值字段在该结构开始后的 32 位开始。这完全有道理,因为需要前 32 位来保存键字段。
提示
在 C 中,结构体字段会自动与边界对齐,因此您不能简单地假设一个字段始终紧跟在内存中的前一个字段之后。例如,考虑这样的结构:
struct something { char letter; u64 number; }在 letter 的字段之后、 number 字段之前将有 7 个字节的未使用内存,以便将 64 位 number 对齐到可被 8 整除的内存位置。
在某些情况下,可以打开编译器打包来避免这种未使用的空间,但它通常会降低性能,而且(至少根据我的经验)这样做是不寻常的。更多时候,C 程序员会手工设计结构体以有效利用空间。
带有 BTF 信息的 map
您刚刚看到了与 map 相关的 BTF 信息。现在让我们看看在创建 map 时,如何将这些 BTF 数据传递给内核。
您在第 4 章中看到,map 是使用 bpf(BPF_MAP_CREATE) 系统调用创建的。这需要一个 bpf_attr 结构体作为参数,在内核中定义如下(省略一些细节):
struct { /* anonymous struct used by BPF_MAP_CREATE command */
__u32 map_type; /* one of enum bpf_map_type */
__u32 key_size; /* size of key in bytes */
__u32 value_size; /* size of value in bytes */
__u32 max_entries; /* max number of entries in a map */
...
char map_name[BPF_OBJ_NAME_LEN];
...
__u32 btf_fd; /* fd pointing to a BTF type data */
__u32 btf_key_type_id; /* BTF type_id of the key */
__u32 btf_value_type_id; /* BTF type_id of the value */
...
};
在引入 BTF 之前,bpf_attr 结构中不存在 btf_* 字段,并且内核不知道键或值的结构。 key_size 和 value_size 字段定义了它们需要多少内存,但它们只是被视为这么多字节。通过额外传入定义键和值类型的 BTF 信息,内核可以深入理解他们,并且像 bpftool 这样的实用程序可以检索类型信息以进行漂亮打印,如前所述。然而,值得注意的是,键和值分别传入了单独的 BTF type_id。您刚刚看到定义的 btf_map_config 结构并未被内核用于 map 定义;它仅由 BCC 在用户空间使用。
函数和函数原型的 BTF 数据
到目前为止,本示例输出中的 BTF 数据与数据类型相关,但 BTF 数据还包含有关函数和函数原型的信息。下面是同一个 BTF 数据 blob 中描述 hello 函数的信息:
[31] FUNC_PROTO '(anon)' ret_type_id=23 vlen=1
'ctx' type_id=10
[32] FUNC 'hello' type_id=31 linkage=static
在类型 32 中,您可以看到名为 hello 的函数被定义为具有上一行中定义的类型。这是一个函数原型,它返回类型 ID 23 的值,并采用一个(vlen=1)名为 ctx 的参数 ,类型 ID 为 10。为了完整起见,以下是前面输出中这些类型的定义:
[10] PTR '(anon)' type_id=0
[23] INT 'int' size=4 bits_offset=0 nr_bits=32 encoding=SIGNED
类型 10 是一个匿名指针,默认类型为 0,它没有显式地包含在 BTF 输出中,但被定义为 void 指针。(请参阅 https://docs.kernel.org/bpf/btf.html#type-encoding 上的内核文档。)
类型 23 的返回值为 4 字节整数,encoding=SIGNED 表示为有符号整数;也就是说,它可以具有正值或负值。这对应于 hello-buffer-config.py 源代码中的函数定义,如下所示:
int hello(void *ctx)
到目前为止,我展示的示例 BTF 信息来自列出 BTF 数据 blob 的内容。让我们看看如何获取与特定 map 或程序相关的 BTF 信息。
检查 map 和程序的 BTF 数据
如果您想检查与特定 map 关联的 BTF 类型,bpftool 可以帮助您轻松实现。例如,这是 config map 的输出:
bpftool btf dump map name config
[1] TYPEDEF 'u32' type_id=2
[4] STRUCT 'user_msg_t' size=12 vlen=1
'message' type_id=6 bits_offset=0
同样,您可以使用 bpftool btf dump prog <prog Identity> 检查与特定程序相关的 BTF 信息。更多详情请查看手册。
提示
如果您想更好地了解 BTF 类型数据是如何生成和去重的,Andrii Nakryiko 就该主题撰写了另一篇精彩的博客文章。
到此阶段,您应该了解 BTF 如何描述数据结构和函数的格式。用 C 编写的 eBPF 程序需要定义类型和结构体的头文件。让我们看看为 eBPF 程序可能需要的任何内核数据类型生成头文件是多么容易。
生成内核头文件
如果您在支持 BTF 的内核上运行 bpftool btf list,您将看到许多预先存在的 BTF 数据块,如下所示:
$ bpftool btf list
1: name [vmlinux] size 5842973B
2: name [aes_ce_cipher] size 407B
3: name [cryptd] size 3372B
...
此列表中的第一项 ID 为 1,名为 vmlinux,是有关在此(虚拟)计算机上运行的内核使用的所有数据类型、结构体和函数定义的 BTF 信息。(内核需要在启用 CONFIG_DEBUG_INFO_BTF 选项的情况下构建。)
eBPF 程序需要它所引用的任何内核数据结构体和类型的定义。在 CO-RE 出现之前,您通常必须弄清楚 Linux 内核源代码中的许多单独头文件中的哪些包含您感兴趣的结构的定义,但现在有一种更简单的方法,因为支持 BTF 的工具可以从内核包含的 BTF 信息中生成一个合适的头文件。
该头文件通常称为 vmlinux.h,您可以使用 bpftool 生成它,如下所示:
bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
该文件定义了所有内核的数据类型,因此在您的 eBPF 程序源代码中包含此生成的 vmlinux.h 文件可提供您可能需要的任何 Linux 数据结构体的定义。当您将源代码编译为 eBPF 目标文件时,该目标文件将包含与头文件中定义相匹配的 BTF 信息。稍后,当程序在目标计算机上运行时,将其加载到内核的用户空间程序将根据编译时的 BTF 信息和目标机器上运行的内核的 BTF 信息之间的差异进行调整。
自版本 5.4 以来(哪个是支持 BTF 的最旧的 Linux 内核版本?请参阅这个),/sys/kernel/btf/vmlinux 文件形式的 BTF 信息已包含在 Linux 内核中,但也可以为较旧的内核生成 libbpf 可以使用的原始 BTF 数据。换句话说,如果您想在还没有 BTF 信息的目标机器上运行支持 CO-RE 的 eBPF 程序,您可以自己为目标机提供 BTF 数据。 BTFHub 上提供了有关如何生成 BTF 文件的信息,以及各种 Linux 发行版的文件存档。
提示
如果您想更深入地了解这个主题,BTFHub 存储库还包括有关 BTF internals 的进一步阅读。
接下来,让我们看看如何使用 CO-RE 来编写跨内核可移植的 eBPF 程序。
CO-RE eBPF 程序
您应该记得 eBPF 程序在内核中运行。在本章后面,我将展示一些将与内核中运行的代码交互的用户空间代码,但在本节中我将重点关注内核端。
正如您已经看到的,eBPF 程序被编译为 eBPF 字节码,并且(至少在撰写本文时)支持此功能的编译器是用于编译 C 代码的 Clang 或 gcc 以及 Rust 编译器。我将在第 10 章中讨论使用 Rust 的一些选项,但就本章而言,我假设您使用 C 语言编写并使用 Clang 以及 libbpf 库。
在本章的剩余部分,我们将考虑一个名为 hello-buffer-config 的示例应用程序。它与上一章中使用 BCC 框架的 hello-buffer-config.py 示例非常相似,但该版本是用 C 编写的,以使用 libbpf 和 CO-RE。
如果您有基于 BCC 的 eBPF 代码想要迁移到 libbpf,请在 Andrii Nakryiko 的网站上查看出色且全面的指南。 BCC 提供了一些方便的快捷方式,这些快捷方式与使用 libbpf 的处理方式不同;相反,libbpf 提供了自己的一组宏和库函数,以使 eBPF 程序员更轻松。在演示该示例时,我将指出 BCC 和 libbpf 方法之间的一些差异。
提示
您可以在 github.com/lizrice/learning-ebpf 存储库的 chapter5 目录中找到本节附带的示例 C eBPF 程序。
首先我们看一下 hello-buffer-config.bpf.c,它实现了在内核中运行的 eBPF 程序。在本章后面,我将向您展示 hello-buffer-config.c 中的用户空间代码,该代码加载程序并显示输出,就像第 4 章中此示例的 BCC 实现中的 Python 代码所做的那样。
与任何 C 程序一样,eBPF 程序需要包含一些头文件。
头文件
hello-buffer-config.bpf.c 的前几行指定了它需要的头文件:
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#include "hello-buffer-config.h"
这五个文件是 vmlinux.h 文件、libbpf 中的一些头文件以及我自己编写的用于应用程序的头文件。让我们看看为什么这是 libbpf 程序所需的头文件的典型模式。
内核头信息
如果您正在编写引用任何内核数据结构体或类型的 eBPF 程序,最简单的选择是包含本章前面描述的 vmlinux.h 文件。或者,如果您确实想解决这个问题,也可以包含来自 Linux 源代码的单独头文件,或者在您自己的代码中手动定义类型。如果您要使用 libbpf 中的任何 BPF 辅助函数,则需要包含 vmlinux.h 或 linux/types.h 来获取 BPF 辅助函数源代码所引用的 u32、u64 等类型的定义。
vmlinux.h 文件源自内核源代码头文件,但它不包含其中的 #define 定义的值。例如,如果您的 eBPF 程序解析以太网数据包,您可能需要常量定义来告诉您数据包包含什么协议(例如 0x0800 表示它是 IP 数据包,或 0x0806 表示 ARP 数据包)。如果您不包含为内核定义这些值的 if_ether.h 文件,则需要在自己的代码中复制一系列常量值。我不需要在 hello-buffer-config 中定义这些值,但您会在第 8 章中看到另一个与之相关的示例。
来自 libbpf 的头文件
要在 eBPF 代码中使用任何 BPF 辅助函数,您需要包含 libbpf 中提供其定义的头文件。
提示
关于 libbpf 可能有点令人困惑的一件事是它不仅仅是一个用户空间库。您会发现自己在用户空间和 eBPF C 代码中都包含了 libbpf 的头文件。
在写这篇文章的时候,我们经常看到 eBPF 项目将 libbpf 作为一个子模块,并从源代码开始构建/安装——我在本书的示例资源库中就是这样做的。如果您把它作为一个子模块,您只需要在 libbpf/src 目录下运行 make install。我认为不久的将来,libbpf 就会作为一个软件包广泛地出现在常见的 Linux 发行版上,尤其是libbpf 现在已经通过了1.0 版本的里程碑。
用于应用程序的头文件
拥有一个用于应用程序的头文件是很常见的,它定义了应用程序的用户空间和 eBPF 部分使用的任何结构体。在我的示例中,hello-buffer-config.h 头文件定义了 data_t 结构体,我使用该结构将事件数据从 eBPF 程序传递到用户空间。它与您在该代码的 BCC 版本中看到的结构体几乎相同,如下所示:
struct data_t {
int pid;
int uid;
char command[16];
char message[12];
char path[16];
};
与您之前看到的版本的唯一区别是我添加了一个名为 path 的字段。
将此结构体定义放入单独的头文件中的原因是我还将从 hello-buffer-config.c 中的用户空间代码中引用它。在 BCC 版本中,内核和用户空间代码都定义在单个文件中,并且 BCC 在幕后做了一些工作,以使该结构可供 Python 用户空间代码使用。
定义 map
包含头文件后,hello-buffer-config.bpf.c 中源代码的接下来几行定义了用于 map 的结构体,如下所示:
struct {
__uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY);
__uint(key_size, sizeof(u32));
__uint(value_size, sizeof(u32));
} output SEC(".maps");
struct user_msg_t {
char message[12];
};
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 10240);
__type(key, u32);
__type(value, struct user_msg_t);
} my_config SEC(".maps");
这需要的代码行数比我在等效 BCC 示例中所需的代码行数要多!使用 BCC 的话,使用以下宏创建名为 config 的映射:
BPF_HASH(config, u64, struct user_msg_t);
当您不使用 BCC 时,该宏不可用,因此在 C 中您必须手写它。您会看到我使用了 __uint 和 __type。它们与 __array 一起在 bpf/bpf_helpers_def.h 中定义,如下所示:
#define __uint(name, val) int (*name)[val]
#define __type(name, val) typeof(val) *name
#define __array(name, val) typeof(val) *name[]
在基于 libbpf 的程序中,这些宏似乎是约定俗成的,我认为它们使 map 定义更容易阅读。
提示
名称 “config” 与 vmlinux.h 中的定义冲突,因此我在本示例中将 map 重命名为 “my_config”。
eBPF 程序节
使用 libbpf 要求每个 eBPF 程序都用 SEC() 宏标记定义程序类型,如下所示:
SEC("kprobe")
这会在编译的 ELF 对象中产生一个名为 kprobe 的部分,因此 libbpf 知道将其加载为 BPF_PROG_TYPE_KPROBE。我们将在第 7 章中进一步讨论不同的程序类型。
根据程序类型,您还可以使用节名称来指定程序将附加到哪个事件。 libbpf 库将使用此信息自动设置附加,而不是让您在用户空间代码中显式执行此操作。因此,例如,要在基于 ARM 架构的计算机上自动附加到 execve 系统调用的 kprobe,您可以指定如下部分:
SEC("kprobe/__arm64_sys_execve")
这需要您知道该架构上系统调用的函数名称(或者通过查看目标计算机上的 /proc/kallsyms 文件来找出它,该文件列出了所有内核符号,包括函数名称)。但是 libbpf 可以通过 k(ret)syscall 节名称让开发变得更加轻松,它告诉加载程序自动附加到特定架构函数的 kprobe:
SEC("ksyscall/execve")
提示
libbpf 文档中列出了有效的节名称和格式。在过去,对节名称的要求要宽松得多,因此您可能会遇到在 libbpf 1.0 之前编写的 eBPF 程序,其节名称与有效集不匹配。不要让它们迷惑您!
节定义声明了 eBPF 程序应附加到的位置,然后是程序本身。和以前一样,eBPF 程序本身被编写为 C 函数。在示例代码中,它被称为 hello(),它与您在第 4 章中看到的 hello() 函数非常相似。让我们考虑一下先前版本和此处版本之间的差异:
SEC("ksyscall/execve")
// 我利用了 libbpf 中定义的 BPF_KPROBE_SYSCALL 宏,它可以方便地通过名称访问系统调用的参数。对于 execve(),第一个参数是要执行的程序的路径名。 eBPF 程序名称是 hello。
int BPF_KPROBE_SYSCALL(hello, const char *pathname)
{
struct data_t data = {};
struct user_msg_t *p;
data.pid = bpf_get_current_pid_tgid() >> 32;
data.uid = bpf_get_current_uid_gid() & 0xFFFFFFFF;
bpf_get_current_comm(&data.command, sizeof(data.command));
// 由于宏使访问 execve() 的路径名参数变得如此容易,因此我将其包含在发送到 perf 缓冲区输出的数据中。请注意,复制内存需要使用 BPF 辅助函数。
bpf_probe_read_user_str(&data.path, sizeof(data.path), pathname);
// 这里,bpf_map_lookup_elem() 是 BPF 辅助函数,用于在给定键的情况下查找 map 中的值。 BCC 的等效项是 p = my_config.lookup(&data.uid)。 在将C代码传递给编译器之前,BCC 使用底层的 bpf_map_lookup_elem() 函数重写了这个函数。当您使用 libbpf 时,在编译之前不会重写代码,因此您必须直接使用辅助函数。(正常的C语言预处理可以让您做 #define 这样的事情。但是没有像使用 BCC 那样的特殊重写。)
p = bpf_map_lookup_elem(&my_config, &data.uid);
if (p != 0) {
bpf_probe_read_kernel_str(&data.message, sizeof(data.message), p->message);
} else {
bpf_probe_read_kernel_str(&data.message, sizeof(data.message), message);
}
// 这是另一个类似的示例,我直接使用辅助函数 bpf_perf_event_output(),其中 BCC 为我提供了方便的等效函数:output.perf_submit(ctx, &data, sizeof(data))。
bpf_perf_event_output(ctx, &output, BPF_F_CURRENT_CPU, &data, sizeof(data));
return 0;
}
唯一的区别是,在 BCC 版本中,我将消息字符串定义为 hello() 函数中的局部变量。 BCC 不支持全局变量(至少在撰写本文时)。在此版本中,我将其定义为全局变量,如下所示:
char message[12] = "Hello World";
在 chapter4/hello-buffer-config.py 中,hello 函数的定义相当不同,如下所示:
int hello(void *ctx)
BPF_KPROBE_SYSCALL 宏是我提到的 libbpf 中方便添加的宏之一。您不一定要使用宏,但它使开发更轻松。它完成了所有繁重的工作,为传递给系统调用的所有参数提供命名参数。在本例中,它提供一个 pathname 参数,该参数指向一个字符串,该字符串保存将要运行的可执行文件的路径,这是 execve() 系统调用的第一个参数。
如果您仔细观察,您可能会注意到 ctx 变量在我的 hello-buffer-config.bpf.c 源代码中没有显式定义,但尽管如此,我还是能够在向 output perf 缓冲区提交数据时使用它,就像这样:
bpf_perf_event_output(ctx, &output, BPF_F_CURRENT_CPU, &data, sizeof(data));
ctx 变量确实存在,隐藏在 libbpf 中 bpf/bpf_tracing.h 内的 BPF_KPROBE_SYSCALL 宏定义中,您还可以在其中找到一些相关的注释。使用未明确定义的变量可能会有点混乱,但可以访问它是非常有用的。
使用 CO-RE 进行内存访问
用于跟踪的 eBPF 程序通过 bpfprobe_read*() 系列(处理网络数据包的 eBPF 程序无法使用此辅助函数,只能访问网络数据包内存)的 BPF 辅助函数有限制地对内存进行访问。(还有一个 bpf_probe_write_user() 辅助函数,但它仅“用于实验”)。问题在于,正如您将在下一章中看到的,eBPF 验证器通常不会让您像在 C 中那样通过指针简单地读取内存(例如,x = p->y)。(它在某些启用 BTF 的程序类型中是允许的,例如 tp_btf、fentry 和 fexit)
libbpf 库围绕 bpfprobe_read*() 辅助函数提供了 CO-RE 封装器,以利用 BTF 信息并使内存访问调用可以跨不同内核版本移植。下面是 bpf_core_read.h 头文件中定义的一个封装器的示例:
#define bpf_core_read(dst, sz, src) \
bpf_probe_read_kernel(dst, sz, (const void *)__builtin_preserve_access_index(src))
如您所见,bpf_core_read() 直接调用 bpf_probe_read_kernel(),唯一的区别是它用 __builtin_preserve_access_index() 封装了 src 字段。这告诉 Clang 发出 CO-RE 重定位项以及访问内存中该地址的 eBPF 指令。
提示
此 __builtin_preserve_access_index() 指令是“常规”C 代码的扩展,将其添加到 eBPF 还需要更改 Clang 编译器以支持它并发出这些 CO-RE 重定位项。像这样的扩展是一些 C 编译器不能(至少现在不能)生成 eBPF 字节码的原因。在 LLVM 邮件列表中阅读更多关于支持 eBPF CO-RE 所需的 Clang 修改。
正如您将在本章后面看到的那样,CO-RE 重定位项告诉 libbpf 在将 eBPF 程序加载到内核时重新写入地址,以考虑任何 BTF 差异。如果源代码在其包含结构体中的偏移在目标内核上是不同的,重新写入的指令将考虑到这一点。
libbpf 库提供了一个 BPF_CORE_READ() 宏,这样您就可以在一行中编写多个 bpf_core_read() 调用,而不需要为每个指针解引用编写单独的辅助函数调用。例如,如果您想要执行类似 d = a->b->c->d 的操作,您可以编写以下代码:
struct b_t *b;
struct c_t *c;
bpf_core_read(&b, 8, &a->b);
bpf_core_read(&c, 8, &b->c);
bpf_core_read(&d, 8, &c->d);
但可以使用更加紧凑的写法:
d = BPF_CORE_READ(a, b, c, d);
然后,您可以使用 bpf_probe_read_kernel() 辅助函数从指针 d 读取。 Andrii 的指南对此有很好的描述。
许可证定义
正如您从第 3 章中已经了解的那样,eBPF 程序必须声明其许可证。示例代码是这样实现的:
char LICENSE[] SEC("license") = "Dual BSD/GPL";
您现在已经看到了 hello-buffer-config.bpf.c 示例中的所有代码。现在让我们将其编译成目标文件。
编译 eBPF 程序为 CO-RE
在第 3 章中,您看到了将 C 编译为 eBPF 字节码的 Makefile 的摘录。让我们深入研究所使用的选项,看看为什么它们对于 CO-RE/libbpf 程序是必需的。
调试信息
您必须将 -g 标志传递给 Clang,以便它包含 BTF 所必需的调试信息。但是,-g 标志还会将 DWARF 调试信息添加到输出的目标文件中,但 eBPF 程序不需要这样做,因此您可以通过运行以下命令将其删除来减小目标文件的大小:
llvm-strip -g <object file>
优化
Clang 需要 -O2 优化标志(2 级或更高级别)来生成将通过验证器的 BPF 字节码。一个例子是,默认情况下,Clang 将输出 callx <register> 来调用辅助函数,但 eBPF 不支持来自寄存器调用地址。
目标架构
如果您使用 libbpf 定义的某些宏,则需要在编译时指定目标架构。 libbpf 头文件 bpf/bpf_tracing.h 定义了几个特定于平台的宏,例如我在本示例中使用的 BPF_KPROBE 和 BPF_KPROBE_SYSCALL。 BPF_KPROBE 宏可用于附加到 kprobes 的 eBPF 程序,BPF_KPROBE_SYSCALL 是专门用于系统调用 kprobes 的变体。
kprobe 的参数是一个 pt_regs 结构体,它保存 CPU 寄存器内容的副本。由于寄存器是特定于架构的,因此 pt_regs 结构体定义取决于您正在运行的架构。这意味着如果您想使用这些宏,您还需要告诉编译器目标架构是什么。您可以通过设置 -D __TARGET_ARCH_($ARCH) 来完成此操作,其中 $ARCH 是架构名称,如 arm64、amd64 等。
另请注意,如果您不使用宏,则无论如何都需要特定于架构的代码来访问 kprobe 的寄存器信息。
也许“每个架构编译一次,到处运行(compile once per architecture, run everywhere)”有点拗口!
Makefile
以下是用于编译 CO-RE 目标的示例 Makefile 指令(取自本书 GitHub 存储库的 chapter5 目录中的 Makefile):
hello-buffer-config.bpf.o: %.o: %.c
clang \
-target bpf \
-D __TARGET_ARCH_$(ARCH) \
-I/usr/include/$(shell uname -m)-linux-gnu \
-Wall \
-O2 -g \
-c $< -o $@
llvm-strip -g $@
如果您使用示例代码,您应该能够通过在 chapter5 目录中运行 make 来构建 eBPF 目标文件 hello-buffer-config.bpf.o (及其配套的用户空间可执行文件,我将很快介绍)。让我们检查该目标文件以查看它是否包含 BTF 信息。
目标文件中的 BTF 信息
BTF 的内核文档描述了 BTF 数据如何在 ELF 目标文件中编码为两部分:.BTF(包含数据和字符串信息)和 .BTF.ext(涵盖函数和行信息)。您可以使用 readelf 来查看这些部分是否已添加到目标文件中,如下所示:
$ readelf -S hello-buffer-config.bpf.o | grep BTF
[10] .BTF PROGBITS 0000000000000000 000002c0
[11] .rel.BTF REL 0000000000000000 00000e50
[12] .BTF.ext PROGBITS 0000000000000000 00000b18
[13] .rel.BTF.ext REL 0000000000000000 00000ea0
bpftool 实用工具让我们可以检查目标文件中的 BTF 数据,如下所示:
bpftool btf dump file hello-buffer-config.bpf.o
输出结果与您从已加载的程序和 map 中转储 BTF 信息得到的输出结果一样,正如您在本章前面所看到的那样。
让我们看看如何使用此 BTF 信息来允许程序在具有不同内核版本和不同数据结构体的另一台机器上运行。
BPF 重定位(BPF Relocations)
libbpf 库使 eBPF 程序适应其运行的目标内核上的数据结构体布局,即使该布局与编译代码的内核不同。为此,libbpf 需要 Clang 在编译过程中生成的 BPF CO-RE 重定位信息。
您可以通过 linux/bpf.h 头文件中 struct bpf_core_relo 的定义了解有关重定位如何工作的更多信息:
struct bpf_core_relo {
__u32 insn_off;
__u32 type_id;
__u32 access_str_off;
enum bpf_core_relo_kind kind;
};
eBPF 程序的 CO-RE 重定位数据由每个需要重定位的指令的一个结构组成。假设该指令将寄存器设置为结构体内字段的值。该指令的 bpf_core_relo 结构体(由 insn_off 字段标识)对该结构的 BTF 类型(type_id 字段)进行编码,并且还指出了相对于该结构体,字段是如何被访问的(access_str_off)。
正如您刚刚看到的,内核数据结构体的重定位数据是由 Clang 自动生成的,并编码在 ELF 目标文件中。您可以在 vmlinux.h 文件开头附近找到以下行,它会导致 Clang 执行此操作:
#pragma clang attribute push (__attribute__((preserve_access_index)), apply_to = record)
preserve_access_index 属性告诉 Clang 为类型定义生成 BPF CO-RE 重定位。 clang attribute push 部分表示该属性应该应用于所有定义,直到出现在文件末尾的 clang attribute pop 为止。这意味着 Clang 为 vmlinux.h 中定义的所有类有类有类有类型生成重定位信息。
当您加载 BPF 程序时,您可以通过使用 bpftool 并用 -d 标志打开调试信息来查看发生的重定位,就像这样:
bpftool -d prog load hello.bpf.o /sys/fs/bpf/hello
这会产生大量输出,但与重定位相关的部分如下所示:
libbpf: CO-RE relocating [24] struct user_pt_regs: found target candidate [205] struct user_pt_regs in [vmlinux]
libbpf: prog 'hello': relo #0: <byte_off> [24] struct user_pt_regs.regs[0] (0:0:0 @ offset 0)
libbpf: prog 'hello': relo #0: matching candidate #0 <byte_off> [205] struct user_pt_regs.regs[0] (0:0:0 @ offset 0)
libbpf: prog 'hello': relo #0: patched insn #1 (LDX/ST/STX) off 0 -> 0
在此示例中,您可以看到 hello 程序的 BTF 信息中的类型 ID 24 引用了名为 user_pt_regs 的结构体。 libbpf 库已将其与内核结构体(也称为 user_pt_regs)进行匹配,该结构体在 vmlinux BTF 数据集中的类型 ID 为 205。实际上,因为我在同一台机器上编译和加载该程序,所以类型定义是相同的,因此在本例中,距结构开头的偏移量 0 保持不变,并且对指令 #1 的“修补”也不会改变它。
在许多应用程序中,您不会希望要求用户运行 bpftool 来加载 eBPF 程序。相反,您需要将该功能构建到一个专用的用户空间程序中,并将其作为一个可执行文件提供给用户。让我们考虑一下如何编写这个用户空间代码。
CO-RE 用户空间代码
不同编程语言中有几种不同的框架,它们通过在将 eBPF 程序加载到内核时实现重定位来支持 CO-RE。在本章中,我将展示使用 libbpf 的 C 代码;其他选项包括 Go 软件包 cilium/ebpf 和 libbpfgo,以及 Rust 的 Aya。我将在第 10 章中进一步讨论这些选项。
用户空间的 Libbpf 库
libbpf 库是一个用户空间库,如果您用 C 语言编写应用程序的用户空间部分,则可以直接使用。如果您愿意,可以使用此库而无需使用 CO-RE。 Andrii Nakryiko 关于 libbpf-bootstrap 的优秀博客文章中有一个这样的例子。
该库提供了封装 bpf() 和您在第 4 章中遇到的相关系统调用的函数,以执行诸如将程序加载到内核中并将其附加到事件或从用户空间访问 map 信息等操作。使用这些抽象的常规和最简单的方法是通过自动生成的 BPF 框架代码。
BPF 框架(skeletons)
您可以使用 bpftool 从现有的 ELF 文件格式的 eBPF 对象中自动生成框架代码,就像这样:
bpftool gen skeleton hello-buffer-config.bpf.o > hello-buffer-config.skel.h
查看这个框架头文件,您会发现它包含 eBPF 程序和 map 的结构定义,以及几个以名称 hello_buffer_config_bpf__ 开头的函数(基于目标文件的名称)。这些函数管理 eBPF 程序和 map 的生命周期。您不必使用框架代码——如果您愿意,您可以直接调用 libbpf——但自动生成的代码通常会节省您的编写时间。
在生成的框架文件的末尾,您将看到一个名为 hello_buffer_config_bpf__elf_bytes 的函数,它返回 ELF 目标文件 hello-buffer-config.bpf.o 的字节内容。一旦生成了骨架,我们就不再需要该目标文件了。您可以通过运行 make 生成 hello-buffer-config 可执行文件然后删除 .o 文件来测试这一点;可执行文件中包含 eBPF 字节码。
提示
如果您愿意,可以使用 libbpf 函数 bpf_object__open_file 从 ELF 文件加载 eBPF 程序和 map ,而不是使用框架文件中的字节。
以下是使用生成的骨架代码管理本示例中的 eBPF 程序和 map 的生命周期的用户空间代码的概述。为了清楚起见,我省略了一些细节和错误处理,但您可以在 chapter5/hello-buffer-config.c 中找到完整的源代码。
... [other #includes]
// 该文件引用了自动生成的框架头文件,以及我为用户空间和内核代码之间共享的数据结构手动编写的头文件。
#include "hello-buffer-config.h"
#include "hello-buffer-config.skel.h"
... [some callback functions]
int main()
{
struct hello_buffer_config_bpf *skel;
struct perf_buffer *pb = NULL;
int err;
// 此代码设置一个回调函数,该函数将打印 libbpf 生成的任何日志消息。
libbpf_set_print(libbpf_print_fn);
// 这里创建了一个 skel 结构体,它表示 ELF 字节码中定义的所有 map 和程序,并将它们加载到内核中。
skel = hello_buffer_config_bpf__open_and_load();
...
// 程序自动连接到相应的事件。
err = hello_buffer_config_bpf__attach(skel);
...
// 该函数创建一个结构体,用于处理 perf buffer 的输出。
pb = perf_buffer__new(bpf_map__fd(skel->maps.output), 8, handle_event, lost_event, NULL, NULL);
...
// 在这里,perf缓冲区被持续轮询。
while (true) {
err = perf_buffer__poll(pb, 100);
... }
// 这里是清理代码。
perf_buffer__free(pb);
hello_buffer_config_bpf__destroy(skel);
return -err;
}
让我们来详细了解其中的一些步骤。
将程序和 map 加载到内核中
对自动生成函数的第一次调用是:
skel = hello_buffer_config_bpf__open_and_load();
顾名思义,该函数涵盖了两个阶段:打开和加载。"打开"阶段涉及读取 ELF 数据,并将其部分转换为表示 eBPF 程序和 map 的结构体。"加载"阶段将这些 map 和程序加载到内核中,必要时执行 CO-RE 修复。
这两个阶段可以很容易地单独处理,因为骨架代码提供了单独的 name__open() 和 name__load() 函数。这使您可以选择在加载 eBPF 信息之前对其进行操作。这通常是为了在加载程序之前对其进行配置。例如,我可以将计数器全局变量 c 初始化为某个值,如下所示:
skel = hello_buffer_config_bpf__open();
if (!skel) {
// Error ...
}
skel->data->c = 10;
err = hello_buffer_config_bpf__load(skel);
被函数 hello_buffer_config_bpf__open() 返回和被传入到函数 hello_buffer_config_bpf__load() 的数据类型是一个名为 hello_buffer_config_bpf 的结构体,在框架头文件中定义,包含目标文件中定义的所有 map、程序和数据的信息。
提示
框架对象(本例中为 hello_buffer_config_bpf)只是 ELF 字节信息的用户空间表示。一旦它被加载到内核中,如果您再更改对象中的值,它不会对内核端数据产生任何影响。因此,例如,加载后更改 skel->data->c 不会产生任何效果。
访问存在的 map
默认情况下,libbpf 还将创建在 ELF 字节中定义的所有 map,但有时您可能想要编写一个重用现有 map 的 eBPF 程序。您已经在上一章中看到了这样的示例,其中您看到 bpftool 遍历所有 map,查找与给定名称匹配的 map。使用 map 的另一个常见原因是在两个不同的 eBPF 程序之间共享信息,因此只需一个程序创建映射。 bpf_map__set_autocreate() 函数允许您覆盖 libbpf 的自动创建。
那么如何访问现有的 map 呢?map 可以被固定,如果您知道固定的路径,您可以用 bpf_obj_get() 获得一个现有 map 的文件描述符。下面是一个非常简单的示例(在 GitHub 仓库中为 chapter5/find-map.c ):
struct bpf_map_info info = {};
unsigned int len = sizeof(info);
int findme = bpf_obj_get("/sys/fs/bpf/findme");
if (findme <= 0) {
printf("No FD\n");
} else {
bpf_obj_get_info_by_fd(findme, &info, &len);
printf("Name: %s\n", info.name);
}
要尝试此操作,您可以使用 bpftool 创建一个 map,如下所示:
$ bpftool map create /sys/fs/bpf/findme type array key 4 value 32 entries 4 name findme
运行 find-map 可执行文件将打印输出:
Name: findme
让我们回到 hello-buffer-config 示例和框架代码。
附加到事件
示例中的下一个框架函数将程序附加到 execve 系统调用函数:
err = hello_buffer_config_bpf__attach(skel);
libbpf 库自动从该程序的 SEC() 定义中获取附加点。如果您没有完全定义附加点,则有一整套 libbpf 函数,例如 bpf_program__attach_kprobe、bpf_program__attach_xdp 等,用于附加不同的程序类型。
管理事件缓冲区
设置 perf 缓冲区使用的是 libbpf 本身定义的函数,而不是框架中的函数:
pb = perf_buffer__new(bpf_map__fd(skel->maps.output), 8, handle_event, lost_event, NULL, NULL);
您可以看到 perf_buffer__new() 函数将“output” map 的文件描述符作为第一个参数。 handle_event 参数是一个回调函数,当新数据到达 perf 缓冲区时,该函数将被调用;如果 perf 缓冲区中没有足够的空间供内核写入数据条目,则 lost_event 将被调用。在我的示例中,这些函数只是将消息写入屏幕。
最后,程序必须反复轮询 perf 缓冲区:
while (true) {
err = perf_buffer__poll(pb, 100);
...
}
100 是超时时间,单位为毫秒。当数据到达或缓冲区满时,先前设置的回调函数将被调用。
最后,为了清理资源,我释放了 perf 缓冲区并销毁了内核中的 eBPF 程序和 map,如下所示:
perf_buffer__free(pb);
hello_buffer_config_bpf__destroy(skel);
libbpf 中有一整套与 perf_buffer_* 和 ring_buffer_* 相关的函数来帮助您管理事件缓冲区。
如果您编译并运行这个示例 hello-buffer-config 程序,您将看到以下输出(这与您在第 4 章中看到的非常相似):
23664 501 bash Hello World
23665 501 bash Hello World
23667 0 cron Hello World
23668 0 sh Hello World
Libbpf 代码示例
有很多基于 libbpf 的 eBPF 程序的优秀示例,您可以将它们用作编写自己的 eBPF 程序的灵感和指导:
- libbpf-bootstrap 项目旨在通过一组示例程序帮助您起步。
- BCC 项目将许多原始的基于 BCC 的工具迁移到了 libbpf 版本。您可以在 libbpf-tools 目录中找到它们。
总结
CO-RE 使 eBPF 程序可以在与其构建版本不同的内核版本上运行。这极大地提高了 eBPF 的可移植性,并使想要向用户和客户提供可立即投入生产的工具的开发人员的工作变得更加轻松。
在本章中,您了解了 CO-RE 如何通过将类型信息编码到编译的目标文件中,并在指令加载到内核中时使用重定位来重写指令来实现此目的。您还了解了如何用 C 语言编写使用 libbpf 的代码:在内核中运行的 eBPF 程序和基于自动生成的 BPF 框架代码管理这些程序生命周期的用户空间程序。在下一章中,您将了解内核如何验证 eBPF 程序是否可以安全运行。
练习
以下是您可以进一步探索 BTF、CO-RE 和 libbpf 的一些方法:
- 使用 bpftool btf dump map 和 bpftool btf dump prog 分别查看与 map 和程序相关的 BTF 信息。请记住,您可以用多种方式指定单个映射和程序。
- 比较 bpftool btf dump file 和 bpftool btf dump prog 中同一程序的 ELF 对象文件形式以及加载到内核后的输出。它们应该是相同的。
- 检查 bpftool -d prog load hello-buffer-config.bpf.o /sys/fs/bpf/hello 的调试输出。您将看到正在加载的每个部分、检查许可证、发生重定位,以及描述每个 BPF 程序指令的输出。
- 试着根据 BTFHub 上不同的 vmlinux 头文件编译一个 BPF 程序,在 bpftool 的调试输出中查找改变偏移量的重定位。
- 修改 hello-buffer-config.c 程序,以便可以使用 map 为不同的用户 ID 配置不同的消息(类似于第 4 章中的 hello-buffer-config.py 示例)。
- 尝试更改 SEC(); 中的节名称,也许可以更改为您自己的名称。当您将程序加载到内核中时,您应该会看到一个错误,因为 libbpf 无法识别节名称。这说明了 libbpf 如何使用节名称来确定这是什么类型的 BPF 程序。您可以尝试编写自己的附加代码来显式附加到您选择的事件,而不是依赖 libbpf 的自动附加。
第六章 eBPF 验证器
我已经多次提到验证步骤,所以您已经知道,当您将 eBPF 程序加载到内核中时,此验证过程会确保程序是安全的。在本章中,我们将深入探讨验证器如何实现这一目标。
验证会检查程序中每个可能的执行路径并确保每条指令都是安全的。验证器还对字节码进行一些更新以准备执行。在本章中,我将展示一些验证失败的示例,从一个正常工作的示例开始,通过修改使代码对验证器无效。
提示
本章的示例代码位于存储库的 chapter6 目录中,网址为 github.com/lizrice/learning-ebpf。
本章并不试图涵盖验证器可能进行的所有检查。它只是一个概述,并附有示例,帮助您处理在编写自己的 eBPF 代码时可能遇到的验证错误。
需要注意的一点是,验证器工作在 eBPF 字节码上,而不是直接工作在源代码上。字节码依赖于编译器的输出。由于编译器优化等原因,源代码中的变化可能并不总能在字节码中得到您所期望的结果,因此相应地,在验证器的判定中也可能不会得到您所期望的结果。例如,验证器会拒绝无法到达的指令,但编译器可能会在验证器看到这些指令之前将其优化掉。
验证过程
验证器分析程序以评估所有可能的执行路径。它按顺序逐步检查指令,而不是实际执行它们。在进行过程中,它使用一个名为 bpf_reg_state 的结构来跟踪每个寄存器的状态(我在这里指的是在第 3 章中介绍的 eBPF 虚拟机的寄存器)。这个结构体包括一个名为 bpf_reg_type 的字段,用于描述该寄存器中保存的值的类型。有以下几种可能的类型:
- NOT_INIT,表示寄存器尚未设置值。
- SCALAR_VALUE,表示寄存器被设置为一个不代表指针的值。
- 几种 PTRTO* 类型,表示寄存器持有指向某物的指针。例如:
- PTR_TO_CTX:该寄存器保存一个指向作为参数传递给 BPF 程序的上下文的指针。
- PTR_TO_PACKET:该寄存器指向一个网络数据包(在内核中保存为 skb->data )。
- PTR_TO_MAP_KEY 或 PTR_TO_MAP_VALUE:我相信您能猜到它们的含义。
还有其他几种 PTRTO* 类型,您可以在 linux/bpf.h 头文件中找到枚举的完整集。
bpf_reg_state 结构体还跟踪寄存器可能持有的值的范围。验证器使用这些信息来确定是否尝试了无效的操作。
每当验证器遇到一个分支时,必须决定是否按顺序继续执行或跳转到不同的指令,验证器将当前所有寄存器的状态拷贝并压入堆栈,并探索其中一条可能的路径。它继续评估指令,直到到达程序末尾的返回指令(或达到当前指令处理数量的限制,目前为一百万条指令(在很长一段时间内,这个限制是 4,096 条指令,这对 eBPF 程序的复杂性造成了很大的限制。这个限制仍然适用于运行 BPF 程序的非特权用户。)),此时它从堆栈中弹出一个分支以进行下一步评估。如果它发现一个可能导致无效操作的指令,则验证失败。
验证每种可能性的计算成本可能会很高,因此在实践中有一种称为*状态剪枝(state pruning)*的优化方法,可以避免重新评估本质上等效的程序路径。当验证器在程序中工作时,它会记录程序中某些指令处所有寄存器的状态。如果它稍后以寄存器处于匹配的状态到达的相同指令,则无需继续验证该路径的其余部分,因为它已经知道是有效的。
大量的工作投入到优化验证器和修剪过程。验证器过去常常在每个跳转指令之前和之后存储修剪状态,但分析表明,这会导致平均每四个指令左右存储一次状态,并且这些修剪状态中的绝大多数永远不会匹配。事实证明,无论分支如何,每 10 条指令存储一次修剪状态会更有效。
提示
您可以在内核文档中阅读有关验证器如何工作的更多详细信息。
验证器日志
当程序验证失败时,验证器会生成一条日志,显示其如何得出该程序无效的结论。如果您使用 bpftool prog load,验证器日志将输出到 stderr。当您使用 libbpf 编写程序时,可以使用函数 libbpf_set_print() 来设置一个处理程序,该处理程序将显示(或执行其他有用的操作)任何错误。 (您将在本章的 hello-verifier.c 源代码中看到这样的示例。)
提示
如果您确实想深入了解验证器正在做什么,您可以让它生成成功和失败的日志。 hello-verifier.c 文件中也有一个基本示例。它涉及到将保存验证器日志内容的缓冲区传递到 libbpf 调用中,该调用将程序加载到内核中,然后将该日志的内容写入屏幕。
验证器日志包含验证器所做工作的摘要,如下所示:
processed 61 insns (limit 1000000) max_states_per_insn 0 total_states 4 peak_states 4 mark_read 3
在此示例中,验证器处理了 61 条指令,包括可能通过不同路径到达同一指令而多次处理该指令。请注意,一百万的复杂性限制是程序中指令数量的上限;实际上,如果代码中存在分支,验证器将多次处理某些指令。
存储的状态总数(total_states)为 4,对于这个简单的程序来说,这与存储状态的峰值数量(peak_states)相匹配。如果某些状态被修剪,峰值数量可能会低于总数。
日志输出包括验证器分析的 BPF 指令,以及相应的 C 源代码行(如果目标文件是用 -g 标志构建的,则包括调试信息)以及验证器状态信息摘要。以下是与 hello-verifier.bpf.c 中程序的前几行相关的验证器日志的示例摘录:
0: (bf) r6 = r1
# 日志包括源代码行,以便于理解输出结果与源代码的关系。由于在编译步骤中使用了 -g 标志来建立调试信息,因此这些源代码是可用的。
; data.counter = c;
1: (18) r1 = 0xffff800008178000
3: (61) r2 = *(u32 *)(r1 +0)
# 这是在日志中输出一些寄存器状态信息的示例。它告诉我们,在这个阶段,寄存器 1 包含映射值,寄存器 6 保存上下文,寄存器 10 是帧(或栈)指针,用于保存局部变量。
R1_w=map_value(id=0,off=0,ks=4,vs=16,imm=0) R6_w=ctx(id=0,off=0,imm=0) R10=fp0
; c++;
4: (bf) r3 = r2
5: (07) r3 += 1
6: (63) *(u32 *)(r1 +0) = r3
# 这是寄存器状态信息的另一个示例。在这里,您不仅可以看到每个(初始化)寄存器中保存的值的类型,还可以看到寄存器 2 和寄存器 3 的可能值的范围。
R1_w=map_value(id=0,off=0,ks=4,vs=16,imm=0) R2_w=inv(id=1,umax_value=4294967295,
var_off=(0x0; 0xffffffff)) R3_w=inv(id=0,umin_value=1,umax_value=4294967296,
var_off=(0x0; 0x1ffffffff)) R6_w=ctx(id=0,off=0,imm=0) R10=fp0
让我们深入探讨一下这个问题。我刚刚说寄存器 6 保存上下文,验证器日志通过 R6_w=ctx(id=0,off=0,imm=0) 表示了这一点。这是在字节码的第一行中设置的,其中将寄存器 1 复制到寄存器 6。当调用一个 eBPF 程序时,寄存器 1 始终保存传递给程序的上下文参数。为什么要将它复制到寄存器 6 呢?好吧,当调用 BPF 辅助函数时,被调用的参数通过寄存器 1 到 5 传递。辅助函数不会修改寄存器 6 到 9 的内容,因此将上下文保存到寄存器 6 意味着代码可以调用辅助函数而不会丢失上下文信息。
寄存器 0 用于辅助函数的返回值,也用于 eBPF 程序的返回值。寄存器 10 始终保存指向 eBPF 栈帧的指针(并且 eBPF 程序无法修改它)。
我们看一下指令 6 之后寄存器 2 和 3 的寄存器状态信息:
R2_w=inv(id=1,umax_value=4294967295,var_off=(0x0; 0xffffffff))
R3_w=inv(id=0,umin_value=1,umax_value=4294967296,var_off=(0x0; 0x1ffffffff))
寄存器 2 没有最小值,此处以十进制显示的 umax_value 对应于 0xFFFFFFFF,这是在这个 8 字节寄存器中可以保存的最大值(译者注:不是寄存器能保存的最大值,而是寄存器所保存类型的最大值)。换句话说,此时寄存器可以保存任何可能的值。
在指令 4 中,寄存器 2 的内容被复制到寄存器 3 中,然后指令 5 在该值上加 1。因此,寄存器 3 的值可以是 1 或更大。在寄存器 3 的状态信息中可以看到,寄存器 3 的 umin_value 设置为 1,umax_value 为 0xFFFFFFFF。
验证器不仅使用每个寄存器的状态信息,还使用每个寄存器可以包含的值范围的信息来确定程序的可能路径。这也用于我之前提到的状态修剪:如果验证器在代码中处于相同位置,每个寄存器具有相同的类型和可能的值范围,则无需进一步评估此路径。更重要的是,如果当前状态是之前所见状态的子集,它也可以被修剪。
可视化控制流
验证器会探索 eBPF 程序中所有可能的路径,如果您试图调试一个问题,查看这些路径可能会对您有帮助。bpftool 工具可以通过生成 DOT 格式的程序控制流图来帮助实现这一点,然后您可以将其转换为图像格式,像这样:
$ bpftool prog dump xlated name kprobe_exec visual > out.dot
$ dot -Tpng out.dot > out.png
这将产生如图 6-1 所示的可视化控制流表示。
 图 6-1. 控制流图中部分内容(全图可以在本书的 GitHub repo 中 chapter6/ kprobe_exec.png 找到)
图 6-1. 控制流图中部分内容(全图可以在本书的 GitHub repo 中 chapter6/ kprobe_exec.png 找到)
验证辅助函数
不允许从 eBPF 程序直接调用任何内核函数(除非它已注册为 kfunc,您将在下一章中遇到),但 eBPF 提供了许多辅助函数,使程序能够访问内核信息。有一个 bpf-helpers 联机帮助页 试图记录所有这些函数。
不同的辅助函数适用于不同的 BPF 程序类型。例如,辅助函数 bpf_get_current_pid_tgid() 检索当前用户空间进程 ID 和线程 ID,但是从 XDP 程序中调用这个函数是没有意义的,因为 XDP 程序是由网络接口接收到的数据包触发的,不涉及用户空间进程。您可以通过将 hello-verifier.bpf.c 中 hello eBPF 程序的 SEC() 定义从 kprobe 更改为 xdp 来查看此示例。在尝试加载该程序时,验证器输出会给出以下消息:
...
16: (85) call bpf_get_current_pid_tgid#14
unknown func bpf_get_current_pid_tgid#14
unknow func 并不意味着该函数完全未知,只是对于该 BPF 程序类型来说是未知。 (BPF 程序类型是下一章的主题;现在您可以将它们视为适合附加到不同类型事件的程序。)
辅助函数参数
例如,如果您查看 kernel/bpf/helpers.c(源代码中的其他一些地方也定义了辅助函数,例如 [kernel/trace/ bpf_trace.c](kernel/trace/ bpf_trace.c) 和 net/core/filter.c),您会发现每个辅助函数都有一个 bpf_func_proto 结构体,类似于这个辅助函数 bpf_map_lookup_elem() 的例子:
const struct bpf_func_proto bpf_map_lookup_elem_proto = {
.func = bpf_map_lookup_elem,
.gpl_only = false,
.pkt_access = true,
.ret_type = RET_PTR_TO_MAP_VALUE_OR_NULL,
.arg1_type = ARG_CONST_MAP_PTR,
.arg2_type = ARG_PTR_TO_MAP_KEY,
};
该结构体定义了辅助函数的参数和返回值的约束。因为验证器会跟踪每个寄存器中保存的值的类型,所以如果您试图向辅助函数传递错误类型的参数,验证器就会发现。例如,尝试改变 hello 程序中对 bpf_map_lookup_elem() 的调用的参数,如下所示:
p = bpf_map_lookup_elem(&data, &uid);
现在不再传递 &my_config(指向 map 的指针),而是传递 &data(指向局部变量结构体的指针)。从编译器的角度来看这是有效的,因此您可以构建 BPF 目标文件 hello-verifier.bpf.o,但是当您尝试将程序加载到内核中时,您将在验证器日志中看到类似这样的错误:
27: (85) call bpf_map_lookup_elem#1
R1 type=fp expected=map_ptr
这里,fp 代表帧指针,它是栈上存储局部变量的内存区域。寄存器 1 加载了名为 data 的局部变量的地址,但该函数需要一个指向 map 的指针(如前面所示的 bpf_func_proto 结构中的 arg1_type 字段所示)。通过跟踪每个寄存器中存储的值的类型,验证器能够发现这种差异。
检查许可证
如果您使用的 BPF 辅助函数采用了 GPL 许可证,那么验证器还会检查您的程序是否也有与 GPL 兼容的许可。第 6 章示例代码 hello-verifier.bpf.c 中的最后一行定义了“许可证”部分,其中包含 Dual BSD/GPL 字符串。如果删除这一行,验证程序的输出结果将如下所示:
...
37: (85) call bpf_probe_read_kernel#113
cannot call GPL-restricted function from non-GPL compatible program
这是因为 bpf_probe_read_kernel() 辅助函数的 gpl_only 字段设置为 true。该 eBPF 程序之前还调用了其他辅助函数,但它们没有采用 GPL 许可证,因此验证器并不反对使用它们。
BCC 项目维护了一个辅助函数列表,表明它们是否采用了 GPL 许可证。如果您对如何实现辅助函数的更多详细信息感兴趣,请参阅 BPF 和 XDP 参考指南中的相关部分。
检查内存访问
验证器执行大量检查以确保 BPF 程序仅访问它们应该访问的内存。
例如,在处理网络数据包时,仅允许 XDP 程序访问构成该网络数据包的内存位置。大多数 XDP 程序的开头与下面的内容非常相似:
SEC("xdp")
int xdp_load_balancer(struct xdp_md *ctx)
{
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
...
作为上下文信息传递给程序的 xdp_md 结构体描述了接收到的网络数据包。该结构体中的 ctx->data 字段是数据包在内存中的起始位置,而 ctx->data_end 是数据包在内存中的结束位置。验证器将确保程序不会超出这些边界。
例如,hello_verifier.bpf.c 中的以下程序是有效的:
SEC("xdp")
int xdp_hello(struct xdp_md *ctx) {
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
bpf_printk("%x", data_end);
return XDP_PASS;
}
变量 data 和 data_end 非常相似,但验证器足够聪明,可以识别 data_end 与数据包的结束位置相关。您的程序必须检查从数据包中读取的任何值是否超出该位置,并且它不会让您通过修改 data_end 值来“作弊”。尝试在 bpf_printk() 调用之前添加以下行:
data_end++;
验证器会像这样抱怨:
; data_end++;
1: (07) r3 += 1
R3 pointer arithmetic on pkt_end prohibited
在另一个示例中,当访问数组时,您需要确保不可能访问超出该数组范围的索引。在示例代码中,有一个部分从消息数组中读取一个字符,如下所示:
if (c < sizeof(message)) {
char a = message[c];
bpf_printk("%c", a);
}
这是没问题的,因为有明确的检查确保计数变量 c 不会超过消息数组的大小。但是,如果出现如下简单的“偏一”的错误,将会导致程序无法通过验证:
if (c <= sizeof(message)) {
char a = message[c];
bpf_printk("%c", a);
}
验证器将失败并显示类似下面的错误消息:
invalid access to map value, value_size=16 off=16 size=1
R2 max value is outside of the allowed memory range
从这条消息可以很清楚地看出,存在对 map 值的无效访问,因为寄存器 2 可能保存的值对于索引 map 而言太大。如果您正在调试此错误,您需要深入查看日志,以查明源代码中哪一行出现了问题。在发出错误消息之前,日志以如下方式结束(为了清晰起见,我已删除了一些状态信息):
; if (c <= sizeof(message)) {
# 进一步查找寄存器 1 的值,日志显示它的最大值为 12(十六进制 0x0c)。但是,message 被定义为 12 字节字符数组,因此只有索引 0 到 11 在其范围内。由此,您可以看到错误源于 c <= sizeof(message) 的源代码测试。
30: (25) if r1 > 0xc goto pc+10
R0_w=map_value_or_null(id=2,off=0,ks=4,vs=12,imm=0) R1_w=inv(id=0,
umax_value=12,var_off=(0x0; 0xf)) R6=ctx(id=0,off=0,imm=0) ...
; char a = message[c];
# 在指令 31 处,寄存器 2 被设置为内存中的一个地址,然后递增寄存器 1 的值。输出显示这对应于访问 message[c] 的代码行,因此寄存器 2 是理所当然的设置为指向消息数组,然后递增 c 的值,该值保存在寄存器 1 寄存器中。
31: (18) r2 = 0xffff800008e00004
33: (0f) r2 += r1
last_idx 33 first_idx 19
regs=2 stack=0 before 31: (18) r2 = 0xffff800008e00004
regs=2 stack=0 before 30: (25) if r1 > 0xc goto pc+10
regs=2 stack=0 before 29: (61) r1 = *(u32 *)(r8 +0)
# 从错误开始回溯,最后的寄存器状态信息显示寄存器 2 的最大值可为 12。
34: (71) r3 = *(u8 *)(r2 +0)
R0_w=map_value_or_null(id=2,off=0,ks=4,vs=12,imm=0) R1_w=invP(id=0,
umax_value=12,var_off=(0x0; 0xf)) R2_w=map_value(id=0,off=4,ks=4,vs=16,
umax_value=12,var_off=(0x0; 0xf),s32_max_value=15,u32_max_value=15)
R6=ctx(id=0,off=0,imm=0) ...
在步骤 2 中,我根据验证程序在日志中提供的源代码行,推断出一些寄存器与它们所代表的源代码变量之间的关系。您可以通过验证程序日志来检查这是否属实,并且如果代码是在没有调试信息的情况下编译的,您实际上可能必须这样做。鉴于存在调试信息,使用它是有意义的。
message 数组被声明为全局变量,您可能还记得第 3 章中全局变量是使用 map 实现的。这解释了为什么错误消息提到 “对 map 值的访问无效”。
在解引用指针之前检查他们
造成 C 程序崩溃的一种简单方法是当指针具有零值(也称为 null)时解引用该指针。指针指示内存中某个值的存放位置,零不是有效的内存位置。 eBPF 验证器要求在解引用之前检查所有指针,以便不会发生此类崩溃。
hello-verifier.bpf.c 中的示例代码使用以下行查找对于某个用户在 my_config 哈希表 map 中可能存在的自定义消息:
p = bpf_map_lookup_elem(&my_config, &uid);
如果该映射中没有对应于 uid 的条目,则会将 p(指向消息结构 msg_t 的指针)设置为零。下面是一些尝试解引用这个潜在空指针的其他代码:
char a = p->message[0];
bpf_printk("%c", a);
编译正常,但验证器拒绝了它,如下所示:
; p = bpf_map_lookup_elem(&my_config, &uid);
25: (18) r1 = 0xffff263ec2fe5000
27: (85) call bpf_map_lookup_elem#1
# 辅助函数调用的返回值存储在寄存器 0 中。这里,将该值存储在寄存器 7 中。这意味着寄存器 7 现在保存局部变量 p 的值。
28: (bf) r7 = r0
; char a = p->message[0];
# 该指令尝试解引用指针值 p。验证器一直在跟踪寄存器 7 的状态,并且知道它可能保存指向 map 值的指针,或者可能为空。
29: (71) r3 = *(u8 *)(r7 +0)
R7 invalid mem access 'map_value_or_null'
验证器拒绝解引用空指针的尝试,但如果有显式检查,程序将通过,如下所示:
if (p != 0) {
char a = p->message[0];
bpf_printk("%d", cc);
}
一些辅助函数包含了指针检查。例如,如果您查看 bpf-helpers 的联机帮助页,您会发现 bpf_probe_read_kernel() 的函数签名如下:
long bpf_probe_read_kernel(void *dst, u32 size, const void *unsafe_ptr)
该函数的第三个参数为 unsafe_ptr。这是一个 BPF 辅助函数的示例,它通过为您处理检查来辅助编写安全代码。您可以传递一个潜在的空指针,但是只能作为名为 unsafe_ptr 的第三个参数传递,辅助函数在尝试解引用之前将检查它是否为空。
访问上下文
每个 eBPF 程序都会传递一些上下文信息作为参数,但根据程序和附加类型,可能只允许它访问部分上下文信息。例如,跟踪点(tracepoint)程序 接收指向某些跟踪点数据的指针。该数据的格式取决于特定的跟踪点,但它们都以一些公共字段开头,但 eBPF 程序无法访问这些公共字段。只能访问后面的特定于跟踪点的字段。尝试读取或写入错误的字段会导致 invalid bpf_context access 错误。本章末尾的练习中有一个这样的例子。
可运行结束
验证器确保 eBPF 程序可以运行结束;否则,存在无限消耗资源的风险。为此,它对处理的指令总数设置了限制,正如我前面提到的,在本文撰写时,该限制被设定为一百万条指令。该限制被硬编码到内核中;这不是一个可配置的选项。如果验证器在处理这么多指令之前尚未到达 BPF 程序的末尾,则会拒绝该程序。
要创建一个永不结束的程序,一个简单的方法就是编写一个永不结束的循环。让我们看看如何在 eBPF 程序中创建循环。
循环
为了确保运行结束,直到内核版本 5.3 为止(该版本带来了许多针对 BPF 验证器的重要优化和改进,在 LWN 的文章 Bounded loops in BPF for the 5.3 kernel 中有很好的总结。),存在对循环的限制。循环执行相同的指令需要向后跳转到较早的指令,过去验证器不允许这样做。eBPF 程序员通过使用 #pragma unroll 编译器指令来解决这个问题,告诉编译器为每次循环生成一组相同(或非常相似)的字节码指令。这样可以节省程序员输入重复代码的时间,但是在生成的字节码中会看到重复的指令。
从版本 5.3 开始,验证器在其检查所有可能的执行路径的过程中,不仅向前跟踪分支,还会向后跟踪分支。这意味着它可以接受一些循环,只要执行路径保持在一百万条指令的限制范围内。
您可以在示例 xdp_hello 程序中看到循环的示例。通过验证的循环版本如下所示:
for (int i=0; i < 10; i++) {
bpf_printk("Looping %d", i);
}
(成功的)验证器日志将显示它已经沿着该循环的执行路径执行了 10 次。这样做并没有达到一百万条指令的复杂性限制。在本章的练习中,该循环的另一个版本将达到该限制并且验证失败。
在 5.17 版本中,引入了一个新的辅助函数 bpf_loop(),它使验证者不仅可以更轻松地接受循环,而且可以更有效地执行循环。该辅助函数将最大迭代次数作为其第一个参数,并且还传递一个为每次迭代调用的函数。无论该函数被调用多少次,验证器都只需验证一次该函数中的 BPF 指令。该函数可以返回一个非零值来指示不需要再次调用它,这用于在达到所需结果后提前终止循环。
还有一个辅助函数 bpf_for_each_map_elem() ,它为 map 中的每个项目提供了回调函数。
检查返回值
eBPF 程序的返回值存储在寄存器 0 (R0) 中。如果程序使 R0 未初始化,验证器将失败,如下所示:
R0 !read_ok
您可以通过注释掉函数中的所有代码来尝试此操作;例如,将 xdp_hello 示例改成这样:
SEC("xdp")
int xdp_hello(struct xdp_md *ctx) {
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
// bpf_printk("%x", data_end);
// return XDP_PASS;
}
这将使验证器失败。但是,如果您将辅助函数 bpf_printf() 的代码行取消注释,即使源代码没有设置明确的返回值,验证器也不会报错!
这是因为寄存器 0 也用于保存辅助函数的返回值。从 eBPF 程序中的辅助函数返回后,寄存器 0 不再未初始化。
无效指令
正如您从第 3 章中对 eBPF(虚拟)机器的讨论中了解的,eBPF 程序由一组字节码指令组成。验证器检查程序中的指令是否是有效的字节码指令——例如,仅使用已知的操作码。
如果编译器生成了无效的字节码,那将被视为编译器的错误,所以除非您选择(出于某种您自己最了解的原因)手动编写 eBPF 字节码,否则不太可能出现这种类型的验证器错误。然而,近期已经添加了一些新的指令,比如原子操作。如果您编译的字节码使用了这些指令,它们将在旧版本的内核上无法通过验证。
不可到达的指令
校验器还会拒绝接受含有不可达指令的程序。通常情况下,这些指令会被编译器优化掉。
总结
当我最初对 eBPF 产生兴趣时,让代码通过验证器似乎是一种神秘的艺术,看似有效的代码会被拒绝,并出现似乎是随机的错误。随着时间的推移,验证器已经进行了许多改进,在本章中,您已经看到了几个示例,其中验证器日志给出了提示,帮助您找出问题所在。
当您对 eBPF(虚拟)机器如何工作有一个心理模型时,这些提示会更加有帮助。eBPF 在执行 eBPF 程序时,使用一组寄存器来进行临时值存储。验证器跟踪每个寄存器的类型和可能的值范围,以确保 eBPF 程序在运行时是安全的。
如果您尝试编写自己的 eBPF 代码,可能会遇到需要帮助解决验证器错误的情况。eBPF 社区的 Slack 频道是寻求帮助的好地方,许多人也在 StackOverflow 上找到了建议。
练习
以下是导致验证器错误的更多方法。看看是否可以将验证器日志输出与遇到的错误关联起来:
-
在“检查内存访问”一节中,您看到验证器拒绝超出全局变量 message 数组末尾的访问。在示例代码中,有一个部分以类似的方式访问局部变量 data.message:
if (c < sizeof(data.message)) { char a = data.message[c]; bpf_printk("%c", a); }尝试调整代码,通过将 < 替换为 <= 来犯同样的偏一(out-by-one)错误,您将看到一条有关 invalid variable-offset read from stack R2 的错误信息。
-
在示例代码中找到 xdp_hello 中注释掉的循环。尝试添加第一个循环(即取消注释),如下所示:
for (int i=0; i < 10; i++) { bpf_printk("Looping %d", i); }您应该在验证程序日志中看到一系列重复的行,如下所示:
42: (18) r1 = 0xffff800008e10009 44: (b7) r2 = 11 45: (b7) r3 = 8 46: (85) call bpf_trace_printk#6 R0=inv(id=0) R1_w=map_value(id=0,off=9,ks=4,vs=26,imm=0) R2_w=inv11 R3_w=inv8 R6=pkt_end(id=0,off=0,imm=0) R7=pkt(id=0,off=0,r=0,imm=0) R10=fp0 last_idx 46 first_idx 42 regs=4 stack=0 before 45: (b7) r3 = 8 regs=4 stack=0 before 44: (b7) r2 = 11从日志中找出跟踪循环变量 i 的寄存器。
-
现在尝试添加一个会失败的循环,如下所示:
for (int i=0; i < c; i++) { bpf_printk("Looping %d", i); }您应该看到验证器尝试探索此循环以得出结论,但它在完成之前就达到了指令复杂性限制(因为全局变量 c 没有上限)。
-
编写一个附加到跟踪点的程序。 (您可能已经在第 4 章的练习中完成了此操作)提前查看下一章“跟踪点”一节,您可以看到以这些字段开头的上下文参数的结构体定义:
unsigned short common_type; unsigned char common_flags; unsigned char common_preempt_count; int common_pid;创建您自己的结构体版本,该结构体像这样开始,并使程序中的上下文参数成为指向该结构体的指针。在程序中,尝试访问这些字段中的任何一个,并看到验证程序因 invalid bpf_context access 而失败。
第七章 eBPF 程序和附加类型
在前面的章节中,您看到了很多 eBPF 程序的示例,并且可能注意到它们附加在不同类型的事件上。我展示了一些示例附加在 kprobe 上,但在其他示例中,我展示了处理新到达的网络数据包的 XDP 程序。这只是内核中众多附加点中的两个。在本章中,我们将更深入地了解不同类型的程序以及它们如何附加在不同的事件上。
提示
您可以使用 github.com/lizrice/learning-ebpf 上的代码和说明构建并运行本章中的示例。本章的代码位于 chapter7 目录中。
在撰写本文时,某些示例在 ARM 处理器上不受支持。查看 chapter7 目录中的 README 文件以获取更多详细信息和建议。
目前 uapi/linux/bpf.h 中列举了大约 30 种程序类型,以及 40 多种附加类型。附加类型更具体地定义了程序附加的位置;对于许多程序类型,可以从程序类型推断出附加类型,但某些程序类型可以附加到内核中的多个不同的点,因此还必须指定附加类型。
如您所知,本书并不是一本参考手册,因此我不会涵盖每种 eBPF 程序类型。无论如何,当您阅读本书时,很可能已经添加了新类型!
程序上下文参数
所有的 eBPF 程序都接受一个指针类型的上下文参数,但它指向的结构取决于触发它的事件类型。eBPF 程序员需要编写接受相应类型上下文的程序;如果事件是跟踪点而不是网络数据包,将上下文参数视为指向网络数据包是没有意义的。定义不同类型的程序使得验证器能够确保上下文信息得到适当处理,并强制执行关于哪些辅助函数是允许的规则。
所有的 eBPF 程序都接受一个指针作为上下文参数,但它所指向的结构体取决于触发该程序的事件类型。eBPF 程序员需要编写接受适当类型上下文的程序;如果事件是跟踪点而不是网络数据包,那么将上下文参数指向网络数据包是没有意义的。定义不同类型的程序可以让验证器确保上下文信息得到适当处理,并强制执行关于哪些辅助函数是允许的规则。
提示
要深入了解传递给不同 BPF 程序类型的上下文数据的详细信息,请查看 Alan Maguire 在 Oracle 博客上发表的这篇文章。
(译者注:这个链接可能是错误的,作者订正后会修复)
辅助函数和返回值
正如您在上一章中看到的,验证器检查程序使用的所有辅助函数是否与其程序类型兼容。上一章中的示例演示了 XDP 程序中不允许使用 bpf_get_current_pid_tgid() 辅助函数。在接收数据包和触发 XDP 钩子时不涉及用户空间进程或线程,因此调用该函数来发现当前进程和线程 ID 在这种情况下毫无意义。
程序类型还决定了程序返回值的含义。还是以 XDP 为例,返回值会告诉内核,一旦 eBPF 程序处理完数据包,内核将如何处理它——这可能包括将其传递给网络协议栈、丢弃或重定向到其他接口。当 eBPF 程序是通过命中某个特定跟踪点(其中不涉及网络数据包)来触发时,这些返回代码没有任何意义。
有一个关于辅助函数的手册(由于 BPF 子系统的不断发展,手册可能并不完整,这也是合理的)。
您可以使用 bpftool feature 命令获取可用于您的内核版本中每种程序类型的辅助函数的列表。它显示了系统配置并列出了所有可用的程序类型和 map 类型,甚至列出了每种程序类型支持的所有辅助函数。
辅助函数被视为 UAPI(Linux 内核的外部稳定接口)的一部分。因此,一旦在内核中定义了辅助函数,即使内核的内部函数和数据结构发生变化,它在未来也不会改变。
尽管存在在不同内核版本之间可能发生变化的风险,但 eBPF 程序员有需求能够在 eBPF 程序中访问一些内部函数。这可以通过一种称为 BPF 内核函数或 kfuncs 的机制实现。
Kfuncs
Kfuncs 允许将内部内核函数注册到 BPF 子系统中,以便验证器允许它们从 eBPF 程序中调用。对于每个被允许调用特定 kfunc 的 eBPF 程序类型,都会进行相应的注册。
与辅助函数不同,kfunc 不提供兼容性保证,因此 eBPF 程序员必须考虑内核版本之间更改的可能性。
截止到本文撰写时,存在一组"核心" BPF kfuncs,其中包含允许 eBPF 程序获取和释放与任务(tasks)和控制组(cgroups)相关的内核引用的函数。
总结一下,eBPF 程序的类型决定了它可以附加到哪些事件上,进而定义了它所接收的上下文信息的类型。程序类型还定义了它可以调用的辅助函数和 kfuncs 的集合。
程序类型广泛地可分为两类:跟踪(tracing)(或性能(perf))程序类型和与网络相关的程序类型。让我们来看一些例子。
跟踪相关类型(Tracing)
那些附加到 kprobes、tracepoints、raw tracepoints、fentry/fexit probes 和 perf events 的程序,都旨在为内核中的 eBPF 程序提供一种高效的方式,将跟踪信息报告到用户空间中。这些跟踪相关的类型不会影响内核对事件的响应方式(不过,在第 9 章中,这方面已经有了一些创新!)。
这些程序有时被称为 "perf 相关" 程序。例如,bpftool perf 子命令可以让您查看附加到 perf 相关事件的程序,如下所示:
$ sudo bpftool perf show
pid 232272 fd 16: prog_id 392 kprobe func __x64_sys_execve offset 0
pid 232272 fd 17: prog_id 394 kprobe func do_execve offset 0
pid 232272 fd 19: prog_id 396 tracepoint sys_enter_execve
pid 232272 fd 20: prog_id 397 raw_tracepoint sched_process_exec
pid 232272 fd 21: prog_id 398 raw_tracepoint sched_process_exec
上面的输出是我在 chapter7 目录中运行 hello.bpf.c 文件中示例代码时看到的内容,其中附加了不同类型的程序到与 execve() 相关的各种事件上。在本节中,我将讨论所有这些类型,概括的说,这些程序包括:
- 附加到 execve() 系统调用入口点的 kprobe
- 附加到内核函数 do_execve() 的 kprobe
- 位于 execve() 系统调用入口处的跟踪点(tracepoint)
- 在 execve() 处理期间调用的原始跟踪点(raw tracepoint)的两个版本。正如您将在本节中看到的,其中之一是支持 BTF 的版本。
您需要 CAP_PERFMON 和 CAP_BPF 或 CAP_SYS_ADMIN 权限才能使用任何与跟踪相关的 eBPF 程序类型。
Kprobes and Kretprobes
在第一章中,我讨论了 kprobes 的概念。您几乎可以将 kprobe 程序附加到内核的任何位置。(除了内核中出于安全原因不允许使用 kprobes 的少数部分。这些部分列在 /sys/kernel/debug/kprobes/blacklist 中。)通常情况下,它们使用 kprobes 附加到函数的入口,使用 kretprobes 附加到函数的出口,但是您也可以使用 kprobes 附加到函数入口后的某个指定偏移量的指令。如果您选择这样做(到目前为止我见过的唯一例子是 cilium/ebpf 测试套件。),您需要确信您运行的内核版本中有您希望附加到的指令,并且它位于您认为的位置上!附加到内核函数入口和出口点可能相对稳定,但是任意代码行可能在不同版本之间轻易被修改。
提示
在 bpftool perf 列出的示例输出中,您可以看到两个 kprobe 的偏移量均为 0。
当内核被编译时,还存在编译器可能选择对任何给定的内核函数进行"内联"的可能性;也就是说,编译器可能会在调用函数的地方直接插入函数的代码,而不是跳转到函数的入口。如果一个函数被内联了,那么您的 eBPF 程序将无法找到一个 kprobe 的入口点来附加。
将 kprobes 附加到系统调用入口点
本章的第一个 eBPF 示例程序称为 kprobe_sys_execve,它是一个附加到 execve() 系统调用的 kprobe。该函数及其节定义如下:
SEC("ksyscall/execve")
int BPF_KPROBE_SYSCALL(kprobe_sys_execve, char *pathname)
这与您在第 5 章中看到的内容相同。
附加到系统调用的一个原因是它们是稳定的接口,在内核版本之间不会发生变化(跟踪点也是如此,我们很快会介绍)。然而,出于我将在第 9 章中详细介绍的原因,不应该依赖系统调用的 kprobes 来进行安全工具的开发。
将 kprobes 附加到其他内核函数
您可以找到很多基于 eBPF 的工具使用 kprobes 附加到系统调用的示例,但是,如前所述,kprobes 也可以附加到内核中的任何非内联函数。我在 hello.bpf.c 中提供了一个示例,它将 kprobe 附加到函数 do_execve(),其定义如下:
SEC("kprobe/do_execve")
int BPF_KPROBE(kprobe_do_execve, struct filename *filename)
由于 do_execve() 不是系统调用,因此此示例与前面的示例之间存在一些差异:
- SEC 名称的格式与附加到系统调用入口点的先前版本相同,但无需定义特定于平台的变体,因为 do_execve() 与大多数内核函数一样,对所有平台都是通用的。
- 我使用了 BPF_KPROBE 宏而不是 BPF_KPROBE_SYSCALL 宏。目的完全相同,只是后者处理系统调用参数。
- 还有另一个重要的区别:系统调用的路径名参数是指向字符串的指针(char *),但对于此函数,该参数为 filename,它是指向 struct filename 的指针,这是内核中使用的数据结构。
您可能很想知道,我是怎么知道用这种类型来表示这个参数的。我来告诉您。内核中的 do_execve() 函数有如下签名:
int do_execve(struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp)
我选择忽略 do_execve() 参数 __argv 和 __envp,只声明 filename 参数,使用 struct filename * 类型来匹配内核函数的定义。鉴于参数在内存中按顺序排列的方式,可以忽略最后 n 个参数,但如果您想使用后面的参数,则不能忽略列表中较早的参数。
这个 filename 结构体是在内核中定义的,它说明了 eBPF 编程是内核编程的一种方式:我必须查找 do_execve() 的定义才能找到它的参数,以及 struct filename 的定义。 filename->name 指向即将运行的可执行文件的名称。我使用以下行在示例代码中获取该名称:
const char *name = BPF_CORE_READ(filename, name);
bpf_probe_read_kernel(&data.command, sizeof(data.command), name);
概括地说:系统调用 kprobe 的上下文参数是一个结构体,表示用户空间传递给系统调用的值。而 "常规"(非系统调用)kprobe 的上下文参数则也是一个结构体,但表示调用函数的内核代码传递给被调用函数的参数,因此该结构体取决于函数定义。
Kretprobes 与 kprobes 非常相似,不同之处在于它们在函数返回时触发,并且可以访问返回值而不是参数。
Kprobes 和 kretprobes 是一种合理的方式来钩入内核函数,但如果您正在运行较新的内核,还有一个较新的选项值得考虑。
Fentry/Fexit
从内核版本 5.5 开始(适用于 x86 处理器;BPF trampoline 支持在 Linux 6.0 之前不适用于 ARM 处理器),引入了一种更高效的机制来跟踪进入和退出内核函数的方式以及 BPF trampoline 的概念。如果您正在使用足够新的内核,fentry/fexit 现在是首选的跟踪进入或退出内核函数的方法。您可以在 kprobe 或 fentry 类型的程序中编写相同的代码。
在 chapter7/hello.bpf.c 中有一个名为 fentry_execve() 的 fentry 程序示例。我使用了 libbpf 的宏 BPF_PROG 来声明这个 kprobe 的 eBPF 程序,这是另一个方便的封装,可以让您访问类型化的参数而不是通用的上下文指针,但这个版本适用于 fentry、fexit 和 tracepoint 程序类型。定义如下:
SEC("fentry/do_execve")
int BPF_PROG(fentry_execve, struct filename *filename)
节名称告诉 libbpf 在 do_execve() 内核函数的开头附加到 fentry 钩子。正如 kprobe 示例中一样,上下文参数反映了传递到要附加此 eBPF 程序的内核函数的参数。
Fentry 和 fexit 的附加点设计得比 kprobes 更高效,但当您想在函数结束时生成事件时,还有另一个优点:fexit 钩子可以访问函数的输入参数,而 kretprobe 不能。您可以在 libbpf-bootstrap 的示例中看到这样的例子。kprobe.bpf.c 和 fentry.bpf.c 是两个等效的示例,它们都钩入了 do_unlinkat() 内核函数。附加到 kretprobe 的 eBPF 程序具有以下签名:
SEC("kretprobe/do_unlinkat")
int BPF_KRETPROBE(do_unlinkat_exit, long ret)
BPF_KRETPROBE 宏在 do_unlinkat() 函数退出时扩展为一个 kretprobe 程序。eBPF 程序只接收一个参数 ret,它保存着来自do_unlinkat() 函数的返回值。与此相比,看看 fexit 版本:
SEC("fexit/do_unlinkat")
int BPF_PROG(do_unlinkat_exit, int dfd, struct filename *name, long ret)
在此版本中,程序不仅可以访问返回值 ret,还可以访问 do_unlinkat() 的输入参数,即 dfd 和 name。
跟踪点(Tracepoints)
跟踪点是内核代码中标记的位置(我们稍后将介绍用户空间跟踪点)。它们并不专属于 eBPF,长期以来一直被用于生成内核跟踪输出以及类似 SystemTap 的工具中。与使用 kprobes 附加到任意指令不同,跟踪点在内核版本之间是稳定的(尽管较旧的内核可能没有较新版本中添加的全部跟踪点集)。
您可以通过查看 /sys/kernel/tracing/available_events 来查看内核上可用的跟踪子系统集,如下所示:
$ cat /sys/kernel/tracing/available_events
tls:tls_device_offload_set
tls:tls_device_decrypted
...
syscalls:sys_exit_execveat
syscalls:sys_enter_execveat
syscalls:sys_exit_execve
syscalls:sys_enter_execve
...
我的 5.15 版本内核在此列表中定义了超过 1,400 个跟踪点。跟踪点 eBPF 程序的节定义应与其中一项匹配,以便 libbpf 可以自动将其附加到跟踪点。定义的格式为 SEC("tp/tracing subsystem/tracepoint name")。
您将在 chapter7/hello.bpf.c 文件中找到一个匹配 syscalls:sys_enter_execve 跟踪点的示例,当内核开始处理 execve() 调用时,该跟踪点就会被命中。节定义告诉 libbpf 这是一个跟踪点程序,以及它应该附加到的位置,如下所示:
SEC("tp/syscalls/sys_enter_execve")
跟踪点的上下文参数怎么样?我很快就会谈到,BTF 可以在这里帮助我们,但首先让我们考虑一下当 BTF 不可用时需要什么。每个跟踪点都有一个描述从中跟踪的字段的格式。作为示例,以下是 execve() 系统调用入口处的跟踪点的格式:
$ cat /sys/kernel/tracing/events/syscalls/sys_enter_execve/format
name: sys_enter_execve
ID: 622
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:int __syscall_nr; offset:8; size:4; signed:1;
field:const char * filename; offset:16; size:8; signed:0;
field:const char *const * argv; offset:24; size:8; signed:0;
field:const char *const * envp; offset:32; size:8; signed:0;
print fmt: "filename: 0x%08lx, argv: 0x%08lx, envp: 0x%08lx",
((unsigned long)(REC->filename)), ((unsigned long)(REC->argv)),
((unsigned long)(REC->envp))
我利用这些信息在 chapter7/hello.bpf.c 中定义了名为 mysyscalls_enter execve 的匹配结构:
struct my_syscalls_enter_execve {
unsigned short common_type;
unsigned char common_flags;
unsigned char common_preempt_count;
int common_pid;
long syscall_nr;
long filename_ptr;
long argv_ptr;
long envp_ptr;
};
不允许 eBPF 程序访问这些字段中的前四个。如果您尝试访问它们,程序将无法通过验证并显示 invalid bpf_context access 错误。
附加到此跟踪点的示例 eBPF 程序可以使用指向此类型的指针作为其上下文参数,如下所示:
int tp_sys_enter_execve(struct my_syscalls_enter_execve *ctx) {
然后就可以访问这个结构体的内容了。例如,您可以按如下方式获取文件名指针:
bpf_probe_read_user_str(&data.command, sizeof(data.command), ctx->filename_ptr);
使用跟踪点程序类型时,传递给 eBPF 程序的结构体已经被映射为一组原始参数。为了获得更好的性能,您可以使用原始跟踪点 eBPF 程序类型直接访问这些原始参数。节定义应该以 raw_tp(或 raw_tracepoint)开头,而不是 tp。您需要将参数从 __u64 转换为跟踪点结构体使用的任何类型(当跟踪点是系统调用的入口时,这些参数取决于芯片架构)。
支持 BTF 的跟踪点
在前面的示例中,我编写了一个名为 my_syscalls_enter_execve 的结构体来定义 eBPF 程序的上下文参数。但是,当您在 eBPF 代码中定义结构体或解析原始参数时,存在代码可能与其运行的内核不匹配的风险。好消息是,您在第 5 章中遇到的 BTF 解决了这个问题。
借助 BTF 支持,vmlinux.h 中将定义一个与传递给跟踪点 eBPF 程序的上下文结构相匹配的结构。您的 eBPF 程序应使用节定义 SEC("tp_btf/tracepoint name"),其中跟踪点名称是 /sys/kernel/tracing/available_events 中列出的可用事件之一。 Chapter7/hello.bpf.c 中的示例程序如下所示:
在 BTF 支持下,将在 vmlinux.h 中定义一个与传递给跟踪点 eBPF 程序的上下文结构体相匹配的结构体。您的 eBPF 程序应该使用节定义 SEC("tp_btf/tracepoint name"),其中跟踪点名称是 /sys/kernel/tracing/available_events 中列出的可用事件之一。chapter7/hello.bpf.c 中的示例程序如下:
SEC("tp_btf/sched_process_exec")
int handle_exec(struct trace_event_raw_sched_process_exec *ctx)
如您所见,结构名称与跟踪点名称匹配,前缀为 traceevent_raw 。
附加到用户空间
到目前为止,我已经展示了 eBPF 程序附加到内核源代码中定义的事件的示例。在用户空间代码中也有类似的附加点:uprobes 和 uretprobes 用于附加到用户空间函数的入口和出口,以及用户静态定义的跟踪点(user statically defined tracepoints,USDTs),用于附加到应用程序代码或用户空间库中指定的跟踪点。所有这些都使用 BPF_PROG_TYPE_KPROBE 程序类型。
提示
有许多附加到用户空间事件的程序的公共示例。以下是 BCC 项目的一些内容:
- 附加到 u(ret)probe 的 bashreadline 和 funclatency 工具
- BCC 中的 USDT 示例
如果您使用 libbpf,则 SEC() 宏允许您定义这些用户空间 probe 的自动附加点。您可以在 libbpf 文档中找到节名称所需的格式。例如,要将 uprobe 附加到 OpenSSL 中 SSL_write() 函数的开头,您可以使用以下内容定义 eBPF 程序的节:
SEC("uprobe/usr/lib/aarch64-linux-gnu/libssl.so.3/SSL_write")
检测用户空间代码时需要注意一些问题:
- 请注意,本例中共享库的路径是特定于架构的,因此可能需要相应的特定于架构的定义。
- 除非您能控制运行代码的机器,否则您无法知道将安装哪些用户空间库和应用程序。
- 应用程序可能是作为独立的二进制文件构建的,因此不会触发共享库中可能附加的任何 probe。
- 容器通常使用自己的文件系统副本运行,并在其中安装自己的依赖集。容器使用的共享库路径与主机上的共享库路径不同。
- 您的 eBPF 程序可能需要了解编写应用程序所使用的语言。例如,在 C 中,函数的参数通常使用寄存器传递,但在 Go 中,它们使用栈传递(直到 Go 1.17 版本,引入了新的基于寄存器的调用约定。尽管如此,我认为在未来一段时间内将会有使用旧版本构建的 Go 可执行文件流通。),因此保存寄存器信息的 pt_args 结构体可能用处不大。
也就是说,有很多有用的工具使用 eBPF 来检测用户空间应用程序。例如,您可以钩入 SSL 库来追踪加密信息的解密版本——我们将在下一章中更详细地探讨这一点。另一个例子是使用 Parca 等工具对应用程序进行持续性能分析。
LSM
BPF_PROG_TYPE_LSM 程序附加到 Linux 安全模块 (LSM) API,这是内核中的一个稳定接口,最初供内核模块用来强制执行安全策略。正如您将在第 9 章中看到的那样,我将在其中更详细地讨论这一点,eBPF 安全工具现在也可以使用此接口。
BPF_PROG_TYPE_LSM 程序使用 bpf(BPF_RAW_TRACEPOINT_OPEN) 附加,并且在许多方面它们被视为跟踪程序。 BPF_PROG_TYPE_LSM 程序的一个有趣特征是返回值会影响内核的行为方式。非零返回值表示安全检查未通过,因此内核不会继续执行要求完成的任何操作。这与忽略返回值的 perf 相关程序类型有显着差异。
提示
Linux 内核文档涵盖了 LSM BPF 程序。
LSM 程序类型并不是唯一在安全方面发挥作用的类型。您将在下一节中看到的许多与网络相关的程序类型可用于网络安全,以允许或拒绝网络流量或与网络相关的操作。在第 9 章中,您还会看到更多有关 eBPF 用于安全目的的内容。
到目前为止,在本章中您已经了解了一组内核和用户空间跟踪程序类型如何实现整个系统的可见性。下一组要考虑的 eBPF 程序类型是那些让我们挂钩到网络协议栈的程序类型,不仅可以选择观察,还可以影响它处理收发数据的方式。
网络相关类型
有许多不同的 eBPF 程序类型用于在网络消息通过网络协议栈中的各个点时对其进行处理。图 7-1 显示了一些常用程序类型的附加位置。这些程序类型都需要拥有 CAP_NET_ADMIN 和 CAP_BPF 或 CAP_SYS_ADMIN 权限。
传递给这类程序的上下文是相关的网络信息,不过结构体类型取决于内核在网络协议栈中相关位置所拥有的数据。在协议栈底部,数据以第 2 层网络数据包的形式保存,基本上是一系列已经或准备"在网线上"传输的字节。在协议栈的顶层,应用程序使用套接字,内核创建套接字缓冲区来处理从这些套接字发送和接收的数据。
图 7-1. 钩入网络协议栈各个点的 BPF 程序类型
提示
网络分层模型超出了本书的范围,但它在许多其他书籍、文章和培训课程中有所涉及。我在《容器安全》(O'Reilly)的第 10 章中讨论过它。就本书而言,只需要知道第 7 层涵盖了面向应用程序使用的协议,比如 HTTP、DNS 或 gRPC;TCP 在第 4 层;IP 在第 3 层;以太网和 WiFi 在第 2 层。网络协议栈的一个作用是在这些不同的格式之间进行消息转换。
网络相关的程序类型与本章前面提到的跟踪相关程序类型之间的一个最大区别是,它们通常用于自定义联网行为。这涉及两个主要特性:
- 使用 eBPF 程序的返回值来告诉内核如何处理网络数据包——这可能包括正常处理、丢弃或重定向到不同的目的地
- 允许 eBPF 程序修改网络数据包、套接字配置参数等
下一章将举例说明如何利用这些特性构建强大的网络功能,现在先来了解一下 eBPF 程序类型的概况。
套接字(Sockets)
在协议栈顶部,这些网络相关程序类型的一个子集与套接字和套接字操作有关:
- BPF_PROG_TYPE_SOCKET_FILTER 是第一个加入内核的程序类型。从名称上看,您可能已经猜到它是用来过滤套接字的,但不太明显的是,这并不意味着要过滤发送到应用程序或从应用程序发送出来的数据。它是用来过滤套接字数据的副本,并将其发送给可观察性工具(如 tcpdump)。
- 套接字专用于第 4 层(TCP)连接。BPF_PROG_TYPE_SOCK_OPS 允许 eBPF 程序拦截套接字上发生的各种操作和行为,并为该套接字设置 TCP 超时值等参数。套接字只存在于连接的端点(译者注:端点主机,即两端的主机),而不存在于连接可能经过的任何中间件上。
- BPF_PROG_TYPE_SK_SKB 程序与一种特殊的 map 类型结合使用,该 map 类型可保存一组套接字引用,以提供所谓的套接字映射操作(sockmap operations):在套接字层将流量重定向到不同的目的地。
流量控制(Traffic Control)
网络协议栈的下一层是 "TC",即流量控制。Linux 内核中有一整套与 TC 相关的子系统,只要浏览一下 tc 命令的 manpage,您就会知道它的复杂性以及对计算的重要性,它提供了深层次的灵活性和配置方式,以便对网络数据包的处理进行深入控制。
可以附加 eBPF 程序,为入口和出口流量的网络数据包提供自定义过滤器和分类器。这是 Cilium 项目的组成部分之一,我将在下一章介绍一些实例。如果等不及,Quentin Monnet 的博客上也有一些很好的例子。这可以通过编程完成,但您也可以选择使用 tc 命令来操作这类 eBPF 程序。
XDP
在第 3 章中,我们简单介绍了 XDP(eXpress Data Path)eBPF 程序。在那个例子中,我加载了 eBPF 程序,并使用以下命令将其连接到 eth0 接口:
bpftool prog load hello.bpf.o /sys/fs/bpf/hello
bpftool net attach xdp id 540 dev eth0
值得注意的是,XDP 程序附加到特定的接口(或虚拟接口)上,您可能会在不同的接口上附加不同的 XDP 程序。在第 8 章中,您将了解更多关于如何将 XDP 程序卸载到网卡或由网络驱动程序执行的更多信息。
XDP 程序是另一个可以使用 Linux 网络实用工具进行管理的程序实例——在本例中,使用的是 iproute2 的 ip 工具的 link 子命令。加载程序并将其连接到 eth0 的大致等效命令如下:
$ ip link set dev eth0 xdp obj hello.bpf.o sec xdp
该命令从 hello.bpf.o 对象中读取标记为 xdp 节的 eBPF 程序,并将其连接到 eth0 网络接口。现在,该接口的 ip link show 命令包含了附加到该接口的 XDP 程序的一些信息:
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdpgeneric qdisc fq_codel
state UP mode DEFAULT group default qlen 1000
link/ether 52:55:55:3a:1b:a2 brd ff:ff:ff:ff:ff:ff
prog/xdp id 1255 tag 9d0e949f89f1a82c jited
使用 ip link 像这样移除 XDP 程序:
$ ip link set dev eth0 xdp off
在下一章中,您将看到更多有关 XDP 程序及其应用的内容。
流量解析器(Flow Dissector)
流量解析器用于在网络协议栈的各个点从数据包的头部提取详细信息。BPF_PROG_TYPE_FLOW_DISSECTOR 类型的 eBPF 程序可以实现自定义的数据包解析。LWN 的这篇文章对如何在 BPF 中编写网络流量解析器进行了详细介绍。
轻量级隧道
BPFPROG_TYPE_LWT* 程序类型系列可用于在 eBPF 程序中实现网络封装。这些程序类型也可以使用 ip 命令进行操作,但这次涉及的是 route 子命令。在实践中,这些命令并不常用。
Cgroups
eBPF 程序可以附加到 cgroups("control groups"的缩写)。Cgroups 是 Linux 内核中的一个概念,用于限制特定进程或进程组可以访问的资源集。Cgroups 是将一个容器(或一个 Kubernetes pod)与另一个容器隔离开来的机制之一。将 eBPF 程序附加到 cgroup 上,可实现仅适用于该 cgroup 进程的自定义行为。所有进程都和一个 cgroup 关联,包括不在容器内运行的进程。
有多种与 cgroup 相关的程序类型,以及更多可以被附加的钩子。至少在撰写本文时,它们几乎都与网络有关,尽管还有一种 BPF_CGROUP_SYSCTL 程序类型可以附加到影响特定 cgroup 的 sysctl 命令上。
例如,有一些特定于 cgroups 的套接字相关的程序类型,即 BPF_PROG_TYPE_CGROUP_SOCK 和 BPF_PROG_TYPE_CGROUP_SKB 。eBPF 程序可以确定给定的 cgroup 是否被允许执行所请求的套接字操作或数据传输。这对于网络安全策略执行非常有用(我将在下一章中介绍)。套接字程序还可以欺骗调用进程,使其认为它们正在连接到特定的目标地址。
红外控制器(Infrared Controllers)
BPF_PROG_TYPE_LIRC_MODE2 类型的程序可以附加到红外控制器设备的文件描述符,以提供红外协议的解码。在撰写本文时,此程序类型需要 CAP_NET_ADMIN,但我认为这说明了将程序类型划分为与跟踪相关和网络相关并不能完全表达 eBPF 可以处理的各种不同应用程序。
BPF 附加类型
附件类型为程序在系统中可以附加的位置提供了更细粒度的控制。对于某些程序类型,它们可以附加的钩子类型与程序类型之间存在一对一的关联,因此附加类型由程序类型隐式定义。例如,XDP 程序附加到网络协议栈中的 XDP 钩子。对于少数程序类型,还必须指定附加类型。
附件类型会决定哪些辅助函数有效,在某些情况下还会限制对部分上下文信息的访问。本章前面有一个例子,验证器给出了一个 invalid bpf_context access 错误。
您还可以在内核函数 bpf_prog_load_check_attach(定义于 bpf/syscall.c)中查看哪些程序类型需要指定附加类型,以及哪些附加类型有效。
例如,下面是检查 CGROUP_SOCK 程序类型的附加类型的代码:
case BPF_PROG_TYPE_CGROUP_SOCK:
switch (expected_attach_type) {
case BPF_CGROUP_INET_SOCK_CREATE:
case BPF_CGROUP_INET_SOCK_RELEASE:
case BPF_CGROUP_INET4_POST_BIND:
case BPF_CGROUP_INET6_POST_BIND:
return 0;
default:
return -EINVAL;
}
该程序类型可在多个位置附加:创建套接字时、释放套接字时,或在 IPv4 或 IPv6 中完成绑定后。
另一个查找程序有效附加类型列表的地方是 libbpf 文档,您还可以在其中找到 libbpf 可以理解的每个程序和附加类型的节名称。
总结
在本章中,您看到了各种 eBPF 程序类型用于附加到内核中的不同挂钩点。如果您想编写响应特定事件的代码,则需要确定适合挂钩该事件的程序类型。传递到程序中的上下文取决于程序类型,并且内核也可能根据程序的类型对程序的返回值做出不同的响应。
本章的示例代码主要关注与 perf 相关的(跟踪)事件。在接下来的两章中,您将看到用于网络和安全应用的不同 eBPF 程序类型的更多细节。
练习
本章的示例代码包括 kprobe、fentry、tracepoint、原始跟踪点和启用 BTF 的跟踪点程序,它们都附加到同一系统调用的入口处。如您所知,eBPF 跟踪程序可以附加到系统调用之外的许多其他地方。
-
使用 strace 运行示例代码来捕获 bpf() 系统调用,如下所示:
strace -e bpf -o outfile ./hello这将把每个 bpf() 系统调用的信息记录到一个名为"outfile"的文件中。在该文件中查找 BPF_PROG_LOAD 指令,并观察不同程序的 prog_type 字段如何变化。您可以通过跟踪中的 prog_name 字段来识别每个程序,并将其与 chapter7/ hello.bpf.c 中的源代码进行匹配。
-
在 hello.c 中的示例用户空间代码会加载在 hello.bpf.o 中定义的所有程序对象。作为编写 libbpf 用户空间代码的练习,您可以修改示例代码,只加载和附加一个 eBPF 程序(选择您喜欢的任何一个),而不从 hello.bpf.c 中删除这些程序。
-
编写一个 kprobe 和/或 fentry 程序,在调用其他内核函数时触发。您可以查看 /proc/kallsyms,找到您的内核版本中可用的函数。
-
编写一个常规的、原始的或启用 BTF 的跟踪点程序,该程序附加到某个其他内核跟踪点。您可以在 /sys/kernel/tracing/available_events 中找到可用的跟踪点。
-
尝试将多个 XDP 程序附加到给定接口,并确认您不能这样做!您会看到如下所示的错误:
libbpf: Kernel error message: XDP program already attached Error: interface xdpgeneric attach failed: Device or resource busy
第八章 用于网络的 eBPF
正如第 1 章所述,eBPF 的动态特性使我们能够定制内核的行为。在网络世界中,有许多期望的行为取决于应用程序。例如,电信运营商可能需要与电信专用协议(如 SRv6)对接;Kubernetes 环境可能需要与传统应用程序集成;专用硬件负载均衡器可以被在通用硬件上运行的 XDP 程序所替代。eBPF 允许程序员构建网络功能,以满足特定需求,而不必将其强加给所有上游内核用户。
基于 eBPF 的网络工具现在被广泛使用,并已被证明在大规模应用中非常有效。例如,CNCF 的 Cilium 项目使用 eBPF 作为 Kubernetes 网络、独立负载均衡等方面的平台,广泛应用于各种行业的云原生采用者中。(截至撰写本文时,大约 100 个组织已在其 USERS.md 文件中公开宣布使用 Cilium,不过这个数字正在快速增长。 Cilium 还被 AWS、Google 和 Microsoft 采用。)此外,Meta(前 Facebook )也在大规模采用了 eBPF 技术,自 2017 年以来,所有进出 Facebook 的数据包都经过了 XDP 程序的处理。另一个公开且规模巨大的例子是 Cloudflare 使用 eBPF 来进行 DDoS(分布式拒绝服务)保护。
这些都是复杂的、可用于生产的解决方案,它们的细节远远超出了本书的范围,但是通过阅读本章中的示例,您可以了解如何构建此类 eBPF 网络解决方案。
提示
本章的代码示例位于 github.com/lizrice/learning-ebpf 存储库的 chapter8 目录中。
数据包丢弃
有几种涉及丢弃特定传入数据包和允许其他数据包的网络安全功能。这些功能包括防火墙、DDoS 保护和缓解致命数据包(packet-of-death)漏洞:
- 防火墙涉及根据源和目标 IP 地址和/或端口号,逐个数据包决定是否允许数据包。
- DDoS 防护增加了一些复杂性,可能要跟踪来自特定来源的数据包的到达速度,和/或检测数据包内容的某些特征,以确定攻击者或一组攻击者正试图用流量淹没接口。
- 致命数据包漏洞是一类内核漏洞,其中内核在处理按特定方式构造的数据包时未能安全处理。向服务器发送具有这种特定格式的数据包的攻击者可以利用该漏洞,可能导致内核崩溃。传统上,当发现这种内核漏洞时,需要安装修复的新内核,这又需要停机维护。但是,能检测并丢弃这些恶意数据包的 eBPF 程序可以动态安装,在不影响机器上运行的任何应用程序的情况下立即保护主机。
此类功能的决策算法超出了本书的范围,但让我们探讨一下附加到网络接口上的 XDP 钩子的 eBPF 程序如何丢弃某些数据包,这是实现这些用例的基础。
XDP 程序返回值
网络数据包的到达会触发 XDP 程序。程序会检查数据包,检查完毕后,返回值会给出一个决策,指出下一步该如何处理该数据包:
- XDP_PASS 指示数据包应以正常方式发送到网络协议栈(如果没有 XDP 程序就会这样做)。
- XDP_DROP 会立即丢弃数据包。
- XDP_TX 将数据包从其到达的同一接口发送回去。
- XDP_REDIRECT 用于将其发送到不同的网络接口。
- XDP_ABORTED 的结果是丢弃数据包,但它的使用意味着出现错误或出现意外情况,而不是 "正常" 决定丢弃数据包。
对于某些用例(如防火墙),XDP 程序只需决定是继续传递数据包还是丢弃数据包。决定是否丢弃数据包的 XDP 程序大致如下:
SEC("xdp")
int hello(struct xdp_md *ctx) {
bool drop;
drop = <examine packet and decide whether to drop it>;
if (drop)
return XDP_DROP;
else
return XDP_PASS;
}
XDP 程序还可以操纵数据包内容,但这一点我将在本章后面讨论。
每当一个入站网络数据包到达其所连接的接口时,XDP 程序就会被触发。ctx 参数是一个指向 xdp_md 结构体的指针,该结构体保存了传入数据包的元数据。让我们看看如何使用该结构来检查数据包的内容,从而得出决策(译者注:指示下一步如何处理数据包)。
XDP 数据包解析
这是 xdp_md 结构体的定义:
struct xdp_md {
__u32 data;
__u32 data_end;
__u32 data_meta;
/* Below access go through struct xdp_rxq_info */
__u32 ingress_ifindex; /* rxq->dev->ifindex */
__u32 rx_queue_index; /* rxq->queue_index */
__u32 egress_ifindex; /* txq->dev->ifindex */
};
不要被前三个字段的 __u32 类型所迷惑,因为它们实际上是指针。 data 字段指示数据包在内存中的起始位置,data_end 显示数据包结束位置。正如您在第 6 章中看到的,要通过 eBPF 验证器,您必须显式检查对数据包内容的任何读取或写入是否在 data 到 data_end 的范围内。
数据包前面的内存中还有一个区域,位于 data_meta 和 data 之间,用于存储有关该数据包的元数据。该区域可用于协调多个 eBPF 程序,这些程序可能会在数据包通过网络协议栈的不同位置处理同一个数据包。
为了说明解析网络数据包的基础知识,示例代码中有一个名为 ping() 的 XDP 程序,每当检测到 ping (ICMP) 数据包时,它就会简单地生成一行跟踪。这是该程序的代码:
SEC("xdp")
int ping(struct xdp_md *ctx) {
long protocol = lookup_protocol(ctx);
if (protocol == 1) // ICMP
{
bpf_printk("Hello ping");
}
return XDP_PASS;
}
您可以按照以下步骤查看该程序的运行情况:
- 在 chapter8 目录下运行 make。这不仅仅构建代码;它还将 XDP 程序附加到环回接口(称为 lo)。
- 在一个终端窗口中运行 ping localhost。
- 在另一个终端窗口中,通过运行 cat /sys/kernel/tracing/trace_pipe 来观察跟踪管道中生成的输出。
您应该看到大约每秒生成两行跟踪,它们应该是这样的:
ping-26622 [000] d.s11 276880.862408: bpf_trace_printk: Hello ping
ping-26622 [000] d.s11 276880.862459: bpf_trace_printk: Hello ping
ping-26622 [000] d.s11 276881.889575: bpf_trace_printk: Hello ping
ping-26622 [000] d.s11 276881.889676: bpf_trace_printk: Hello ping
ping-26622 [000] d.s11 276882.910777: bpf_trace_printk: Hello ping
ping-26622 [000] d.s11 276882.910930: bpf_trace_printk: Hello ping
每秒有两行跟踪,因为环回接口同时接收 ping 请求和 ping 响应。
您可以轻松修改此代码以丢弃 ping 数据包,方法是添加一行代码以在协议匹配时返回 XDP_DROP,如下所示:
if (protocol == 1) // ICMP
{
bpf_printk("Hello ping");
return XDP_DROP;
}
return XDP_PASS;
如果您尝试这样做,您将看到类似于以下内容的输出每秒仅在跟踪输出中生成一次:
ping-26639 [002] d.s11 277050.589356: bpf_trace_printk: Hello ping
ping-26639 [002] d.s11 277051.615329: bpf_trace_printk: Hello ping
ping-26639 [002] d.s11 277052.637708: bpf_trace_printk: Hello ping
环回接口收到 ping 请求,XDP 程序会丢弃该请求,因此该请求无法通过网络协议栈以得到响应。
在这个 XDP 程序中,大部分工作都是在一个名为 lookup_protocol() 的函数中完成的,该函数用于确定第 4 层协议类型。这只是一个示例,并不是解析网络数据包的高质量实现!但它足以让您了解 eBPF 中的解析是如何工作的。
接收到的网络数据包由一串字节组成,其布局如图 8-1 所示。
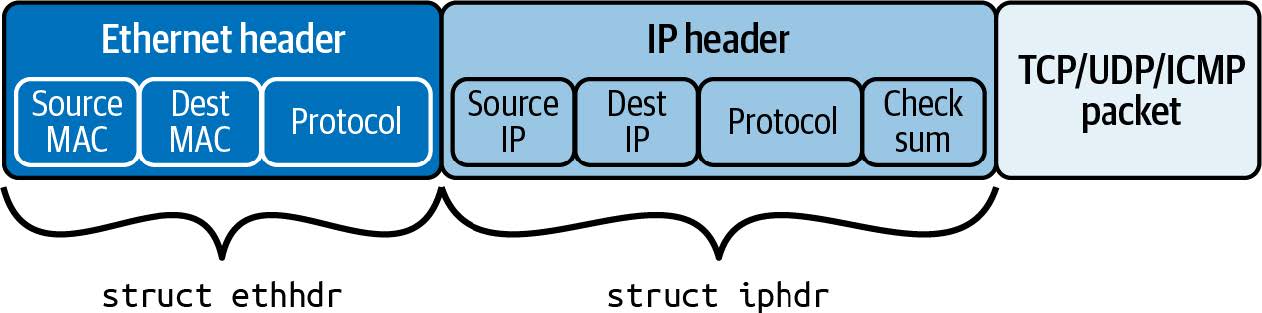
图 8-1. IP 网络数据包的布局,首先是以太网报头,之后是 IP 报头,然后是第 4 层数据
Lookup_protocol() 函数接收 ctx 结构体作为参数,该结构体保存有关此网络数据包在内存中的位置信息,并返回它在 IP 报头中找到的协议类型。代码如下:
unsigned char lookup_protocol(struct xdp_md *ctx)
{
unsigned char protocol = 0;
// 局部变量 data 和 data_end 分别指向网络数据包的开始和结束位置。
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
// 网络数据包应以以太网报头开始。
struct ethhdr *eth = data;
// 但您不能简单地认为这个网络数据包足够大,可以容纳以太网报头!验证器要求您明确检查这一点。
if (data + sizeof(struct ethhdr) > data_end)
return 0;
// 以太网报头包含一个 2 字节字段,告诉我们第 3 层协议。
if (bpf_ntohs(eth->h_proto) == ETH_P_IP)
{
// 如果协议类型显示是 IP 数据包,则 IP 报头紧跟在以太网报头之后。
struct iphdr *iph = data + sizeof(struct ethhdr);
// 您不能假定网络数据包中有足够的空间容纳 IP 报头。验证器再次要求您明确检查。
if (data + sizeof(struct ethhdr) + sizeof(struct iphdr) <= data_end)
// IP 报头包含函数将返回给调用者的协议字节。
protocol = iph->protocol;
}
// Return the protocol of this packet
// 1 = ICMP
// 6 = TCP
// 17 = UDP
return protocol;
}
该程序使用的 bpf_ntohs() 函数可确保两个字节按照主机序排列。网络协议是大端字节序,但大多数处理器是小端字节序,这意味着它们以不同的顺序保存多字节值。此函数将从网络序转换为主机序(如有必要)。每当您从长度超过一个字节的网络数据包中的字段中提取值时,都应该使用此函数。
这里的简单示例展示了几行 eBPF 代码如何对网络功能产生巨大影响。不难想象,关于要传递哪些数据包和要丢弃哪些数据包的更复杂的规则可能会实现我在本节开头描述的功能:防火墙、DDoS 防护和致命数据包漏洞缓解。现在让我们考虑一下,如果在 eBPF 程序中具备修改网络数据包的能力,还能提供哪些更多功能。
负载均衡和转发
XDP 程序不仅限于检查数据包的内容。它们还可以修改数据包的内容。让我们考虑一下,如果您想建立一个简单的负载均衡器,将发送到特定 IP 地址的数据包传输到能够处理这些请求的多个后端服务器,会涉及到哪些问题。
GitHub 仓库(本示例基于我在 2021 年 eBPF 峰会上发表的题为 "从零开始创建负载均衡器" 的演讲。在 15 分钟内构建 eBPF 负载均衡器!)中有一个这样的示例。这里的设置是一组在同一主机上运行的容器。有一个客户端、一个负载均衡器和两个后端,每个后端都在自己的容器中运行。如图 8-2 所示,负载均衡器接收来自客户端的流量并将其转发到两个后端容器之一。
图 8-2. 负载均衡器设置示例
负载均衡功能作为附加到负载均衡器 eth0 网络接口的 XDP 程序来实现。该程序的返回代码是 XDP_TX,表示数据包应从其进入的接口发送回。但在此之前,程序必须更新数据包报头中的地址信息。
虽然我认为它作为学习练习很有用,但这个示例代码距离生产就绪还非常非常远。例如,它使用硬编码地址,假定 IP 地址的精确设置如图 8-2 所示。它假设它收到的唯一 TCP 流量是来自客户端的请求或对客户端的响应。它还利用 Docker 设置虚拟 MAC 地址的方式进行欺骗,使用每个容器的 IP 地址作为每个容器的虚拟以太网接口的 MAC 地址的最后四个字节。从容器的角度来看,该虚拟以太网接口称为 eth0。
虽然我认为这是一个很有用的学习练习,但这个示例代码与真正的生产环境相差甚远。例如,它使用硬编码的地址,假设 IP 地址的设置与图 8-2 中显示的完全相同。它还假设它所接收到的 TCP 流量仅限于来自客户端的请求或针对客户端的响应。此外,它利用 Docker 设置虚拟 MAC 地址的方式来取巧,使用每个容器的 IP 地址作为每个容器虚拟以太网接口的 MAC 地址的最后四个字节。从容器的角度来看,该虚拟以太网接口被称为 eth0。
以下是示例负载均衡器代码中的 XDP 程序:
SEC("xdp_lb")
int xdp_load_balancer(struct xdp_md *ctx)
{
// 该函数的第一部分实际上与前面的示例相同:它定位数据包中的以太网报头,然后定位 IP 报头。
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
struct ethhdr *eth = data;
if (data + sizeof(struct ethhdr) > data_end)
return XDP_ABORTED;
if (bpf_ntohs(eth->h_proto) != ETH_P_IP)
return XDP_PASS;
struct iphdr *iph = data + sizeof(struct ethhdr);
if (data + sizeof(struct ethhdr) + sizeof(struct iphdr) > data_end)
return XDP_ABORTED;
// 这次它将只处理 TCP 数据包,将收到的任何其他数据包传递给网络协议栈,就好像什么也没发生一样。
if (iph->protocol != IPPROTO_TCP)
return XDP_PASS;
// 这里要检查源 IP 地址。如果该数据包不是来自客户端,我就认为它是发给客户端的响应。
if (iph->saddr == IP_ADDRESS(CLIENT))
{
// 此代码在后端 A 和 B 之间生成伪随机选择。
char be = BACKEND_A;
if (bpf_get_prandom_u32() % 2)
be = BACKEND_B;
// 更新目标 IP 和 MAC 地址,以匹配所选的后端...
iph->daddr = IP_ADDRESS(be);
eth->h_dest[5] = be;
}
else
{
// ......或者,如果这是来自后端的响应(如果不是来自客户端,这里就是假设),则会更新目标 IP 和 MAC 地址以匹配客户端。
iph->daddr = IP_ADDRESS(CLIENT);
eth->h_dest[5] = CLIENT;
}
// 无论该数据包流向何处,都需要更新源地址,以便该数据包看起来像是源自负载均衡器。
iph->saddr = IP_ADDRESS(LB);
eth->h_source[5] = LB;
iph->check = iph_csum(iph);
return XDP_TX;
}
IP 报头包含根据其内容计算的校验和,并且由于源 IP 地址和目标 IP 地址均已更新,因此还需要重新计算并替换此数据包中的校验和。
提示
由于这是一本关于 eBPF 而不是网络的书,我没有深入研究细节,例如为什么 IP 和 MAC 地址需要更新,或者如果不更新会发生什么。如果您有兴趣,我在 eBPF 峰会演讲的 YouTube 视频中详细介绍这一点,我最初是在该视频中编写了此示例代码。
与前面的例子一样,Makefile 文件不仅包含了编译代码的说明,还包含了使用 bpftool 加载 XDP 程序并将其附加到接口上的说明,就像这样:
xdp: $(BPF_OBJ)
bpftool net detach xdpgeneric dev eth0
rm -f /sys/fs/bpf/$(TARGET)
bpftool prog load $(BPF_OBJ) /sys/fs/bpf/$(TARGET)
bpftool net attach xdpgeneric pinned /sys/fs/bpf/$(TARGET) dev eth0
这条 make 指令需要在负载均衡器容器内运行,这样 eth0 才能对应其虚拟以太网接口。这就引出了一个有趣的问题:eBPF 程序被加载到内核中,而内核只有一个;但附加点可能在特定的网络命名空间内,并且只能在该网络命名空间内可见。(如果您想探索这一点,请尝试 eBPF Summit 2022 的 CTF Challenge 3。我不会在书中剧透,但您可以在 Duffie Cooley 和我提供的攻略中看到解决方案。)
XDP 卸载(XDP Offloading)
XDP 的概念起源于一次关于猜测的讨论,讨论了如果您能够在网络卡上运行 eBPF 程序,在数据包进入内核的网络协议栈之前就能对其进行决策,这将会有多么有用。(请参阅 Daniel Borkmann 的演讲 "Little Helper Minions for Scaling Microservices",其中包括 eBPF 的历史,他在演讲中讲述了这件趣事。)有一些网卡支持完整的 XDP 卸载功能,它们确实可以在自己的处理器上运行 eBPF 程序来处理传入的数据包。这在图 8-3 中有所说明。
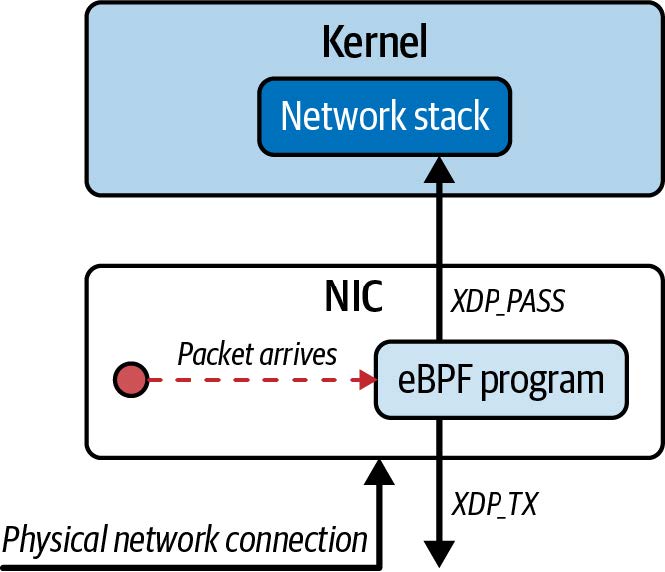
图 8-3. 支持 XDP 卸载的网卡可以处理、丢弃和重传数据包,而不需要主机 CPU 做任何工作
这就意味着,从同一物理接口丢弃或重定向回来的数据包(如本章前面的数据包丢弃和负载均衡示例),主机内核永远不会看到,主机上的 CPU 周期也不会用于处理这些数据包,因为所有工作都是在网卡上完成的。
即使物理网卡不支持完整的 XDP 卸载,许多 NIC 驱动程序也支持 XDP 钩子,这可以最大限度地减少 eBPF 程序处理数据包所需的内存复制。(Cilium 在 BPF 和 XDP 参考指南中维护了支持 XDP 的驱动程序列表。)
这可以带来显著的性能优势,并使负载均衡等功能在通用硬件上非常高效地运行。(Ceznam 在这篇博文中分享了其团队在试用基于 eBPF 的负载平衡器时看到的性能提升数据。)
您已经了解了如何使用 XDP 处理入站网络数据包,并在它们到达计算机时尽快访问它们。 eBPF 还可用于处理网络协议栈中其他点的流量,无论其流向如何。让我们继续思考 TC 子系统中附加的 eBPF 程序。
流量控制(TC)
我在上一章中提到过流量控制。当网络数据包到达这一附加点时,它将以 sk_buff 的形式存在于内核内存中。在 TC 子系统中附加的 eBPF 程序会接收一个指向 sk_buff 结构体的指针作为上下文参数。
提示
您可能想知道为什么 XDP 程序不在其上下文中使用相同的结构。答案是,XDP 钩子发生在网络数据到达网络协议栈之前以及 sk_buff 结构体建立之前。
TC 子系统旨在调节网络流量的调度方式。例如,您可能希望限制每个应用程序的可用带宽,以便它们都能获得公平的机会。但在调度单个数据包时,带宽并不是一个非常有意义的术语,因为它是指发送或接收的平均数据量。某个特定的应用程序可能非常容易有突发流量,或者另一个应用程序可能对网络延迟非常敏感,因此 TC 可以对数据包的处理方式和优先级进行更精细的控制。(要更完整地了解 TC 及其概念,我推荐 Quentin Monnet 的文章“Understanding tc ‘direct action’ mode for BPF”。)
引入 eBPF 程序是为了对 TC 内使用的算法进行自定义控制。但由于 eBPF 程序具有操纵、丢弃或重定向数据包的功能,因此也可用作复杂网络行为的构建模块。
网络协议栈中给定的网络数据流有两个方向:入口(ingress,从网络接口进入)或出口(egress,向网络接口输出)。eBPF 程序可以附加在任一方向上,并只影响该方向上的流量。与 XDP 不同的是,可以附加多个 eBPF 程序,并按顺序进行处理。
传统的流量控制分为分类器和单独的操作,分类器根据某些规则对数据包进行分类,而操作则根据分类器的输出决定如何处理数据包。可以有一系列分类器,它们都被定义为 qdisc 或排队规则(queuing discipline)的一部分。
eBPF 程序是作为分类器附加在程序上的,但它们也可以决定在同一程序中采取什么行动。该操作由程序的返回值(其值在 linux/pkt_cls.h 中定义)表示:
- TC_ACT_SHOT 告诉内核丢弃数据包。
- TC_ACT_UNSPEC 的行为就像 eBPF 程序尚未在此数据包上运行一样(因此它将被传递到序列中的下一个分类器(如果有))。
- TC_ACT_OK 告诉内核将数据包传递到网络协议栈的下一层。
- TC_ACT_REDIRECT 将数据包发送到不同网络设备的入口或出口路径。
让我们来看几个可在 TC 中附加程序的简单示例。第一个程序只是生成一行跟踪信息,然后告诉内核丢弃数据包:
int tc_drop(struct __sk_buff *skb) {
bpf_trace_printk("[tc] dropping packet\n");
return TC_ACT_SHOT;
}
现在让我们考虑如何仅丢弃数据包的子集。此示例丢弃 ICMP (ping) 请求数据包,与本章前面看到的 XDP 示例非常相似:
int tc(struct __sk_buff *skb) {
void *data = (void *)(long)skb->data;
void *data_end = (void *)(long)skb->data_end;
if (is_icmp_ping_request(data, data_end)) {
struct iphdr *iph = data + sizeof(struct ethhdr);
struct icmphdr *icmp = data + sizeof(struct ethhdr) + sizeof(struct iphdr);
bpf_trace_printk("[tc] ICMP request for %x type %x\n", iph->daddr, icmp->type);
return TC_ACT_SHOT;
}
return TC_ACT_OK;
}
sk_buff 结构体具有指向数据包数据开始和结束的指针,这与 xdp_md 结构体非常相似,数据包的解析过程也大致相同。同样,要通过验证,必须明确检查对数据的任何访问是否在 data 和 data_end 之间的范围内。
您可能会想,既然 XDP 已经实现了同样的功能,为什么还要在 TC 层实现这样的功能呢?一个很好的理由是,您可以使用 TC 程序处理出口流量,而 XDP 只能处理入口流量。另一个原因是,由于 XDP 会在数据包到达时立即触发,因此此时并不存在与数据包相关的 sk_buff 内核数据结构。如果 eBPF 程序对内核为该数据包创建的 sk_buff 感兴趣或想对其进行操作,那么 TC 连接点是合适的。
提示
要更好地理解 XDP 与 TC eBPF 程序之间的区别,请阅读 Cilium 项目中《BPF 和 XDP 参考指南》中的 "程序类型 "部分。
现在,让我们来看一个不只是丢弃某些数据包的例子。这个例子可以识别收到的 ping 请求,并作出 ping 响应:
int tc_pingpong(struct __sk_buff *skb) {
void *data = (void *)(long)skb->data;
void *data_end = (void *)(long)skb->data_end;
// is_icmp_ping_request() 函数解析数据包,不仅检查它是否是 ICMP 报文,还检查它是否是 echo (ping) 请求。
if (!is_icmp_ping_request(data, data_end)) {
return TC_ACT_OK;
}
struct iphdr *iph = data + sizeof(struct ethhdr);
struct icmphdr *icmp = data + sizeof(struct ethhdr) + sizeof(struct iphdr);
// 由于该函数将向发送方发送响应,因此需要交换源地址和目标地址。(如果您想了解其中的细节,可以阅读示例代码,其中还包括更新 IP 头校验和)。
swap_mac_addresses(skb);
swap_ip_addresses(skb);
// Change the type of the ICMP packet to 0 (ICMP Echo Reply) (was 8 for ICMP Echo request)
// 通过更改 ICMP 标头中的类型字段,将其转换为回显响应。
update_icmp_type(skb, 8, 0);
// Redirecting a clone of the modified skb back to the interface it arrived on
// 该辅助函数通过接收数据包的接口 (skb- >ifindex),将数据包的克隆发送回去。
bpf_clone_redirect(skb, skb->ifindex, 0);
// 由于辅助函数在发送响应之前克隆了数据包,因此原始数据包应被丢弃。
return TC_ACT_SHOT;
}
在正常情况下,ping 请求会由内核的网络协议栈稍后处理,但这个小例子演示了如何用 eBPF 实现更广泛地替代网络功能。
如今,许多网络功能都是由用户空间服务处理的,但如果可以用 eBPF 程序来替代,很可能会大大提高性能。在内核中处理的数据包不需要通过协议栈的其他部分;数据包不需要传输到用户空间进行处理,而响应也不需要传回内核。更重要的是,两者可以并行运行——eBPF 程序可以为任何需要复杂处理而自己又无法处理的数据包返回 TC_ACT_OK,这样它就可以正常传递到用户空间服务。
对我来说,这是在 eBPF 中实现网络功能的一个重要方面。随着 eBPF 平台的发展(例如,最近的内核允许一百万条指令的程序),在内核中实现越来越复杂的网络功能成为可能。eBPF 中尚未实现的部分仍可由内核中的传统协议栈或用户空间处理。随着时间的推移,越来越多的功能可以从用户空间转移到内核中,eBPF 的灵活性和动态性意味着您不必等待它们成为内核发行版的一部分。您可以立即加载 eBPF 实现,就像我在第 1 章中讨论的那样。
我将在 "eBPF 和 Kubernetes 网络"节中再次介绍网络功能的实现。但首先,让我们考虑一下 eBPF 支持的另一种使用场景:检查加密流量的解密内容。
数据包加密和解密
如果应用程序使用加密技术来保护发送或接收的数据,那么在加密之前或解密之后,数据都会处于明文状态。回想一下,eBPF 可以将程序附加到机器上的几乎任何地方,所以如果您能挂钩到一个数据正在传输但尚未加密的点,或者刚刚解密后的点,这将允许您的 eBPF 程序观察到明文数据。无需提供任何证书来解密流量,就像传统的 SSL 检查工具一样。
在许多情况下,应用程序会使用 OpenSSL 或 BoringSSL 等用户空间库来加密数据。在这种情况下,流量在到达套接字时已经加密,套接字是网络流量的用户空间/内核边界。如果您想以未加密的形式追踪这些数据,可以使用附加到用户空间代码正确位置的 eBPF 程序。
用户空间 SSL 库
追踪加密数据包解密内容的一种常见方法是挂钩调用 OpenSSL 或 BoringSSL 等用户空间库。使用 OpenSSL 的应用程序通过调用 SSL_write() 函数发送加密数据,并使用 SSL_read() 检索通过网络接收的加密明文数据。通过 uprobes 将 eBPF 程序挂钩到这些函数中,应用程序可以在加密之前或解密之后以明文方式观察使用此共享库的任何应用程序中的数据。并且不需要任何密钥,因为应用程序已经提供了这些密钥。
在 Pixie 项目中,有一个名为 openssl-tracer 的相当简单的示例,其中的 eBPF 程序位于一个名为 openssl_tracer_bpf_funcs.c 的文件中。(该示例还附有一篇博文,网址是 https://blog.px.dev/ebpf-openssl-tracing。)下面是该代码中使用 perf 缓冲区向用户空间发送数据的部分(与本书前面的示例类似):
static int process_SSL_data(struct pt_regs* ctx, uint64_t id, enum ssl_data_event_type type, const char* buf) {
...
bpf_probe_read(event->data, event->data_len, buf);
tls_events.perf_submit(ctx, event, sizeof(struct ssl_data_event_t));
return 0;
}
您可以看到,使用辅助函数 bpf_probe_read(),将 buf 中的数据读入一个 event 结构体,然后该 event 结构体被提交到 perf 缓冲区。
如果这些数据被发送到用户空间,那么我们有理由认为这一定是未加密格式的数据。那么,这个数据缓冲区是从哪里获得的呢?您可以通过查看 process_SSL_data() 函数的调用位置来解决这个问题。它在两个地方被调用:一个是读取数据的地方,另一个是写入数据的地方。图 8-4 展示了读取以加密形式到达本机的数据时发生的情况。
读取数据时,您需要向 SSL_read() 提供一个指向缓冲区的指针,当函数返回时,该缓冲区将包含未加密的数据。与 kprobes 类似,函数的输入参数(包括缓冲区指针)只有附加到入口点的 uprobe 才能使用,因为它们所在的寄存器很可能在函数执行期间被覆盖。直到函数退出时,缓冲区中的数据才可用,此时您可以使用 uretprobe 读取数据。
图 8-4. eBPF 程序在 SSL_read() 的入口和出口处挂钩 uprobes,以便可以从缓冲区指针读取未加密的数据
因此,本例遵循了 kprobes 和 uprobes 的常见模式(如图 8-4 所示),即入口探针使用 map 临时存储输入参数,出口探针可以从中获取这些参数。让我们从附加在 SSL_read() 开始的 eBPF 程序开始,看看实现这一功能的代码:
// Function signature being probed:
// int SSL_read(SSL *s, void *buf, int num)
int probe_entry_SSL_read(struct pt_regs* ctx) {
uint64_t current_pid_tgid = bpf_get_current_pid_tgid();
...
// 如该函数的注释所述,缓冲区指针是传入 SSL_read() 函数的第二个参数,该探针将附加到该函数。PT_REGS_PARM2 宏从上下文中获取该参数。
const char* buf = (const char*)PT_REGS_PARM2(ctx);
// 缓冲区指针存储在哈希映射中,其键是当前进程和线程 ID,在函数开始时使用辅助函数 bpf_get_current_pid_tgif()获取。
active_ssl_read_args_map.update(¤t_pid_tgid, &buf);
return 0;
}
这是出口探针的相应程序:
int probe_ret_SSL_read(struct pt_regs* ctx) {
uint64_t current_pid_tgid = bpf_get_current_pid_tgid();
...
// 查找当前进程和线程 ID 后,以此为键从哈希 map 中获取缓冲区指针。
const char** buf = active_ssl_read_args_map.lookup(¤t_pid_tgid);
if (buf != NULL) {
// 如果这不是空指针,则调用 process_SSL_data(),也就是您之前看到的那个函数,它使用 perf 缓冲区将数据从该缓冲区发送到用户空间。
process_SSL_data(ctx, current_pid_tgid, kSSLRead, *buf);
}
// 清理哈希 map 中的条目,因为每个入口调用都应与出口配对。
active_ssl_read_args_map.delete(¤t_pid_tgid);
return 0;
}
本示例展示了如何跟踪用户空间应用程序收发的加密数据的明文版本。跟踪本身附在用户空间库上,而且不能保证每个应用程序都会使用给定的 SSL 库。BCC 项目包含一个名为 sslsniff 的工具,它也支持 GnuTLS 和 NSS。但是,如果某人的应用程序使用其他加密库(甚至,如果他们选择了 "自行加密"),则 uprobes 根本就没有正确的挂钩位置,并且这些跟踪工具将无法工作。
还有更常见的原因导致这种基于 uprobe 的方法无法成功。与内核(每个 [虚拟] 机器只有一个内核)不同,用户空间库代码可能有多个副本。如果您使用的是容器,那么每个容器都可能有自己的一套所有库依赖关系。您可以挂钩这些库中的 uprobe,但您必须为要跟踪的特定容器指定正确的副本。另一种可能性是,应用程序可以静态链接,而不是使用共享的动态链接库,这样它就是一个独立的可执行文件。
eBPF 和 Kubernetes 网络
虽然这本书不是关于 Kubernetes 的,但 eBPF 在 Kubernetes 网络中的应用非常广泛,它很好地说明了如何使用该平台来定制网络协议栈。
在 Kubernetes 环境中,应用程序部署在 pod 中。每个 pod 由一个或多个容器组成,这些容器共享内核命名空间和 cgroup,从而使 pod 相互隔离,并与运行它们的主机隔离。
在 Kubernetes 环境中,应用程序被部署在 Pod 中。每个 Pod 都是一组一个或多个共享内核命名空间和 cgroup 的容器,将 Pod 彼此隔离并与其运行的主机隔离。
特别是(就本章而言),一个 pod 通常有自己的网络命名空间和 IP 地址。(pod 可以在主机的网络命名空间中运行,这样它们就可以共享主机的 IP 地址,但通常不会这样做,除非 pod 中运行的应用程序有充分的理由需要这样做。)这意味着内核为该命名空间设置了一套网络协议栈结构,与主机和其他 pod 的网络协议栈结构分开。如图 8-5 所示,pod 通过虚拟以太网与主机相连,并分配了自己的 IP 地址。
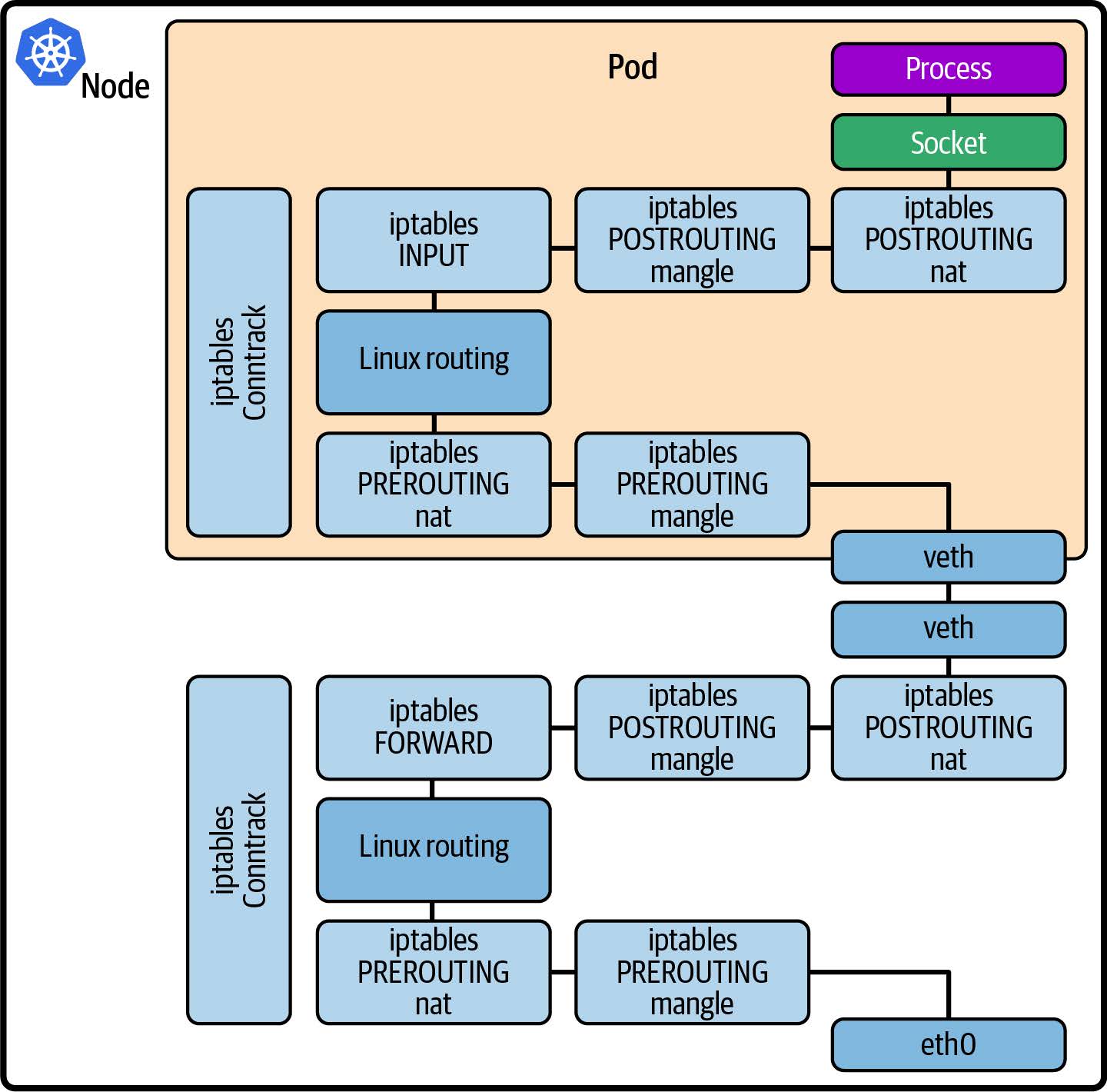
图 8-5. Kubernetes 中的网络路径
从图 8-5 中可以看出,从机器外部发送到应用程序 pod 的数据包必须穿过主机上的网络协议栈、虚拟以太网连接并进入 pod 的网络命名空间,然后再穿过网络协议栈到达应用程序。
这两个网络协议栈在同一个内核中运行,因此数据包实际上要经过两次相同的处理。网络数据包要经过的代码越多,延迟就越高,因此如果能缩短网络路径,就有可能提高性能。
如图 8-6 所示,Cilium 等基于 eBPF 的网络解决方案可以挂钩到网络协议栈,从而覆盖内核的原本网络行为。
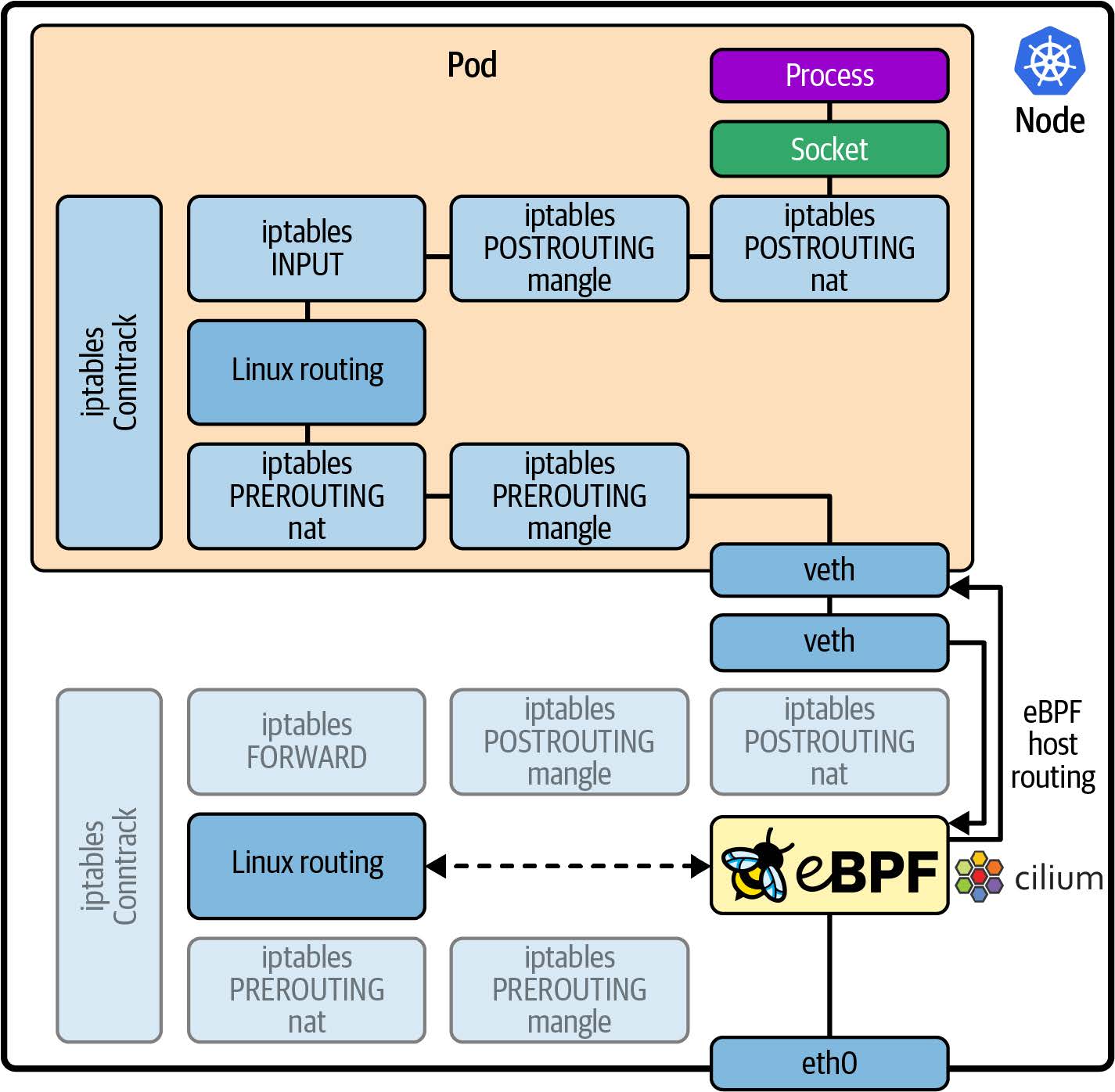
图 8-6. 使用 eBPF 绕过 iptables 和 conntrack 处理
特别是,eBPF 能够使用更有效的解决方案来替换 iptables 和 conntrack,以管理网络规则和连接跟踪。让我们讨论一下为什么这会显着提高 Kubernetes 的性能。
避免使用 iptables
Kubernetes 有一个名为 kube-proxy 的组件,它实现了负载均衡行为,允许多个 Pod 来满足对一个服务的请求。这是通过使用 iptables 规则来实现的。
Kubernetes 通过使用容器网络接口 (CNI) 为用户提供选择使用哪种网络解决方案的机会。一些 CNI 插件使用 iptables 规则来实现 Kubernetes 中的 L3/L4 网络策略;也就是说,iptables 规则指示是否因为不符合网络策略而丢弃数据包。
虽然 iptables 对传统(precontainer,前容器)网络很有效,但在 Kubernetes 中使用时却有一些弱点。在这种环境中,pod 和它们的 IP 地址都是动态变化的,每次添加或删除 pod 时,iptables 规则都必须全部重写,这就影响了大规模运行时的性能。(谢海斌和 Quinton Hoole 在 2017 年 KubeCon 上的一次演讲描述了为 20,000 个服务更新一次 iptables 规则可能需要 5 个小时)。
iptables 的更新并不是唯一的性能问题:查找规则需要对表进行线性搜索,这是一个 O(n) 操作,随着规则数量线性增长。
Cilium 使用 eBPF 哈希表 map 来存储网络策略规则、连接跟踪和负载均衡器查找表,它可以替代 kube-proxy 的 iptables。在哈希表中查找条目和插入新条目都是近似 O(1) 操作,这意味着它们的扩展性要好得多。
您可以在 Cilium 博客上了解由此实现的基准性能改进。在同一篇文章中,您将看到 Calico(另一个具有 eBPF 选项的 CNI)在您选择其 eBPF 实现而不是 iptables 时也能获得更好的性能。 eBPF 为可扩展、动态 Kubernetes 部署提供了最佳性能的机制。
协调网络程序
像 Cilium 这样复杂的网络实现不可能编写成单个 eBPF 程序。如图 8-7 所示,它提供了多个不同的 eBPF 程序,这些程序与内核及其网络协议栈的不同部分挂钩。
图 8-7. Cilium 由多个协调的 eBPF 程序组成,这些程序挂钩内核的不同点
一般来说,Cilium 会尽快拦截流量,以缩短每个数据包的处理路径。从应用程序 pod 传出的信息在套接字层截获,尽可能靠近应用程序。来自外部网络的入站数据包使用 XDP 进行拦截。那么附加的连接点有哪些呢?
Cilium 支持不同的组网模式,以适应不同的环境。对此的完整描述超出了本书的范围(您可以在 Cilium.io 上找到更多信息),但我将在这里给出一个简短的概述,以便您可以了解为什么有这么多不同的 eBPF 程序!
Cilium 有一个简单的、扁平的网络模式,它为集群中的所有 Pod 从相同的 CIDR 中分配 IP 地址,并直接在它们之间路由流量。此外,还有一些不同的隧道模式。在隧道模式下,发往不同节点上的 Pod 的流量被封装在一个消息中,该消息发往目标节点的 IP 地址,在目标节点上解封装后,进行最后一跳发往 Pod。根据数据包的目的地是本地容器、本地主机、本网络上的另一个主机还是一个隧道,将调用不同的 eBPF 程序来处理流量。
在图 8-7 中,您可以看到多个 TC 程序处理进出不同设备的流量。这些设备代表了数据包可能流经的真实和虚拟网络接口:
- Pod 网络的接口(Pod 与主机之间虚拟以太网连接的一端)
- 网络隧道的接口
- 主机上物理网络设备的接口
- 主机自己的网络接口
提示
如果您有兴趣进一步了解数据包如何在 Cilium 中流动的更多信息,Arthur Chiao 写了这篇详细而有趣的博文:"Life of a Packet in Cilium: Discovering the Pod-to-Service Traffic Path and BPF Processing Logics"。
附加在内核中不同点的不同 eBPF 程序使用 eBFP map 和流经网络协议栈时附加到网络数据包的元数据进行通信(我在 XDP 示例中讨论访问网络数据包时提到过)。这些程序不仅仅将数据包路由到目的地;它们还用于根据网络策略丢弃数据包(就像您在前面的示例中看到的那样)。
网络策略执行
在本章开头,您已经看到 eBPF 程序如何丢弃数据包,这意味着它们根本无法到达目的地。这是网络策略执行的基础,无论我们考虑的是 "传统 "防火墙还是云原生防火墙,在概念上都是一样的。策略根据数据包的来源和/或目的地信息来决定是否丢弃数据包。
在传统环境中,IP 地址会在很长一段时间内分配给特定服务器,但在 Kubernetes 中,IP 地址是动态变化的,今天为特定应用程序 Pod 分配的地址很可能会在明天完全不同的应用程序中重复使用。这就是为什么传统防火墙在云原生环境中并不是非常有效。每次 IP 地址更改时都手动重新定义防火墙规则是不切实际的。
相反,Kubernetes 支持 NetworkPolicy 资源的概念,它根据特定 Pod 的标签而不是基于其 IP 地址定义防火墙规则。虽然这种资源类型是 Kubernetes 原生功能,但实际上并不是由 Kubernetes 自身实现的。相反,这个功能是委托给您使用的任何 CNI 插件来处理的。如果您选择的 CNI 不支持 NetworkPolicy 资源,那么您配置的任何规则都将被忽略。另一方面,CNIs 可以自由配置自定义资源,从而相比原生 Kubernetes 定义允许的网络策略配置,允许更复杂的网络策略配置。例如,Cilium 支持基于 DNS 的网络策略规则,因此您可以根据 DNS 名称(例如,“example.com”)而不是 IP 地址来定义流量是否被允许。您还可以为各种第 7 层协议定义策略,例如允许或拒绝对特定 URL 的 HTTP GET 调用,但不允许 POST 调用。
提示
Isovalent 的免费实践实验室“Cilium 入门”将引导您定义第 3/4 层和第 7 层的网络策略。另一个非常有用的资源是 networkpolicy.io 的网络策略编辑器,它可以直观地呈现网络策略的效果。
正如我在本章前面所讨论的,可以使用 iptables 规则来丢弃流量,这也是一些 CNI 实施 Kubernetes NetworkPolicy 规则的方法。Cilium 使用 eBPF 程序来丢弃不符合当前规则集的流量。在本章前面的章节中,我们已经看到了丢弃数据包的示例,希望您对这种方法的工作原理已经有了大致的概念模型。
Cilium 使用 Kubernetes 标识来确定特定网络策略规则是否适用。标签定义了哪些 pod 属于 Kubernetes 服务的一部分,同样,标签也定义了 Cilium 对 pod 的安全标识。以这些服务标识为索引的 eBPF 哈希表可实现非常高效的规则查找。
加密的连接
许多组织都要求通过加密应用程序之间的流量来保护其部署和用户数据。这可以通过在每个应用程序中编写代码来实现,以确保它们建立安全连接,通常使用双向传输层安全性协议(mutual Traffic Layer Security,mTLS)作为 HTTP 或 gRPC 连接的基础。建立这些连接首先需要确定连接两端的应用程序的身份(通常通过交换证书来实现),然后对它们之间的数据流进行加密。
在 Kubernetes 中,可以将需求从应用程序卸载到服务网格(service mesh)层或底层网络本身。关于服务网格的全面讨论超出了本书的范围,但您可能会对我写的一篇关于新协议栈的文章感兴趣:"eBPF 如何简化服务网格"。在这里,让我们把注意力集中在网络层,以及 eBPF 如何将加密需求推向内核。
确保 Kubernetes 集群内流量加密的最简单方法是使用透明加密。之所以称为 "透明",是因为它完全是在网络层进行的,从操作角度来看非常轻便。应用程序本身根本不需要知道加密,也不需要设置 HTTPS 连接;这种方法也不需要在 Kubernetes 下运行任何额外的基础设施组件。
目前有两种常用的内核加密协议:IPsec 和 WireGuard^(R)^,Cilium 和 Calico CNI 在 Kubernetes 网络中都支持这两种协议。讨论这两个协议之间的差异超出了本书的范围,但关键在于它们在两台机器之间建立了一条安全隧道。CNI 可以选择通过该安全隧道连接 pod 的 eBPF 端点。
提示
Cilium 博客上有一篇很好的文章,介绍了 Cilium 如何使用 WireGuard^(R)^ 和 IPsec 来提供节点间的加密流量。这篇文章还简要介绍了两者的性能特点。
安全隧道是使用两端节点的身份来建立的。这些身份由 Kubernetes 管理,因此操作员的管理负担很小。对于许多用途来说,这就足够了,因为它能确保集群中的所有网络流量都经过加密。透明加密还可以不加修改地与网络策略(NetworkPolicy)一起使用,后者使用 Kubernetes 身份来管理流量是否可以在集群中的不同端点之间流动。
有些企业运行的是多租户环境,需要强大的多租户边界,而且必须使用证书来识别每个应用程序端点。在每个应用程序中处理这个问题是一个很大的负担,因此最近将其卸载到服务网格层,但这需要部署一整套额外的组件,造成额外的资源消耗、延迟和操作复杂性。
eBPF 目前正在启用一种新方法,它建立在透明加密的基础上,但使用 TLS 进行初始证书交换和端点验证,这样身份就可以代表单个应用程序,而不是它们所运行的节点,如图 8-8 所示。
图 8-8. 已验证应用程序身份之间的透明加密
一旦完成身份验证步骤,内核中的 IPsec 或 WireGuard^(R)^ 将用于加密这些应用程序之间的流量。这样做有很多好处。它允许第三方证书和身份管理工具(如 cert-manager 或 SPIFFE/SPIRE)处理身份认证部分,而网络则负责加密,因此对应用程序来说完全透明。Cilium 支持通过 SPIFFE ID(而不仅仅是 Kubernetes 标签)指定端点的 NetworkPolicy 定义。也许最重要的是,这种方法可用于任何在 IP 数据包中传输的协议。与只适用于基于 TCP 的连接的 mTLS 相比,这是一个很大的进步。
本书没有足够的篇幅深入探讨 Cilium 的所有内部结构,但我希望这部分内容能帮助您了解 eBPF 是如何成为构建复杂网络功能(如功能齐全的 Kubernetes CNI)的强大平台。
总结
在本章中,您将看到 eBPF 程序连接到网络协议栈的各个不同点。我展示了基本数据包处理的示例,希望这些示例能让您了解 eBPF 如何创建强大的网络功能。您还看到了这些网络功能的一些实际例子,包括负载均衡、防火墙、安全缓解和 Kubernetes 网络。
练习和进一步阅读
以下是一些了解 eBPF 网络用例范围的方法:
- 修改示例 XDP 程序 ping(),使其为 ping 响应和 ping 请求生成不同的跟踪信息。在网络数据包中,ICMP 头紧跟在 IP 头之后(就像 IP 头紧跟在以太网头之后一样)。您可能需要使用 linux/icmp.h 中的 struct icmphdr,并查看类型字段是 ICMP_ECHO 还是 ICMP_ECHOREPLY。
- 如果您想进一步深入 XDP 编程,我推荐 xdp-project 的 xdp-tutorial。
- 使用 BCC 项目中的 sslsniff 查看加密流量的内容。
- 使用 Cilium 网站上链接的教程和实验室来探索 Cilium。
- 使用 networkpolicy.io 上的编辑器可视化 Kubernetes 部署中网络策略的效果。
第九章 用于安全的 eBPF
您已经看到 eBPF 如何用于观察整个系统的事件,并将这些事件的相关信息报告给用户空间工具。在本章中,您将了解如何在事件检测概念的基础上创建基于 eBPF 的安全工具,以检测甚至阻止恶意活动。首先,我将帮助您理解安全与其他类型的可观察性的不同之处。
提示
本章的示例代码位于 GitHub 代码库的 chapter9 目录中。
安全可观察性需要策略和背景
安全工具与报告事件的可观察性工具的区别在于,安全工具需要能够区分正常情况下的预期事件和可能正在发生恶意活动的事件。例如,假设有一个应用程序在正常处理过程中会向本地文件写入数据。假设该应用程序将写入 /home/<username>/<filename>,那么从安全角度来看,您不会对这种活动感兴趣。但是,如果应用程序写入 Linux 中的许多敏感文件位置之一,您会希望得到通知。例如,它不太可能需要修改存储在 /etc/passwd 中的密码信息。
策略不仅要考虑系统正常运行时的正常行为,还要考虑预期的错误路径行为。例如,如果物理磁盘满了,应用程序可能会开始发送网络信息,提醒用户注意这种情况。这些网络信息不应被视为安全事件——尽管它们不寻常,但并不可疑。考虑到错误路径可能会给创建有效策略带来挑战,我们将在本章稍后讨论这一挑战。
定义什么是预期行为,什么非预期行为是策略的工作。安全工具会将活动与策略进行比较,并在活动超出策略范围、变得可疑时采取一些行动。这种行动通常包括生成安全事件日志,该日志通常会被发送到安全信息事件管理(SIEM)平台。它还可能向人员发出警报,要求调查所发生的事件。
调查人员获得的上下文信息越多,就越有可能找出事件的根本原因,并确定这是否是一次攻击、哪些组件受到了影响、攻击是如何发生的、何时发生的以及谁应对此负责。如图 9-1 所示,要能够回答此类问题,需要一种工具从单纯的日志记录转变为名副其实的“安全可观察性”。
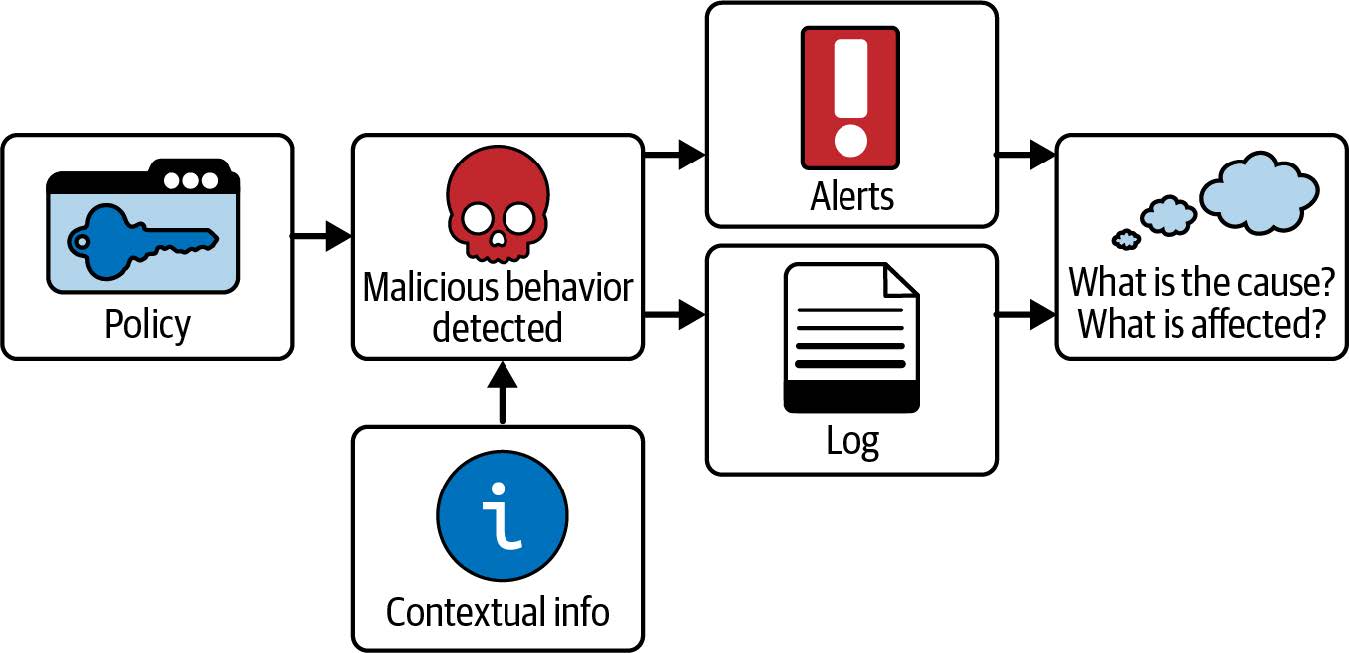
图 9-1. 为实现安全可观察性,在检测到策略外事件时还需要上下文信息
让我们来探讨一下 eBPF 程序用于检测和执行安全事件的一些方法。如您所知,eBPF 程序可以附加到各种事件上,而多年来常用于安全的一组事件是系统调用。我们将从系统调用开始讨论,但正如您所看到的,系统调用可能并不是使用 eBPF 实现安全工具的最有效方法。本章稍后我们将介绍一些更新、更复杂的方法。
使用系统调用处理安全事件
系统调用是用户空间应用程序与内核之间的接口。如果能限制一个应用程序所能使用的系统调用,就能限制它所能做的事情。例如,如果阻止应用程序执行 open*() 系列的系统调用,它就无法打开文件。如果您有一个应用程序,而您不希望它打开文件,那么您可能想创建这种限制,这样即使该应用程序被入侵,它也无法恶意打开文件。如果您在过去几年中一直在使用 Docker 或 Kubernetes,那么您很有可能已经接触过一种使用 BPF 限制系统调用的安全工具:seccomp。
Seccomp
seccomp 是 "安全计算(SECure COMPuting)"的缩写。在其原始或 "严格" 模式下,seccomp 用于将进程可使用的系统调用限制为一个很小的子集:read()、write()、_exit() 和 sigreturn()。这种严格模式的目的是允许用户运行不受信任的代码(也许是从互联网上下载的程序),而不会让这些代码做恶意的事情。
严格模式的限制性很强,许多应用程序需要使用更大的系统调用集,但这并不意味着它们需要全部 400 个或更多系统调用。因此,采用一种更灵活的方法来限制任何特定应用程序可以使用的调用集是有意义的。这就是我们大多数来自容器领域的人都遇到过的 seccomp 风格背后的原因,它称为 seccomp-bpf 更为恰当。这种 seccomp 模式没有使用其允许的固定系统调用子集,而是使用 BPF 代码来过滤允许和不允许的系统调用。
在 seccomp-bpf 中,加载了一组充当过滤器的 BPF 指令。每次调用系统调用时,都会触发过滤器。过滤器代码可以访问传递给系统调用的参数,以便它可以根据系统调用本身和传递给它的参数做出决策。结果是一组可能的行动之一,包括:
- 允许系统调用继续进行
- 将错误代码返回给用户空间应用程序
- 杀死线程
- 通知用户空间应用程序 (seccomp-unotify)(从内核版本 5.0 开始)
提示
如果您想尝试编写自己的 BPF 过滤器代码,Michael Kerrisk 在 https://man7.org/training/download/secisol_seccomp_slides.pdf 上提供了一些很好的示例。
传递给系统调用的一些参数是指针,而 seccompbpf 中的 BPF 代码无法解引用这些指针。这就限制了 seccomp 配置文件的灵活性,因为它在决策过程中只能使用值参数。此外,它必须在进程启动时应用——您不能修改正在应用于给定应用程序进程的配置文件。
您很可能在没有编写 BPF 代码的情况下使用了 seccomp-bpf,因为该代码通常源自人类可读的 seccomp 配置文件。 Docker 的默认配置文件就是一个很好的例子。这是一个通用配置文件,旨在可用于几乎任何正常的容器化应用程序。这不可避免地意味着它允许大多数系统调用,而只不允许少数不太可能适合任何应用程序的系统调用,reboot() 就是一个很好的例子。
Aqua Security 指出,大多数容器化应用程序使用的系统调用次数在 40 到 70 次之间。为了提高安全性,最好使用针对每个特定应用程序使用限制性更强的配置文件,只允许实际使用的系统调用。
生成 Seccomp 配置文件
如果您让一般的应用程序开发人员告诉您他们的程序会调用哪些系统调用,您很可能会得到一个茫然的表情。这并没有侮辱的意思。只是大多数开发人员使用的编程语言所提供的高层抽象与系统调用的细节相去甚远。例如,他们可能知道自己的应用程序打开了哪些文件,但不太可能告诉您这些文件是用 open() 还是 openat() 打开的。因此,如果您要求开发人员在编写应用程序代码的同时,手工制作一个适当的 seccomp 配置文件,您不大可能得到肯定的答复。
自动化是未来的方向:其想法是使用一种工具来记录应用程序的系统调用集。在早期,seccomp 配置文件通常使用 strace 来收集应用程序调用的系统调用集。(例如,请参阅 Jess Frazelle 的这篇文章,他为 Docker 开发了默认的 seccomp 配置文件:“如何使用新的 Docker Seccomp 配置文件”。)在云原生时代,这并不是一个好的解决方案,因为没有简单的方法将 strace 指向特定的容器或 Kubernetes pod。如果能以 JSON 格式(Kubernetes 和兼容 OCI 的容器运行时可以将其作为输入)生成配置文件,而不仅仅是系统调用列表,那将会更有帮助。有几款工具可以做到这一点,它们使用 eBPF 收集所有被调用系统调用的信息:
- Inspektor Gadget 包含一个 seccomp 分析器,可让您为 Kubernetes pod 中的容器生成自定义 seccomp 配置文件。(Inspektor Gadget 的 seccomp 分析器的文档相当枯燥,但 Jose Blanquicet 的视频概述更容易理解。)
- Red Hat 以 OCI 运行时钩子(OCI runtime hook)的形式创建了 seccomp 分析器。
使用这些分析器时,您需要运行应用程序一定的任意时间,以生成包含其可能合法调用的全部系统调用列表的配置文件。如本章前文所述,该列表需要包含错误路径。如果您的应用程序在错误条件下无法正常运行,因为它需要调用的系统调用被阻止了,这可能会导致更大的问题。由于 seccomp 配置文件所处理的抽象级别比大多数开发人员所熟悉的要低,因此很难手动审查它们是否涵盖了所有正确的情况。
以 OCI 运行时钩子为例,一个 eBPF 程序被附加到 syscall_enter 原始跟踪点,并维护一个 eBPF map,以跟踪哪些系统调用已被观测到。该工具的用户空间部分使用 Go 语言编写,并使用 iovisor/gobpf 库。(我将在第 10 章讨论该库和其他用于 eBPF 的 Golang 库)。
以下是 OCI 运行时钩子中将 eBPF 程序加载到内核并附加到跟踪点的代码行(为简洁起见,省略了几行):
// 这一行做了一件非常有趣的事情:它将 eBPF 源代码中名为 $PARENT_PID 的变量替换为一个数字进程 ID。这是一种常见的模式,表明该工具将为每个被检测的进程加载单独的 eBPF 程序。
src := strings.Replace(source, "$PARENT_PID", strconv.Itoa(pid), -1)
m := bcc.NewModule(src, []string{})
defer m.Close()
...
// 在这里,一个名为 enter_trace 的 eBPF 程序会被加载到内核中。
enterTrace, err := m.LoadTracepoint("enter_trace")
...
// enter_trace 程序会附加到跟踪点 raw_syscalls:sys_enter。这是任何系统调用入口处的跟踪点,您在前面的示例中已经遇到过。每当任何用户空间代码进行系统调用时,都会触发这个跟踪点。
if err := m.AttachTracepoint("raw_syscalls:sys_enter", enterTrace); err != nil
{
return fmt.Errorf("error attaching to tracepoint: %v", err)
}
这些分析器使用附加到 sys_enter 的 eBPF 代码来跟踪已使用的系统调用集,并生成 seccomp 配置文件,与 seccomp 一起使用,后者负责执行配置文件的实际工作。我们将考虑的下一类 eBPF 工具也附加到 sys_enter,但它们使用系统调用来跟踪应用程序的行为,并将其与安全策略进行比较。
系统调用跟踪安全工具(Syscall-Tracking Security Tools)
最著名的系统调用跟踪安全工具是 CNCF 项目 Falco,它提供安全警报。默认情况下,Falco 是作为内核模块安装的,但也有 eBPF 版本。用户可以定义规则来确定哪些事件与安全相关,当发生与规则中定义的策略不符的事件时,Falco 可以生成各种格式的警报。
内核模块驱动程序和基于 eBPF 的驱动程序都会附加到系统调用。如果检查 GitHub 上的 Falco eBPF 程序,您会看到类似下面这样的行,它们将探针附加到原始系统调用的入口和出口点(以及其他一些事件,如页面故障):
BPF_PROBE("raw_syscalls/", sys_enter, sys_enter_args)
BPF_PROBE("raw_syscalls/", sys_exit, sys_exit_args)
由于 eBPF 程序可以动态加载,并能检测由已有进程触发的事件,因此 Falco 等工具可将策略应用于已在运行的应用程序工作负载。用户可以修改所应用的规则集,而无需修改应用程序或其配置。这与 seccomp 配置文件形成鲜明对比,后者必须在应用程序进程启动时应用。
遗憾的是,这种使用系统调用入口点的安全工具存在一个问题:TOCTOU(Time Of Check to Time Of Use) 问题。
当 eBPF 程序在系统调用入口点被触发时,它可以访问用户空间传递给该系统调用的参数。如果这些参数是指针,内核在对这些数据进行操作之前需要将指向的数据复制到自己的数据结构中。如图 9-2 所示,在 eBPF 程序检查数据之后、内核复制数据之前,攻击者有机会修改该数据。因此,执行系统调用的数据可能与 eBPF 程序捕获的数据不同。(Rex Guo 和 Junyuan Zeng 在 DEFCON 29 题为 "Phantom Attack: Evading System Call Monitoring" 的演讲中讨论了如何利用这个窗口:Leo Di Donato 和 KP Singh 在题为 "LSM BPF Change Everything" 的演讲中更详细地介绍了它对 Falco 的影响。)
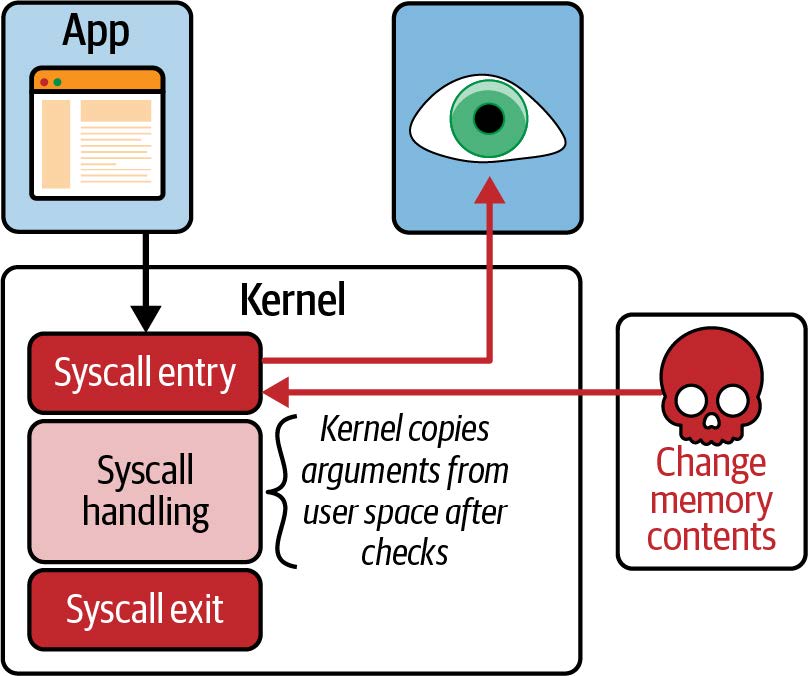
图 9-2. 攻击者可以在内核访问系统调用参数之前更改它们
如果不是因为 seccomp-bpf 中不允许程序解引用用户空间指针,所以根本无法检查数据,同样的攻击窗口也适用于 seccomp-bpf。
TOCTOU 问题确实适用于 seccomp_unotify,这是 seccomp 最近新增的一种模式,可向用户空间报告违规行为。seccomp_unotify 的手册明确指出:"因此,应该绝对清楚,seccomp 用户空间通知机制不能用来执行安全策略!"
系统调用入口点对于可观察性目的可能非常方便,但对于严格的安全工具来说,这确实不够。
Sysmon for Linux 工具通过附加到系统调用的入口点和出口点来解决 TOCTOU 窗口问题。一旦调用完成,它就会查看内核的数据结构,以获得准确的视图。例如,如果系统调用返回一个文件描述符,那么附加到出口的 eBPF 程序就可以通过查看相关进程的文件描述符表,获取文件描述符所代表对象的正确信息。虽然这种方法可以准确记录与安全相关的活动,但无法阻止操作的发生,因为在进行检查时系统调用已经完成。
为了确保检查的信息与内核执行的信息一致,eBPF 程序应该附加到参数复制到内核内存后发生的事件。遗憾的是,由于系统调用代码对数据的处理方式不同,内核中并没有一个共同的位置来完成这项工作。不过,有一个定义明确的接口可以安全地附加 eBPF 程序:Linux 安全模块(LSM)API。这就需要一个相对较新的 eBPF 功能:BPF LSM。
BPF LSM
LSM 接口提供了一组钩子,每个钩子都在内核即将对内核数据结构进行操作之前触发。钩子调用的函数可以决定是否允许操作继续进行。该接口最初是为了允许安全工具以内核模块的形式实现而提供的; BPF LSM 对此进行了扩展,以便 eBPF 程序可以附加到相同的挂钩点,如图 9-3 所示。
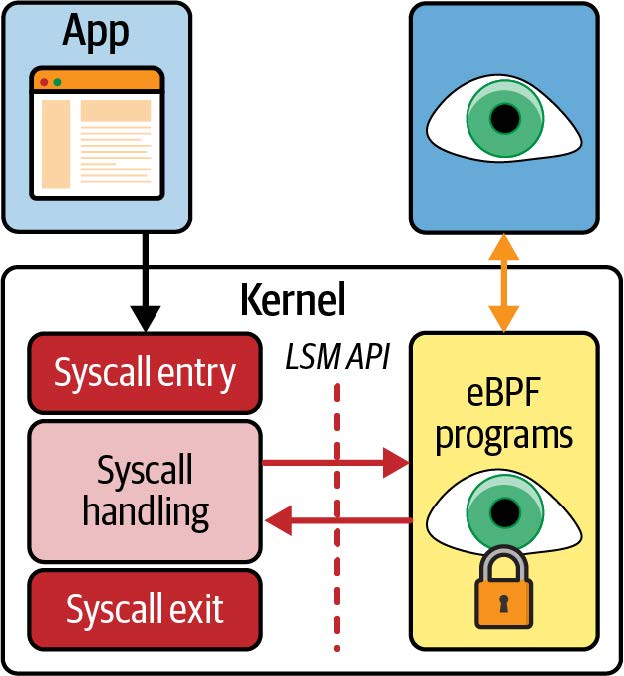
图 9-3. 使用 LSM BPF,eBPF 程序可由 LSM 钩子事件触发
内核源代码中记录了数百个 LSM 挂钩。需要说明的是,系统调用与 LSM 挂钩之间并不是一一对应的,但如果某个系统调用有可能从安全角度做一些有趣的事情,那么处理该系统调用就会触发一个或多个挂钩。
这是附加到 LSM 挂钩的 eBPF 程序的一个简单示例。此示例在 chmod 命令处理期间调用(“chmod”代表“更改模式(change modes)”,主要用于更改文件的访问权限):
SEC("lsm/path_chmod")
int BPF_PROG(path_chmod, const struct path *path, umode_t mode)
{
bpf_printk("Change mode of file name %s\n", path->dentry->d_iname);
return 0;
}
这个示例只是简单地跟踪了文件名,并始终返回 0,但您可以想象,真正的实现会利用参数来决定是否允许这种模式的改变。如果返回值为非 0,则不允许进行此更改,因此内核不会继续执行。值得注意的是,像这样完全在内核内部进行策略检查的性能非常高。
BPF_PROG() 的 path 参数是代表文件的内核数据结构体,而 mode 参数则是期望的新模式值。您可以从 path->dentry->d_iname 字段看到被访问文件的名称。
LSM BPF 是在内核 5.7 版本中添加的,这意味着(至少在撰写本文时)许多受支持的 Linux 发行版还无法使用它,但我预计在接下来的几年中,许多厂商都会开发使用该接口的安全工具。在 LSM BPF 被广泛使用之前,还有另一种可行的方法,Cilium Tetragon 开发人员就使用了这种方法。
Cilium Tetragon
Tetragon 是 Cilium 项目(也是 CNCF 的一部分)的一部分。Tetragon 的方法是建立一个框架,将 eBPF 程序附加到 Linux 内核中的任意函数上,而不是附加到 LSM API 钩子上。
Tetragon 设计用于 Kubernetes 环境,该项目定义了一种名为 TracingPolicy 的自定义 Kubernetes 资源类型。它用于定义 eBPF 程序应附加的一组事件、eBPF 代码需要检查的条件以及满足条件时应采取的行动。以下是 TracingPolicy 示例的摘录:
spec:
kprobes:
- call: "fd_install"
...
matchArgs:
- index: 1
operator: "Prefix"
values:
- "/etc/"
...
该策略定义了一组用于附加程序的 kprobe,其中第一个是内核函数 fd_install。这是内核中的内部函数。让我们来探讨一下为什么要附加到这样一个函数。
附加到内部内核函数
系统调用接口和 LSM 接口在 Linux 内核中被定义为稳定接口;也就是说,它们不会以向后不兼容的方式发生变化。如果您今天编写的代码使用了这些接口中的函数,那么它们将在未来版本的内核中继续工作。在构成 Linux 内核的 3000 万行代码中,这些接口只占很小一部分。这些代码库中的部分代码是事实上的稳定代码,即使它们没有被官方宣布为稳定代码;它们已经很久没有改变过了,而且将来也不太可能改变。
编写附加到尚未正式稳定的内核函数的 eBPF 程序是完全合理的,因为这些程序在未来相当长的一段时间内都有可能正常工作。此外,鉴于新内核版本通常需要数年时间才能广泛部署,因此可以肯定的是,有足够的时间来解决任何可能出现的不兼容问题。
Tetragon 的贡献者包括许多内核开发人员,他们利用自己对内核内部结构的了解,确定了一些安全的好地方,可以将 eBPF 程序附加到这些地方,以达到有用的安全目的。有几个示例的 TracingPolicy 定义就利用了这些知识。这些示例监控的安全事件包括文件操作、网络活动、程序执行和权限更改——所有这些都是恶意行为者在攻击中会做的事情。
让我们再来看一下附加到 fd_install 的策略定义示例。fd "代表 "文件描述符",该函数源代码中的注释告诉我们,该函数 "在 fd 数组中安装一个文件指针"。当文件被打开时就会发生这种情况,在内核中填充完文件的数据结构后就会调用该函数。这是检查文件名的安全位置——在前面的 TracingPolicy 示例中,只有以"/etc/"开头的文件名才会引起注意。
与 LSM BPF 程序一样,Tetragon eBPF 程序也可以访问上下文信息,从而完全在内核中做出安全决定。与向用户空间报告所有特定类型的事件不同,安全相关事件可以在内核中进行过滤,只有超出策略范围的事件才会向用户空间报告。
预防性安全
大多数基于 eBPF 的安全工具都使用 eBPF 程序来检测恶意事件,这些事件会通知用户空间应用程序,然后该应用程序可以采取行动。正如您在图 9-4 中看到的,用户空间应用程序执行的任何操作都是异步发生的,到那时可能为时已晚——也许数据可能已被泄露,或者攻击者可能已将恶意代码持久保存到磁盘上。
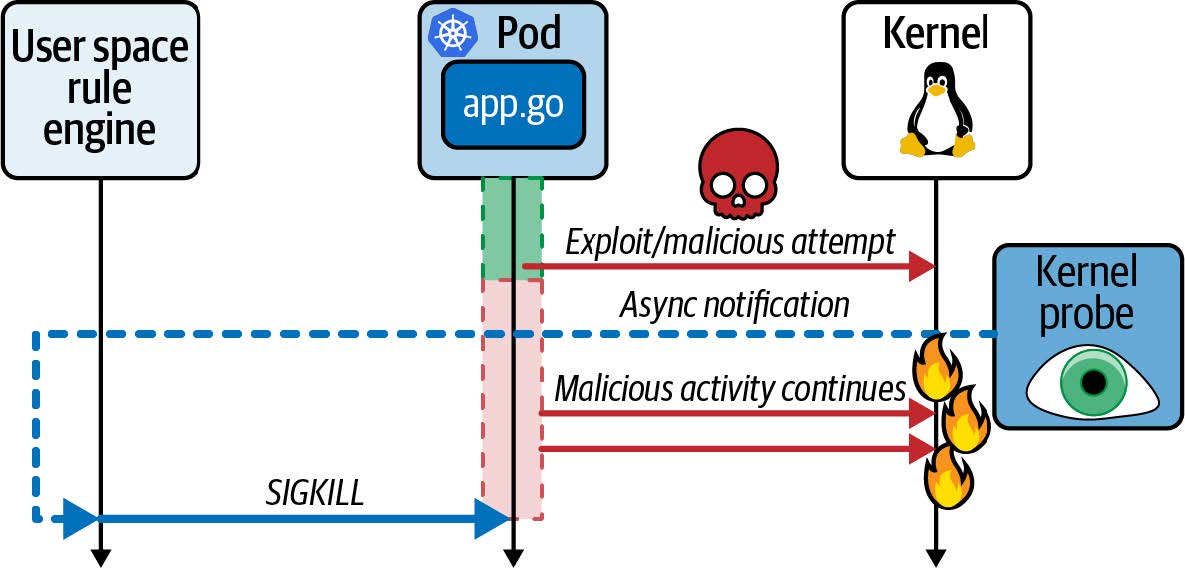
图 9-4. 从内核到用户空间的异步通知允许攻击有一定时间继续进行
在内核版本 5.3 及更高版本中,有一个名为 bpf_send_signal() 的 BPF 辅助函数。 Tetragon 使用此功能来实现预防性安全。如果策略定义了 Sigkill 操作,则任何匹配事件都将导致 Tetragon eBPF 代码生成 SIGKILL 信号,该信号终止尝试超出策略操作的进程。如图 9-5 所示,这是同步发生的;也就是说,内核正在执行的、被 eBPF 代码判定为超出策略的活动将被阻止完成。
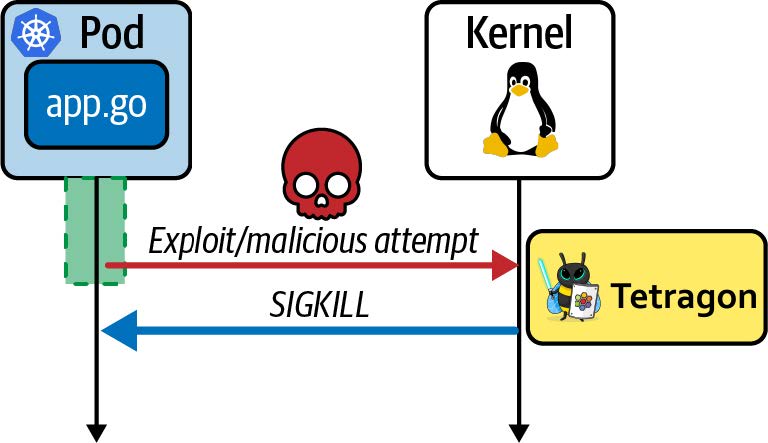
图 9-5. Tetragon 通过从内核发送 SIGKILL 信号来同步杀死恶意进程
Sigkill 策略需要谨慎使用,因为配置不正确的策略可能会导致不必要地终止应用程序,但它是 eBPF 用于安全目的的一个非常强大的功能。一开始,您可以在 "审计(audit)"模式下运行,该模式会生成安全事件,但不会应用 SIGKILL 强制,直到您确信该策略不会破坏任何东西。
如果您想了解更多有关使用 Cilium Tetragon 检测安全事件的信息,Natália Réka Ivánkó 和 Jed Salazar 撰写的题为 "Security Observability with eBPF "的报告将为您提供更详细的信息。
网络安全
第 8 章讨论了如何有效利用 eBPF 来实施网络安全机制。总结如下:
- 防火墙和 DDoS 保护非常适合早期附加在网络数据包入口路径中的 eBPF 程序。由于 XDP 程序有可能卸载到硬件,恶意数据包甚至可能永远不会到达 CPU!
- 为了实施更复杂的网络策略,例如确定哪些服务可以相互通信的 Kubernetes 策略,如果数据包被确定为不符合策略,附加到网络协议栈上各点的 eBPF 程序就可以丢弃这些数据包。
网络安全工具通常以预防模式使用,丢弃数据包,而不仅仅是审计恶意活动。这是因为坏人很容易发动与网络有关的攻击;如果给设备一个暴露在互联网上的公共 IP 地址,用不了多久就会看到可疑的流量,因此企业不得不使用预防性措施。
相比之下,许多企业在审计模式下使用入侵检测工具,并依靠取证来确定可疑事件是否真的是恶意的,以及需要采取哪些补救措施。如果某个安全工具过于生硬并且容易检测到误报,那么它需要在审计模式而非预防模式下运行也就不足为奇了。我认为,eBPF 能够使安全工具变得更加复杂,控制更加精细、准确。正如我们今天认为防火墙在预防模式下已经足够精确一样,我们将看到越来越多的预防工具将作用于其他非网络事件。这甚至可能包括将基于 eBPF 的控件打包为应用程序产品的一部分,以便它可以提供自己的运行时安全性。
总结
在本章中,您了解了 eBPF 在安全领域的应用是如何演变的,从对系统调用的低级别检查,发展到更加复杂的使用方式,例如用于安全策略检查、内核事件过滤和运行时执行的 eBPF 程序。
在将 eBPF 用于安全目的方面仍然存在着许多积极的开发工作。我相信在未来几年,我们将看到这个领域的工具不断发展,并广泛被采纳和应用。
第十章 eBPF 编程
到目前为止,在本书中,您已经学到了很多关于 eBPF 的知识,并看到了许多将其用于各种应用的示例。但是如果您想基于 eBPF 实现自己的想法怎么办?本章将讨论您编写自己的 eBPF 代码时的选择。
正如您从阅读本书中了解到的,eBPF 编程由两部分组成:
- 编写在内核中运行的 eBPF 程序
- 编写管理 eBPF 程序并与之交互的用户空间代码
本章中将讨论的大多数库和编程语言要求程序员同时处理两个部分,并意识到处理的内容在哪里。但是,bpftrace 可能是最简单的 eBPF 编程语言,它将这种区别隐藏起来,使得程序员不需要过多关注这一点。
Bpftrace
正如该项目的 README 页面所述,"bpftrace 是一种用于 Linux eBPF 的高级跟踪语言......其灵感来自 awk 和 C,以及 DTrace 和 SystemTap 等前辈跟踪器。
bpftrace 命令行工具将使用这种高级语言编写的程序转换为 eBPF 内核代码,并在终端中提供一些输出格式化的结果。作为用户,您实际上不需要考虑内核和用户空间之间的划分。
您可以在该项目的文档中找到许多有用的 one-liners 示例,其中包括一个很好的教程,从编写一个简单的 “Hello World” 脚本开始,逐步引导您编写更复杂的脚本,可以跟踪从内核数据结构中读取的数据。
提示
通过 Brendan Gregg 的 bpftrace 备忘录,您可以了解 bpftrace 提供的各种功能。如需深入了解
bpftrace和 BCC,请参阅他的书《BPF 性能工具》。
顾名思义,bpftrace 可以附加到跟踪(也称为 perf 相关)事件,包括 kprobes、uprobes 和 tracepoints。例如,您可以使用 -l 选项列出一台机器上可用的跟踪点和 kprobes,如下所示:
$ bpftrace -l "*execve*"
tracepoint:syscalls:sys_enter_execve
tracepoint:syscalls:sys_exit_execve
...
kprobe:do_execve_file
kprobe:do_execve
kprobe:__ia32_sys_execve
kprobe:__x64_sys_execve
...
这个示例找到了所有包含 "execve" 的可用附加点。从输出中可以看到,可以附加到名为 do_execve 的 kprobe。下面是一个 bpftrace 单行脚本,用于附加到该事件:
bpftrace -e 'kprobe:do_execve { @[comm] = count(); }'
Attaching 1 probe...
^C
@[node]: 6
@[sh]: 6
@[cpuUsage.sh]: 18
{ @[comm] = count(); } 部分是附加到该事件的脚本。此示例记录了不同可执行文件触发事件的次数。
bpftrace 的脚本可以协调附加在不同事件上的多个 eBPF 程序。例如,opensnoop.bt 脚本可报告文件被打开的情况。下面是一个摘要:
tracepoint:syscalls:sys_enter_open,
tracepoint:syscalls:sys_enter_openat
{
@filename[tid] = args.filename;
}
tracepoint:syscalls:sys_exit_open,
tracepoint:syscalls:sys_exit_openat
/@filename[tid]/
{
$ret = args.ret;
$fd = $ret >= 0 ? $ret : -1;
$errno = $ret >= 0 ? 0 : - $ret;
printf("%-6d %-16s %4d %3d %s\n", pid, comm, $fd, $errno,
str(@filename[tid]));
delete(@filename[tid]);
}
该脚本定义了两个不同的 eBPF 程序,分别连接到两个不同的内核跟踪点,分别位于 open() 和 openat() 系统调用的入口和出口处。(附加到系统调用入口点意味着该脚本具有与上一章讨论的相同 TOCTOU 漏洞。但这并不妨碍它成为一个有用的工具;只是您不应该依赖它作为安全目的的唯一防线。)这两个系统调用都用于打开文件,并将文件名作为输入参数。无论哪种系统调用入口触发的程序都会缓存该文件名,并将其存储在一个 map 中,其中的键是当前线程 ID。当触发出口跟踪点时,脚本中的 /@filename[tid]/ 行将从该 map 中检索缓存的文件名。
运行该脚本会产生如下输出:
./opensnoop.bt
Attaching 6 probes...
Tracing open syscalls... Hit Ctrl-C to end.
PID COMM FD ERR PATH
297388 node 30 0 /home/liz/.vscode-server/data/User/
workspaceStorage/73ace3ed015
297360 node 23 0 /proc/307224/cmdline
297360 node 23 0 /proc/305897/cmdline
297360 node 23 0 /proc/307224/cmdline
我刚刚告诉过您有四个 eBPF 程序附加到跟踪点,那么为什么此输出显示有六个探针呢?答案是,该程序的完整版本包含两个针对 BEGIN 和 END 子句的“特殊探针”,用于初始化和清理脚本(与 awk 语言非常相似)。为了简洁起见,我在这里省略了这些子句,但您可以在 GitHub 的源代码中找到它们。
如果您使用 bpftrace,则不需要了解底层程序和 map,但对于那些阅读过本书前面章节的人来说,这些概念现在应该很熟悉。如果您有兴趣查看 bpftrace 程序运行时加载到内核中的程序和 map,您可以使用 bpftool 轻松完成此操作(正如您在第 3 章中看到的那样)。这是我运行 opensnoop.bt 时得到的输出:
$ bpftool prog list
...
494: tracepoint name sys_enter_open tag 6f08c3c150c4ce6e gpl
loaded_at 2022-11-18T12:44:05+0000 uid 0
xlated 128B jited 93B memlock 4096B map_ids 254
495: tracepoint name sys_enter_opena tag 26c093d1d907ce74 gpl
loaded_at 2022-11-18T12:44:05+0000 uid 0
xlated 128B jited 93B memlock 4096B map_ids 254
496: tracepoint name sys_exit_open tag 0484b911472301f7 gpl
loaded_at 2022-11-18T12:44:05+0000 uid 0
xlated 936B jited 565B memlock 4096B map_ids 254,255
497: tracepoint name sys_exit_openat tag 0484b911472301f7 gpl
loaded_at 2022-11-18T12:44:05+0000 uid 0
xlated 936B jited 565B memlock 4096B map_ids 254,255
$ bpftool map list
254: hash flags 0x0
key 8B value 8B max_entries 4096 memlock 331776B
255: perf_event_array name printf flags 0x0
key 4B value 4B max_entries 2 memlock 4096B
您可以清楚地看到四个跟踪点程序,以及用于缓存文件名的哈希 map 和从内核向用户空间传递输出数据的 perf_event_array。
提示
bpftrace 实用程序构建在 BCC 之上,您在本书的其他地方见过它,我将在本章后面介绍它。
bpftrace脚本被转换为 BCC 程序,然后使用 LLVM/Clang 工具链在运行时进行编译。
如果您想要使用基于 eBPF 的性能测量的命令行工具,bpftrace 很可能能够满足您的需求。但是,尽管 bpftrace 可以作为使用 eBPF 进行跟踪的强大工具,但它并没有完全展现 eBPF 所提供的全部可能性。
要发挥 eBPF 的全部潜力,您需要直接为内核编写 eBPF 程序,并处理用户空间部分。这两个方面通常可以使用完全不同的编程语言来编写。让我们从运行在内核中的 eBPF 代码的选择开始。
内核中 eBPF 的语言选择
eBPF 程序可直接以 eBPF 字节码编写(有关示例,请查看 Cloudflare 的博客文章“eBPF, Sockets, Hop Distance and manually writing eBPF assembly”),但在实践中,大多数程序都是由 C 或 Rust 编译成字节码的。这些语言的编译器支持将 eBPF 字节码作为目标输出。
提示
eBPF 字节码并非适用于所有编译语言。如果该语言涉及运行时组件(如 Go 或 Java 虚拟机),则很可能与 eBPF 校验器不兼容。例如,很难想象内存垃圾回收如何能与验证器对内存安全使用的检查协同工作。同样,eBPF 程序必须是单线程的,因此语言中的任何并发功能都无法使用。
虽然 XDPLua 并不是真正的 eBPF,但这是一个有趣的项目,它提出了在 Lua 脚本中编写 XDP 程序,直接在内核中运行。然而,该项目的初步研究表明,eBPF 可能更具性能,而且随着每个内核发布中 eBPF 的功能变得越来越强大(例如,现在可以实现循环),除非某些人偏好使用 Lua 脚本编写代码,否则并不清楚是否有很大的优势。
我敢打赌,大多数选择用 Rust 编写 eBPF 内核代码的人也会选择用同样的语言编写用户空间代码,因为共享数据结构无需重写。但这并不是强制性的,您可以将 eBPF 代码与您选择的任何用户空间语言混合使用。
选择用 C 语言编写内核代码的程序员也可以选择用 C 语言编写用户空间代码(在本书中您已经看到了很多这样的例子)。但 C 语言是一种相当低级的语言,需要程序员自己处理很多细节,特别是内存管理。虽然有些人对这样做很适应,但很多人更愿意用另一种更高级的语言编写用户空间代码。无论您喜欢哪种语言,您都希望有一个提供 eBPF 支持的库,这样您就不必直接编写第 3 章中提到的系统调用接口。在本章的其余部分,我们将讨论各种语言中最流行的 eBPF 库选项。
BCC Python/Lua/C++
在第二章中,我给您展示的第一个 “Hello World” 示例是使用 BCC 库编写的 Python 程序。该项目使用相同的库(以及我稍后会介绍的基于 libbpf 的新实现)实现了许多有用的性能测量工具。
除了介绍如何使用所提供的 BCC 工具来衡量性能的文档外,BCC 还包括参考指南和 Python 编程教程,以帮助您在此框架内开发自己的 eBPF 工具。
第 5 章讨论了 BCC 的可移植性方法,即在运行时编译 eBPF 代码,确保其与目标机器的内核数据结构兼容。在 BCC 中,内核侧 eBPF 程序代码定义为字符串(或 BCC 读取为字符串的文件内容)。该字符串会传递给 Clang 进行编译,但在此之前,BCC 会对字符串进行一些预处理。这样,它就能为程序员提供方便的快捷方式,其中一些您在本书中已经看到过。例如,下面是 chapter2/hello_map.py 示例代码中的一些相关行:
# 这是一个Python程序,将在用户空间中运行。
#!/usr/bin/python3
from bcc import BPF
# program 字符串包含要编译并加载到内核中的 eBPF 程序。
program = """
// BPF_RINGBUF_OUTPUT 是一个 BCC 宏,用于定义一个名为 output 的环形缓冲区。它是程序字符串的一部分,因此我们很自然地认为它是从内核的角度来定义缓冲区的。先别这么想,我们先看 b["output"].open_ring_buffer(print_event) 的注释。
BPF_RINGBUF_OUTPUT(output, 1);
...
int hello(void *ctx) {
...
// 这行代码看起来像是在一个名为"output"的对象上调用了一个"ringbuf_output()"方法。但是等一下——在C语言中,对象的方法根本不存在!这里 BCC 做了一些重要的工作,将这些方法展开成底层的BPF辅助函数(https://github.com/iovisor/bcc/blob/14c5f99750cca211cbc620910ac574bb43f58d1d/src/cc/frontends/clang/b_frontend_action.cc#L959),在这种情况下是"bpf_ringbuf_output()"。
output.ringbuf_output(&data, sizeof(data), 0);
return 0;
}
"""
# 在这里,程序字符串被改写成 Clang 可以编译的 BPF C 代码。这一行还会将生成的程序加载到内核中。
b = BPF(text=program)
...
# 在代码中没有其他地方定义了名为 output 的环形缓冲区,但在 Python 用户空间代码中却可以访问它。BCC 在预处理BPF_RINGBUF_OUTPUT(output, 1); 这一行时,执行了双重任务,因为它同时为用户空间和内核部分定义了环形缓冲区。
b["output"].open_ring_buffer(print_event)
...
正如本例所示,BCC 本质上为 BPF 编程提供了自己的类 C 语言。它为程序员提供了便利,可以处理内核和用户空间的共享结构定义等问题,并提供方便的快捷方式来封装 BPF 辅助函数。这意味着,如果您是 eBPF 编程领域的新手,尤其是已经熟练掌握 Python 的人,BCC 是一种容易上手的方法。
提示
如果您想探索 BCC 编程,这本针对 Python 程序员的教程是一个很好的方法,它可以让您了解 BCC 的更多特性和功能,而本书的篇幅有限,不再过多介绍。
文档并没有说得很清楚,但 BCC 除了支持 Python 作为 eBPF 工具用户空间部分的语言外,还支持用 Lua 和 C++ 编写工具。在提供的示例中有 lua 和 cpp 目录,如果您想尝试这种方法,可以在此基础上编写自己的代码。
BCC 对于程序员来说可能很方便,但是由于将编译器工具链与实用程序一起分发的效率很低(在第 5 章中更深入地讨论),如果您希望编写要分发的生产质量工具,我建议考虑本章中讨论的其他一些库。
C 和 Libbpf
您已经在本书中看到了很多用 C 语言编写的 eBPF 程序的例子,这些程序使用 LLVM 工具链编译成 eBPF 字节码。您还看到了为支持 BTF 和 CO-RE 而添加的扩展。许多 C 程序员也熟悉另一种主要的 C 编译器 GCC,他们会很高兴听到 GCC 从第 10 版开始也支持以 eBPF 为目标进行编译;不过,与 LLVM 提供的功能相比仍有一些差距。
正如第 5 章所述,CO-RE 和 libbpf 提供了一种可移植的 eBPF 编程方法,无需在提供每个 eBPF 工具的同时提供编译器工具链。BCC 项目正是利用了这一点,除了原有的 BCC 性能跟踪工具集外,现在还重写了这些工具的版本,以利用 libbpf。人们普遍认为,基于 libbpf 重写的 BCC 工具版本是更好的选择,因为它们的内存占用更少(例如,Brendan Gregg 观察到基于 libbpf 的 opensnoop 版本需要大约 9 MB,而基于 Python 的版本则需要 80 MB。),而且在编译过程中不会出现启动延迟。
如果您擅长使用 C 语言编程,那么使用 libbpf 将非常有意义。在本书中,您已经看到了很多这样的例子。
要想用 C 语言编写自己的 libbpf 程序,最好从 libbpf-bootstrap 开始(既然您已经读过这本书了!)。请阅读 Andrii Nakryiko 的博文,了解这个项目背后的动机。
此外,还有一个名为 libxdp 的库,它建立在 libbpf 的基础上,使 XDP 程序的开发和管理变得更容易。这也是 xdp-tools 的一部分,其中还有我最喜欢的 eBPF 编程学习资源之一:XDP 教程。(在 "eBPF 和 Cilium Office Hours "直播节目的第 13 集中,观看我如何处理一些 XDP 教程示例。)
但 C 语言是一种颇具挑战性的低级语言。C 语言程序员必须负责内存管理和缓冲区处理等工作,因此编写的代码很容易出现安全漏洞,更不用说因指针处理不当而导致崩溃了。eBPF 校验器在内核方面提供了帮助,但对用户空间代码却没有同等的保护。
好消息是,还有一些适用于其他编程语言的库与 libbpf 进行接口交互,或者提供类似的重定位功能,以便编写可移植的 eBPF 程序。以下是其中一些最受欢迎的库。
Go
Go 语言已广泛应用于基础设施和云原生工具,因此用它来编写 eBPF 代码也是理所当然的。
提示
Michael Kashin 的这篇文章从另一个角度比较了 Go 的不同 eBPF 库。
Gobpf
Gobpf 项目可能是第一个真正意义上的 Golang 实现,它与 BCC 并列为 Iovisor 的一部分。不过,它已经有一段时间没有得到积极维护了,在我写这篇文章的时候,还有人在讨论是否要废弃它,所以在选择库的时候请记住这一点。
Ebpf-go
作为 Cilium 项目的一部分,eBPF Go 库被广泛使用(我在 GitHub 上找到了约 10,000 个引用,该项目有近 4,000 个星)。它为管理和加载 eBPF 程序和 map 提供了便捷的功能,包括 CO-RE 支持,所有这些都是纯 Go 语言实现的。
有了这个库,您就可以选择将 eBPF 程序编译成字节码,并使用一个名为 bpf2go 的工具将字节码嵌入 Go 源代码。作为编译步骤的一部分,您需要使用 LLVM/Clang 编译器来生成该代码。一旦 Go 代码编译完成,您就可以发布包含 eBPF 字节码的单一 Go 二进制文件,它可移植到不同的内核,除 Linux 内核本身外没有任何依赖项。
cilium/ebpf 库还支持加载和管理以独立 ELF 文件(如本书中的 *.bpf.o 示例)形式构建的 eBPF 程序。
在撰写本文时,cilium/ebpf 库支持用于跟踪的 perf 事件,包括相对较新的 fentry 事件,以及大量网络程序类型(如 XDP 和 cgroup 套接字附件)。
在 cilium/ebpf 项目下的示例目录中,您将看到内核程序的 C 代码与 Go 中相应的用户空间代码位于同一目录中:
-
C 文件以
// +build ignore开头,它会告诉 Go 编译器忽略它们。在撰写本文时,我们正在进行更新,以便改用更新的//go:build类型的编译标记。 -
用户空间文件包括如下一行,它告诉 Go 编译器在 C 文件上调用 bpf2go 工具:
//go:generate go run github.com/cilium/ebpf/cmd/bpf2go -cc $BPF_CLANG -cflags $BPF_CFLAGS bpf <C filename> -- -I../headers在软件包上运行
go:generate,只需一步就能重建 eBPF 程序并重新生成框架。
与第 5 章中介绍的 bpftool gen skeleton 很相似,bpf2go 会生成用于操作 eBPF 对象的框架代码,从而最大限度地减少需要自己编写的用户空间代码(只不过它生成的是 Go 代码而不是 C 代码)。输出文件还包括包含字节码的 .o 对象文件。
事实上,bpf2go 会生成两个版本的字节码 .o 文件,分别用于大端和小端架构。同时也会生成两个相应的 .go 文件,并在编译时使用目标平台的正确版本。例如,在 cilium/ebpf 的 kprobe 示例中,自动生成的文件是:
- 包含 eBPF 字节码的 bpf_bpfeb.o 和 bpf_bpfel.o ELF 文件
- bpf_bpfeb.go 和 bpf_bpfel.go 文件定义了与字节码中定义 的 map、程序和链接相对应的 Go 结构体和函数。
您可以将自动生成的 Go 代码中定义的对象与生成它的 C 代码联系起来。以下是该 kprobe 示例的 C 代码中定义的对象:
struct bpf_map_def SEC("maps") kprobe_map = {
...
};
SEC("kprobe/sys_execve")
int kprobe_execve() {
...
}
自动生成的 Go 代码包括代表所有 map 和程序的结构体(在本例中,map 和程序只有一个):
type bpfMaps struct {
KprobeMap *ebpf.Map `ebpf:"kprobe_map"`
}
type bpfPrograms struct {
KprobeExecve *ebpf.Program `ebpf:"kprobe_execve"`
}
KprobeMap 和 KprobeExecve 两个名称来自 C 代码中使用的 map 和程序名称。这些对象被组合到一个 bpfObjects 结构体中,代表加载到内核中的所有内容:
type bpfObjects struct {
bpfPrograms
bpfMaps
}
然后,您就可以在用户空间 Go 代码中使用这些对象定义和相关的自动生成函数。为了让您了解这可能涉及的内容,下面是基于同一 kprobe 示例中主函数的摘录(为简洁起见,省略了错误处理):
objs := bpfObjects{}
// 将以字节码形式嵌入的所有 BPF 对象加载到我刚才展示的由自动生成代码定义的 bpfObjects 中。
loadBpfObjects(&objs, nil)
defer objs.Close()
// 将程序附加到 sys_execve kprobe。
kp, _ := link.Kprobe("sys_execve", objs.KprobeExecve, nil)
defer kp.Close()
// 设置计时器,以便代码每秒轮询一次 map。
ticker := time.NewTicker(1 * time.Second)
defer ticker.Stop()
for range ticker.C {
var value uint64
// 从地图中读取一个项目。
objs.KprobeMap.Lookup(mapKey, &value)
log.Printf("%s called %d times\n", fn, value)
}
在 cilium/ebpf 目录中还有其他几个示例,您可以用来参考和启发。
Libbpfgo
Aqua Security 的 libbpfgo 项目在 libbpf 的 C 代码基础上实现了 Go 封装,提供了加载和附加程序的实用工具,并使用通道(channel)等 Go 本地特性来接收事件。由于它基于 libbpf 构建,因此支持 CORE。
下面是从 libbpfgo 的 README 中摘录的示例,它提供了一个很好的高层次视图,让我们了解这个库的功能:
// 从目标文件读取 eBPF 字节码。
bpfModule := bpf.NewModuleFromFile(bpfObjectPath)
// 将字节码加载到内核中。
bpfModule.BPFLoadObject()
// 操作 eBPF map 中的条目。
mymap, _ := bpfModule.GetMap("mymap")
mymap.Update(key, value)
// Go 程序员会喜欢在通道上接收来自环形缓冲区或 perf 缓冲区的数据,这是一种专为处理异步事件而设计的语言特性。
rb, _ := bpfModule.InitRingBuffer("events", eventsChannel, buffSize)
rb.Start()
e := <-eventsChannel
该库是为 Aqua 的 Tracee 安全项目创建的,也被其他项目所使用,如 Polar Signals 的 Parca,该项目提供基于 eBPF 的 CPU 性能分析。对于这个项目的方法,唯一的关注点是 libbpf C 代码和 Go 之间的 CGo 边界,这可能会导致性能和其他问题。(Dave Cheney 2016 年发表的文章“CGO 不是 Go”很好地概述了与 CGo 边界相关的问题。)
虽然近十年来 Go 一直是许多基础设施编码的既定语言,但最近越来越多的开发人员更喜欢使用 Rust。
Rust
Rust 越来越多地被用于构建基础架构工具。Rust 允许使用 C 语言的低级访问,但具有内存安全的额外优势。事实上,Linus Torvalds 已于 2022 年确认,Linux 内核本身将开始采用 Rust 代码,最近发布的 6.1 版本也已初步支持 Rust。
正如我在本章前面所讨论的,Rust 可以编译成 eBPF 字节码,这意味着(在正确的库支持下)可以用 Rust 编写 eBPF 工具的用户空间和内核代码。
Rust eBPF 开发有几个选项:libbpf-rs、Redbpf 和 Aya。
Libbpf-rs
Libbpf-rs 是 libbpf 项目的一部分,它为 libbpf C 代码提供了一个 Rust 封装,这样您就可以用 Rust 编写 eBPF 代码的用户空间部分。从该项目示例中可以看出,eBPF 程序本身是用 C 语言编写的。
提示
libbpf-bootstrap 项目中还有更多使用 Rust 语言的示例,如果您想尝试使用该 crate 构建自己的代码,这些示例可以帮助您快速入门。
这个 crate 有助于将 eBPF 程序整合到基于 Rust 的项目中,但它并不能满足许多人想用 Rust 编写内核代码的愿望。让我们看看其他一些能实现这一愿望的项目。
Redbpf
Redbpf 是一组与 libbpf 进行接口交互的 Rust crates,作为 foniod 的一部分开发,foniod 是一个基于 eBPF 的安全监控代理。
Redbpf 是在 Rust 能够编译为 eBPF 字节码之前开发的,因此它使用了多步编译过程,包括从 Rust 编译为 LLVM 位码(bitcode),然后使用 LLVM 工具链生成 ELF 格式的 eBPF 字节码。Redbpf 支持多种程序类型,包括 tracepoints、kprobes 和 uprobes、XDP、TC 以及一些套接字事件。
随着 Rust 编译器 rustc 获得了直接生成 eBPF 字节码的能力,一个名为 Aya 的项目利用了这一能力。在撰写本文时,根据 ebpf.io 上的社区网站,Aya 被认为是 "新兴 "项目,而 Redbpf 则被列为主要项目,但我个人的观点是,势头似乎正朝着 Aya 的方向发展。
Aya
Aya 是直接在 Rust 的系统调用级别构建的,所以它不依赖 libbpf(或者 BCC 或 LLVM 工具链)。但它确实支持 BTF 格式,与 libbpf 一样支持重定位(如第 5 章所述),因此它提供了与 CO-RE 相同的能力,一次编译即可在其他内核上运行。在撰写本文时,它比 Redbpf 支持更广泛的 eBPF 程序类型,包括跟踪/perf 相关事件、XDP 和 TC、cgroups 和 LSM 附加。
正如我提到的,Rust 编译器也支持编译成 eBPF 字节码,因此这种语言可用于内核和用户空间的 eBPF 编程。
提示
在 Rust 中可以原生编写内核和用户空间代码,而无需中间依赖 LLVM,这吸引了 Rust 程序员们的目光。GitHub 上有一个关于 lockc 项目(基于 eBPF 的项目,使用 LSM 钩子增强容器工作负载的安全性)开发者为何决定将其项目从 libbpf-rs 移植到 Aya 的有趣讨论。
该项目包含 aya-tool,一个实用工具,用于生成与内核数据结构匹配的 Rust 结构定义,这样您就不必自己编写它们。
Aya 项目非常强调开发者体验,让新人能够轻松上手。考虑到这一点,“Aya book”是一本非常可读的介绍,其中包含一些很好的示例代码,并附有有用的解释注释。
为了让您简单了解 Rust 中的 eBPF 代码,下面摘录了 Aya 允许所有流量的基本 XDP 示例:
#![allow(unused)] fn main() { // 这一行定义了节名称,相当于 C 中的 SEC("xdp/myapp")。 #[xdp(name="myapp")] pub fn myapp(ctx: XdpContext) -> u32 { // 名为 myapp 的 eBPF 程序会调用 try_myapp 函数来处理 XDP 收到的网络数据包。 match unsafe { try_myapp(ctx) } { Ok(ret) => ret, Err(_) => xdp_action::XDP_ABORTED, } } // try_myapp 函数记录接收到数据包的事实,并始终返回 XDP_PASS 值,告诉内核照常处理数据包。 unsafe fn try_myapp(ctx: XdpContext) -> Result<u32, u32> { info!(&ctx, "received a packet"); Ok(xdp_action::XDP_PASS) } }
正如我们在本书中看到的基于 C 语言的例子一样,eBPF 程序被编译成 ELF 对象文件。不同的是,Aya 使用 Rust 编译器而不是 Clang 来创建该文件。
Aya 还为将 eBPF 程序加载到内核并附加到事件的用户空间活动生成了代码。下面是同一基本示例中用户空间方面的几行关键代码:
#![allow(unused)] fn main() { // 从编译器生成的 ELF 目标文件中读取 eBPF 字节码。 let mut bpf = Bpf::load(include_bytes_aligned!( "../../target/bpfel-unknown-none/release/myapp" ))?; // 在字节码中找到名为 myapp 的程序。 let program: &mut Xdp = bpf.program_mut("myapp").unwrap().try_into()?; // 将其加载到内核中。 program.load()?; // 将其附加到指定网络接口上的 XDP 事件。 program.attach(&opt.iface, XdpFlags::default()) }
如果您是一名 Rust 程序员,我强烈建议您更详细地了解 "Aya book"中的其他示例。Kong 也发表了一篇不错的博文,介绍如何使用 Aya 编写 XDP 负载均衡器。
提示
Aya 维护者 Dave Tucker 和 Alessandro Decina 与我一起参加了“eBPF 和 Cilium Office Hours”直播的第 25 集,他们在其中演示并介绍了 Aya 的 eBPF 编程。
Rust-bcc
Rust-bcc 模仿 BCC 项目 Python 绑定提供了的 Rust 绑定,以及一些 BCC 跟踪工具的 Rust 实现。
测试 BPF 程序
有一条 bpf() 命令 BPF_PROG_RUN,允许从用户空间运行 eBPF 程序进行测试。
BPF_PROG_RUN(目前)仅适用于 BPF 程序类型的一个子集,这些子集大多与网络有关。
您还可以通过一些内置的统计信息来了解 eBPF 程序的性能。运行以下命令启用它:
$ sysctl -w kernel.bpf_stats_enabled=1
这将在 bpftool 的输出中显示有关程序的额外信息,如下所示:
$ bpftool prog list
...
2179: raw_tracepoint name raw_tp_exec tag 7f6d182e48b7ed38 gpl
# 下一行是粗体
run_time_ns 316876 run_cnt 4
loaded_at 2023-01-09T11:07:31+0000 uid 0
xlated 216B jited 264B memlock 4096B map_ids 780,777
btf_id 953
pids hello(19173)
额外的统计数据以粗体显示,这里显示该程序运行了四次,总共花费了大约 300 微秒。
提示
从 Quentin Monnet 在 FOSDEM 2020 上发表的题为 "调试 BPF 程序的工具和机制" 的演讲中了解更多信息。
多个 eBPF 程序
eBPF 程序是附加到内核事件的函数。许多应用程序需要跟踪多个事件来实现其目标。我在本章初期介绍过 bpftrace 版本,您会看到它将 BPF 程序附加到四个不同的系统调用跟踪点上:
syscall_enter_opensyscall_exit_opensyscall_enter_openatsyscall_exit_openat
这些是内核处理 open() 和 openat() 系统调用的入口点和出口点。这两个系统调用可用于打开文件,opensnoop 工具会跟踪这两个系统调用。
但为什么需要同时跟踪这些系统调用的入口和出口呢?使用入口点是因为系统调用参数在入口点可用,这些参数包括文件名和传递给 open[at] 系统调用的任何标志(flag)。但在这个阶段,要知道文件是否会被成功打开还为时过早。这就解释了为什么有必要在退出点也附加 eBPF 程序。
如果您看一下 libbpf-tools 版本的 opensnoop,就会发现只有一个用户空间程序,它会将所有四个 eBPF 程序加载到内核中,并将它们附加到各自的事件中。eBPF 程序本身基本上是独立的,但它们使用 eBPF map 来相互协调。
一个复杂的应用程序可能需要在很长一段时间内动态地添加和移除 eBPF 程序。对于任何给定的应用程序,甚至可能没有固定数量的 eBPF 程序。例如,Cilium 将 eBPF 程序附加到每个虚拟网络接口,在 Kubernetes 环境中,这些接口会随着正在运行的 Pod 数量的变化而动态增减。
本章中的大多数库都会自动处理多种 eBPF 程序。例如,libbpf 和 ebpf-go 生成框架代码,通过一次函数调用,就可从对象文件或缓冲区读入字节码,加载所有程序和 map。它们还能生成更细粒度的函数,以便您可以单独操作程序和 map。
总结
绝大多数使用基于 eBPF 的工具的人都不需要自己编写 eBPF 代码,但如果您确实发现自己想要自己实现一些东西,您有很多选择。这是一个不断变化的领域,所以当您读到这篇文章时,很有可能已经有了新的语言库和框架,或者大家已经对我在本章中强调的某些库达成了共识。您可以在 ebpf.io 重要项目列表的基础设施页面找到围绕 eBPF 的主要语言项目的最新列表。
要快速收集跟踪信息,bpftrace 是一个非常有价值的选项。
为了获得更大的灵活性和控制力,如果您熟悉 Python,并且不关心运行时发生的编译步骤,BCC 是构建 eBPF 工具的快速方法。
如果您编写的 eBPF 代码需要在不同内核版本之间广泛分发和移植,那么您可能需要利用 CO-RE。在撰写本文时,支持 CO-RE 的用户空间框架包括 C 语言的 libbpf、Go 语言的 cilium/ebpf 和 libbpfgo 以及 Rust 语言的 Aya。
如需更多建议,我强烈建议您加入 eBPF Slack 并在那里讨论您的问题。您可能会在该社区中找到许多这些语言库的维护者。
练习
如果您想尝试本章讨论的一个或多个库,"Hello World" 总是一个很好的开始:
- 使用您选择的一个或多个库,编写一个 "Hello World" 示例程序,输出一条简单的跟踪信息。
- 使用
llvm-objdump将生成的字节码与第 3 章中的 "Hello World" 示例进行比较。您会发现很多相似之处! - 正如第 4 章所述,可以使用
strace -e bpf来查看何时进行bpf()系统调用。在您的 "Hello World" 程序上试试看,看看它的行为是否符合您的预期。
第十一章 eBPF 的未来演变
eBPF 尚未完成!与大多数软件一样,它在 Linux 内核中也在不断开发中,而且还在不断被添加到 Windows 操作系统中。在本章中,我们将探讨这项技术未来可能的发展方向。
自从 BPF 在 Linux 内核中引入以来,它已经发展成为一个拥有自己邮件列表和维护者的子系统。(向 Meta 公司的 Alexei Starovoitov 和 Andrii Nakryiko 以及 Isovalent 公司的 Daniel Borkmann 致敬,他们负责维护 Linux 内核中的 BPF 子树。)随着 eBPF 的普及和兴趣扩展到 Linux 内核社区之外,创建一个中立的机构来协调各方的合作变得很有意义。这个机构就是 eBPF 基金会。
eBPF 基金会
eBPF 基金会由 Google、Isovalent、Meta(当时称为 Facebook)、微软和 Netflix 于 2021 年在 Linux 基金会的支持下成立。该基金会作为一个中立机构,可以持有资金和知识产权,以便各个商业公司可以相互合作。
其目的不是要改变 Linux 内核社区和 Linux BPF 子系统贡献者开发 eBPF 技术的方式。基金会的活动由 BPF 指导委员会指导,该委员会完全由构建该技术的技术专家组成,包括 Linux 内核 BPF 维护者和其他核心 eBPF 项目的代表。
eBPF 基金会专注于 eBPF 作为技术平台以及支持 eBPF 开发的生态系统的发展。那些构建在 eBPF 之上并寻求中立管理机构的项目可能会在其他基金会中找到更合适的归属。例如,Cilium、Pixie 和 Falco 都是云原生计算基金会(CNCF)的一部分,这是有道理的,因为它们都旨在在云原生环境中使用。
除了现有的 Linux 维护者之外,这种合作的关键驱动力之一是 Microsoft 对在 Windows 操作系统中开发 eBPF 的兴趣。这就需要定义 eBPF 标准(Dave Thaler 在 Linux Plumbers Conference 上介绍了这项标准化工作的现状),以便为一种操作系统编写的程序可以在另一种操作系统上使用。这项工作是在 eBPF 基金会的赞助下完成的。
支持 Windows 的 eBPF
Microsoft 支持 Windows 的 eBPF 的工作正在顺利进行。当我在 2022 年最后几个月写这篇文章时,已经有功能演示展示了在 Windows 上运行的 Cilium Layer 4 负载均衡和基于 eBPF 的连接跟踪。
我之前提到过,eBPF 编程是内核编程,乍看起来,一个在 Linux 内核中运行并且可以访问 Linux 内核数据结构的程序,在其他完全不同的操作系统中也能运行可能会让人感到不直观。但实际上,在实践中,特别是涉及到网络编程时,所有操作系统之间会有很多共同之处。无论是在 Windows 还是 Linux 机器上创建的网络数据包,其结构是相同的,而且网络栈的各层需要以相同的方式进行处理。
您还会记得,eBPF 程序由一组字节码指令组成,这些指令由内核中的虚拟机(VM)处理。虚拟机也可以在 Windows 中实现!
图 11-1 显示了支持 Windows 的 eBPF 的架构概览,摘自该项目的 GitHub 仓库。从图中可以看出,Windows 版 eBPF 重用了现有 eBPF 生态系统中的一些开源组件,如 libbpf 和 Clang 中用于生成 eBPF 字节码的支持。Linux 内核是以 GPL 许可的,而 Windows 是专有的,因此 Windows 项目不能重用 Linux 内核实现校验器的任何部分。(非要这样做也可以,但这样做需要微软同时发布 GPL 许可证下的 Windows 源代码)相反,它使用了 PREVAIL 校验器和 uBPF JIT 编译器(两者都是许可授权的,因此可以被更广泛的项目和组织使用)。
图 11-1. 适用于 Windows 的 eBPF 架构概览,改编自 https://github.com/microsoft/ebpf-for-windows#architectural-overview
一个有趣的区别是,eBPF 代码是在用户空间的 Windows 安全环境中进行验证和 JIT 编译的,而不是在内核中(图 11-1 中内核中的 uBPF 解释器仅用于调试构建,不用于生产环境)。
期望每个在 Linux 上编写的 eBPF 程序都能在 Windows 上运行是不现实的。但这与让 eBPF 程序在不同版本的 Linux 内核上运行所面临的挑战并无太大区别:即使支持 CO-RE,内核的内部数据结构也可能发生变化,不同版本之间也可能添加或删除数据结构。eBPF 程序员的工作就是优雅地处理这些可能性。
说到 Linux 内核的变化,未来几年我们预计 eBPF 会发生哪些变化?
Linux eBPF 演变
自 3.15 以来,eBPF 的功能几乎与内核的每个版本同步发展。如果您想知道任何特定版本都有哪些功能,BCC 项目会提供一份有用的列表。当然,我也期待未来几年会有更多新功能加入。
预测即将发生的事情的最好方法就是倾听正在研究的人的意见。例如,在 2022 年 Linux Plumbers 大会上,eBPF 维护者 Alexei Starovoitov 发表了演讲,讨论了他期望看到 eBPF 程序使用的 C 语言如何发展。(Alexei Starovoitov 在此视频中讨论了 BPF 从受限 C 语言到扩展且安全的 C 语言的历程)我们已经看到 eBPF 从支持几千条指令发展到几乎无限的复杂性,并增加了对循环的支持和不断增加的 BPF 辅助函数集。随着附加功能被添加到所支持的 C 中,并且在验证器的支持下,eBPF C 语言可以发展到具有开发内核模块的所有灵活性,但又具有 eBPF 的安全性和动态加载特性。
正在讨论和开发的 eBPF 新特性和新功能的其他一些想法包括:
- 签名的 eBPF 程序
- 软件供应链安全是过去几年的热门话题,其中一个关键要素是能够验证您打算运行的程序是否来自预期的来源,并且没有被篡改。一种通常的实现方式是验证伴随程序的加密签名。您可能认为内核可以在 eBPF 程序的验证步骤中执行此操作,但不幸的是,这并不简单!正如您在本书中看到的,用户空间加载器会动态地调整程序,包含有关 map 位置和 CO-RE 相关信息,从签名的角度来看,这很难与恶意修改区分开来。这是 eBPF 社区急于找到解决方案的一个问题。
- 长效内核指针
- eBPF 程序可以使用辅助函数或 kfunc 获取内核对象的指针,但指针仅在程序执行期间有效。指针不能存储在 map 中供以后检索。支持类型化指针(typed pointer support)的想法将使这一领域更具灵活性。
- 内存分配
- 对于 eBPF 程序来说,简单地调用内存分配函数(如
kmalloc())并不安全,但有一项建议提出了一种 eBPF 专用的替代方法。
- 对于 eBPF 程序来说,简单地调用内存分配函数(如
您什么时候能够利用新出现的 eBPF 功能?作为终端用户,您能够利用的功能取决于您在生产中运行的内核版本,正如我在第 1 章中讨论的那样,内核版本可能需要几年的时间才能成为 Linux 的稳定发行版。作为个人,您可能会选择最新版本的内核,但绝大多数运行服务器部署的组织都使用稳定的、受支持的版本。 eBPF 程序员必须考虑到,如果他们编写的代码利用了内核中添加的最新功能,那么这些功能在未来几年内不太可能在大多数生产环境中使用。一些组织可能有足够紧迫的需求,值得更快地推出新的内核版本,以便尽早采用新的 eBPF 功能。
例如,在另一场关于构建未来网络的前瞻性演讲中,Daniel Borkmann 讨论了一项名为 Big TCP 的功能。该功能在 Linux 5.19 版本中加入,通过在内核中批量处理网络数据包,使网络速度达到 100 GBit/s(甚至更快)。大多数 Linux 发行版在几年内都不会支持这么新的内核,但对于处理大量网络流量的专业机构来说,也许值得尽早升级。今天在 eBPF 和 Cilium 中添加 Big TCP 支持意味着大规模用户可以使用它,尽管我们大多数人暂时还无法启用它。
由于 eBPF 允许动态调整内核代码,因此我们有理由期待它被用于解决 "现场" 问题。在第 9 章中,您了解到如何使用 eBPF 来减少内核漏洞;此外,使用 eBPF 来帮助支持硬件设备(如鼠标、键盘和游戏控制器等人机接口设备)的工作也在进行中。这项工作是在现有支持的基础上进行的
eBPF 是一个平台,而不是一个特性
大约十年前,最热门的新技术是容器,似乎每个人都在谈论容器是什么以及容器会带来哪些优势。如今,eBPF 也处于类似的阶段,大量的会议演讲和博文——我在本书中提到过其中的几篇,都在夸大 eBPF 的好处。如今,容器已成为许多开发人员日常生活的一部分,无论是使用 Docker 或其他容器运行时在本地运行代码,还是将代码部署到 Kubernetes 环境中。eBPF 是否也会成为每个人的常规工具包的一部分?
我相信答案是否定的——或者至少不是直接的。大多数用户不会直接编写 eBPF 程序或使用 bpftool 等实用程序手动操作它们。但他们会定期与使用 eBPF 构建的工具进行交互,无论是性能测量、调试、网络、安全、跟踪,还是尚未使用 eBPF 实现的大量其他功能。用户可能不知道他们正在使用 eBPF,就像他们可能不知道当他们使用容器时,他们正在使用命名空间和 cgroup 等内核功能一样。
如今,了解 eBPF 的项目和供应商都在强调他们对 eBPF 的使用,因为 eBPF 功能强大、优势众多。随着基于 eBPF 的项目和产品获得越来越多的关注和市场份额,eBPF 正在成为基础架构工具的默认技术平台。
eBPF 编程知识现在是并将继续是一种广受欢迎但相对稀有的技能,就像当今的内核开发比开发业务应用程序或游戏要少得多一样。如果您喜欢深入研究较低级别的系统并希望构建必要的基础设施工具,那么 eBPF 技能将为您提供很好的帮助。我希望这本书对您的 eBPF 之旅有所帮助!
进一步阅读
在本书中,我提供了具体文章和文档页面的参考资料。下面列出了一些其他资源,希望对您的 eBPF 之旅有所帮助:
- eBPF 社区网站 ebpf.io
- Cilium 文档中的 BPF 和 XDP 参考资料
- 关于 BPF 的 Linux 内核文档
- 关于使用 eBPF 进行性能评估和可观察性的Brendan Gregg 网站
- Andrii Nakryiko 的网站,特别是有关 CO-RE 和 libbpf 的更多信息
- Lwn.net,一个很棒的关于 Linux 内核更新的资源,包括 BPF 子系统
- Elixir.bootlin.com,您可以在其中浏览 Linux 源代码
- eCHO,每周一次的现场直播,涉及 eBPF 和 Cilium 社区的各种主题(本文作者是该直播的定期演讲者)。
结论
恭喜您完成了这本书!
我希望通过阅读《学习 eBPF》这本书,您能深入了解 eBPF 的强大功能。也许它能激励您自己编写 eBPF 代码,或者尝试使用我讨论过的一些工具。如果您已经决定进行一些 eBPF 编程,我希望这本书能让您对如何开始有一些信心。如果您在阅读本书的过程中完成了练习,那就太棒了!
如果您对 eBPF 感兴趣,有很多方法可以让您参与到社区中来。最好的起点是 ebpf.io 网站。这将为您提供最新的新闻、项目、活动和事件,同时还提供了 eBPF Slack 频道,在这里您可以找到具有专业知识的人回答您的任何问题。
欢迎您对本文提出反馈、评论和任何修改意见。您可以通过本书附带的 GitHub 存储库提供意见:github.com/lizrice/learning-ebpf。我也很乐意直接听取您的意见。您可以在互联网上的许多地方通过 @lizrice 找到我。